
Weize Xu
70 posts

Weize Xu
@Nanguage
Postdoc Scholar @Stanford BASE, Genetics | Build AI agent system for life science/biomedicine(PantheonOS: https://t.co/pdpUJ0jfMB)
Palo Alto, CA Beigetreten Ağustos 2015
980 Folgt241 Follower

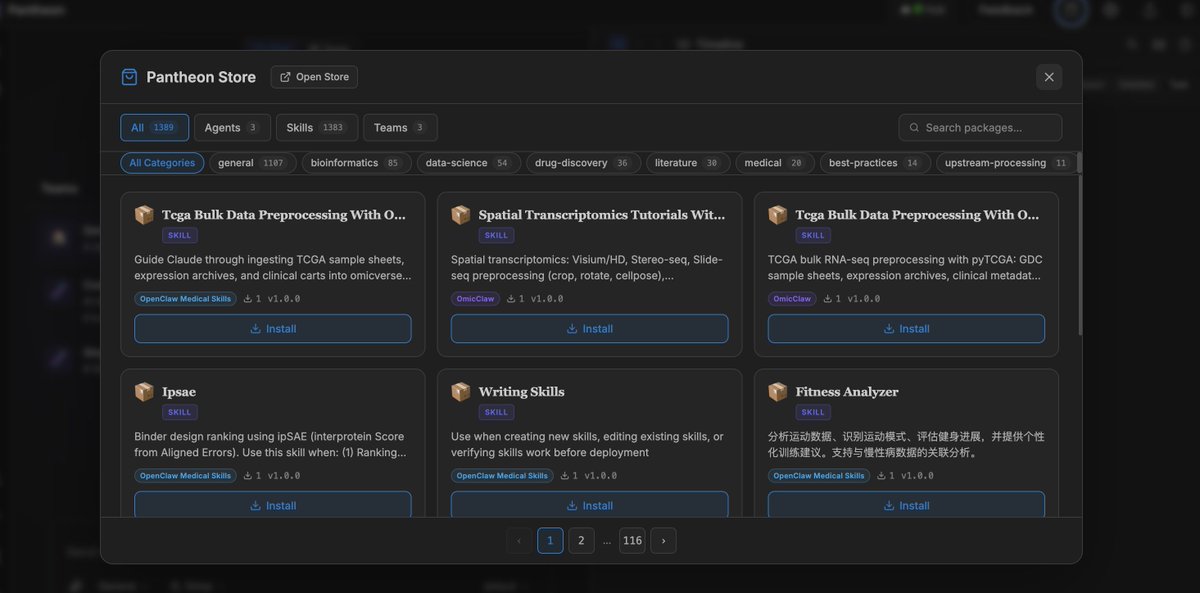
Pantheon AI Agent Store is now live with 1300 biomedical Skills and more!
Pantheon Store is a new marketplace for biomedical AI Agents, Teams, and Skills. We launch the Store with 1300+ curated bio/medical AI capabilities, built by the incredible builders behind Claude Scientific Skills, ClawBio, OpenClaw Medical Skills, LabClaw, and PantheonOS ecosystem.
You can install instantly in PantheonOS (UI or CLI) and build powerful scientific workflows right now.
What you can do with Pantheon Store? It can:
• Discover Agents, Teams, and Skills for genomics (especially single-cell and spatial genomics), pharmacology, medicine, and bioinformatics
• Install Skills seamlessly into your existing workflows
• Share your own Agents, Teams, and Skills with the community
Thus, Pantheon-Store turns PantheonOS into a living ecosystem for scientific AI tools.
We welcome you join the community! Upload your own components. Build together. Accelerate biomedical discovery!

English
Explore our store here: app.pantheonos.stanford.edu/#/store
And also the manuscript and platform:
🔗 biorxiv.org/content/10.648…
🔗 pantheonos.stanford.edu
English
I believe this is an important update, and I hope to build Pantheon-Store into a vibrant Biomedical AI community!🔥
evo-devo@Xiaojie_Qiu
Pantheon AI Agent Store is now live with 1300 biomedical Skills and more! Pantheon Store is a new marketplace for biomedical AI Agents, Teams, and Skills. We launch the Store with 1300+ curated bio/medical AI capabilities, built by the incredible builders behind Claude Scientific Skills, ClawBio, OpenClaw Medical Skills, LabClaw, and PantheonOS ecosystem. You can install instantly in PantheonOS (UI or CLI) and build powerful scientific workflows right now. What you can do with Pantheon Store? It can: • Discover Agents, Teams, and Skills for genomics (especially single-cell and spatial genomics), pharmacology, medicine, and bioinformatics • Install Skills seamlessly into your existing workflows • Share your own Agents, Teams, and Skills with the community Thus, Pantheon-Store turns PantheonOS into a living ecosystem for scientific AI tools. We welcome you join the community! Upload your own components. Build together. Accelerate biomedical discovery!
English
@LuZhang17593753 😎 Thanks! Welcome to try the Store and upload your components!
English
Weize Xu retweetet

PantheonOS: An Evolvable Multi-Agent Framework for Automatic Genomics Discovery biorxiv.org/content/10.648…



English
Weize Xu retweetet
We are thrilled to share our preprint (tinyurl.com/3mtbtcwu) on PantheonOS, the first evolvable, privacy-preserving multi-agent operating system for automatic genomics discovery.
📄 Preprint: tinyurl.com/3mtbtcwu
🤖 Open-source App (free to all users): app.pantheonos.stanford.edu
🌐 More: pantheonos.stanford.edu
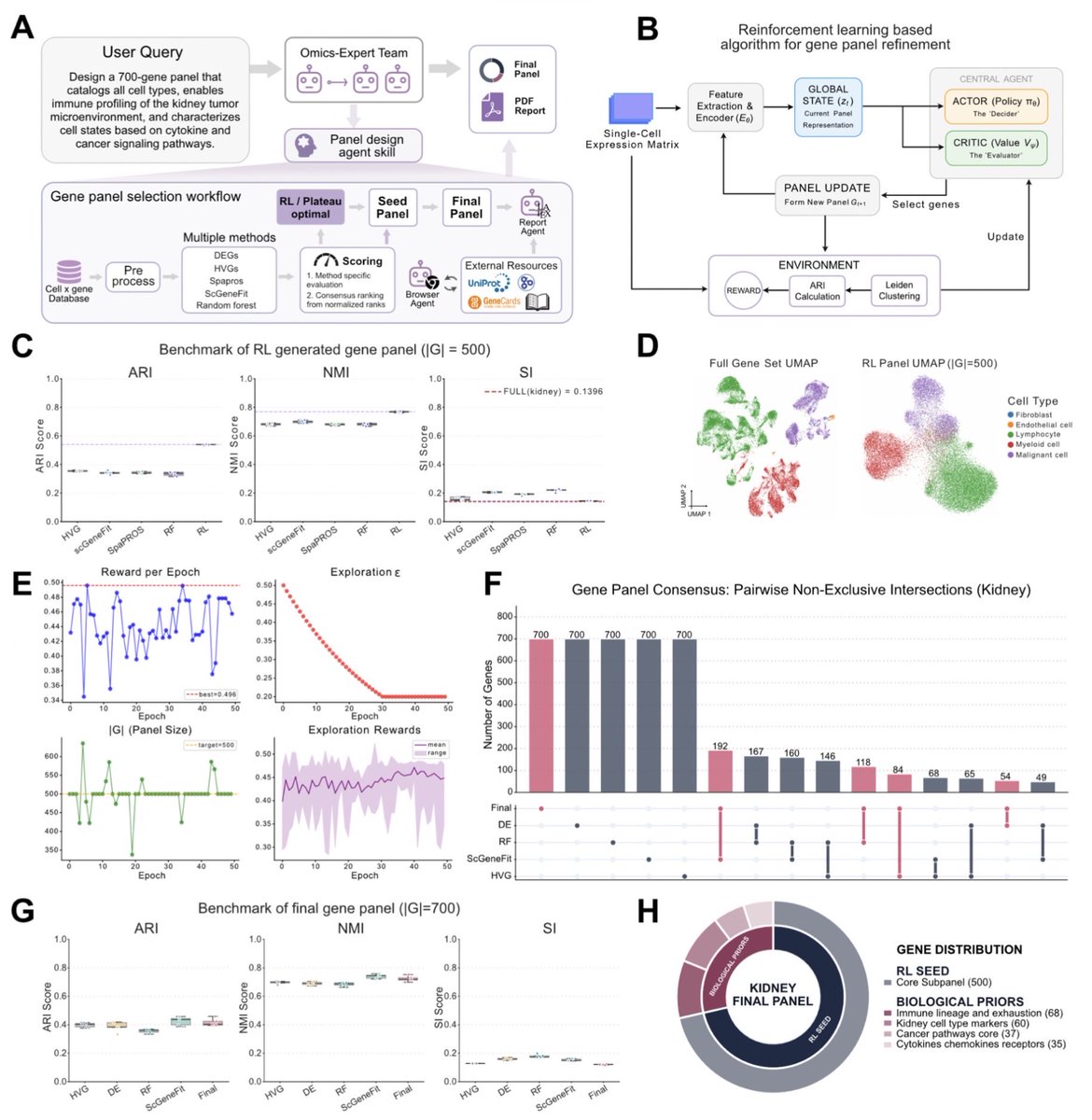
PantheonOS unites LLM-powered agents, reinforcement learning, and agentic code evolution to push beyond routine analysis — evolving state-of-the-art algorithms to super-human performance.
🧬 Evolved batch correction (Harmony, Scanorama, BBKNN) and Reinforcement learning or RL agumented algorithms
🧠 RL–augmented gene panel design
🧭 Intelligent routing across 22+ virtual cell foundation models
🧫 Autonomous discovery from newly generated 3D early mouse embryo data
🫀 Integrated human fetal heart multi-omics with 3D whole-heart spatial data
From uncovering asymmetric Cer1–Nodal inhibition in early mouse embryos to mapping spatial disease programs in the human heart, PantheonOS demonstrates a future where AI agents don’t just analyze biology — they drive discovery.
This is a step toward self-evolving AI systems that accelerate science itself and push human civilization toward the singularity.
This work is built over 2 years by an incredible team (Weize @Nanguage who led this project, and also to Erwin, Zhongquan @BAKEZQ, Chris @chriswzou , Zehua @starlitnightly, Yifan @YifanLu2024 , Xuehai, Zhongquan, and Miao, Cinlong's wetlab support and the entire Qiu lab. We are grateful for all our funders and industrial collaborators: @Lenovo @vizgen_inc
We are excited to scale this work further and welcome philanthropic, industrial, and venture support. We invite the community (pantheonos.stanford.edu/ecosystem) to contribute, extend, and collectively reimagine the future of automated biological discovery.
🌐 More details below:
English

@Nanguage @GenomeBiology Big congratulations on this amazing work! Absolutely fantastic!
English
U-FISH was finally published in Genome Biology(@GenomeBiology )! 🥳U-FISH is a universal FISH, imaging-based spatial omics image spot detector. Trained on a rich dataset, it achieves SOTA-level accuracy and can work across different types of microscopy images without fine-tuning. The network architecture has been highly optimized, with model weights of just over 600 KB, enabling very efficient execution across various computing environments (CPU, GPU, and even in the browser). In the paper, we demonstrate its applications in spatial transcriptomics decoding and clinical DNA FISH diagnostics.

English
All code datasets have been open-sourced👇:
GitHub repo: github.com/UFISH-Team/U-F…
HuggingFace Dataset: huggingface.co/datasets/GangC…
Web app: ufish-team.github.io
Chatbot plugin: ufish-team.github.io/#/chatbot
Napari: napari-hub.org/plugins/napari…
English
U-FISH has strong generalization capabilities: with minimal fine-tuning, it can be applied to signal spot detection tasks beyond FISH images, such as CISH spot detection and Hi-C loop detection. To make it easy to use, we developed a Napari plugin, a web application, and a @bioimageio Chatbot plugin, allowing users to complete analyses through simple dialogue. To foster community development, our software and datasets are fully open-source—everyone is welcome to try them out!
Paper: genomebiology.biomedcentral.com/articles/10.11…
English
Weize Xu retweetet
Exciting update on PantheonOS: Introducing Pantheon-Notebook & Pantheon-CLI — the first fully open-source, Python-based agentic tools that go beyond Claude Code in the field of data analysis.
Pantheon-CLI runs entirely on your computer or server, supports 60+ tools and 50+ databases, and can call any Python, R, or Julia package alongside natural language. Chat with your data directly. It look like python-claude-code, but more appreciate for data analysis.
Pantheon-Notebook brings the same agentic framework into Jupyter! Not just for writing code, it can also run and revise code automatically to generate the correct result, and even operate on files and study from website — beyond what any other tool can do!
With Pantheon, you mix natural language + programming in one workflow, focusing on discovery instead of syntax barriers.
We've applied Pantheon in some real-world cases: finance (customer explore), biology (Seurat, cell segmentation, annotation), sociology (survey analysis), and drug discovery (molecular docking).
Pantheon is not just a CLI or a plugin — it's an agentic operating system for science, spanning both terminal and notebook. Why not try it now?
We are actively preparing publications from this series of projects. Major contributors will be recognized in our GitHub repository and listed as key authors in these manuscripts. Feel free to reach out for collaborations, research assistant positions, visiting opportunities, rotation project or future PhD projects.
English

🎉Grateful shoutout to Zehua(@starlitnightly) for the incredible work on Pantheon-CLI and to Xiaojie(@Xiaojie_Qiu) for the steadfast support! Try Pantheon-CLI and share feedback—we’re building in the open. Next up: Pantheon-Lab (web) and our distributed agent framework, PantheonOS. Stay tuned!✨
evo-devo@Xiaojie_Qiu
🚀 Introducing PantheonOS (pantheonOS.stanford.edu): A Fully Open-Source Agent OS for Science PantheonOS began as a research project in my Stanford lab and has since evolved into a vision to redefine data science in the era of AI—starting with computational biology, especially single-cell and spatial genomics. PantheonOS is a general agent platform built from the ground up. It is arguably the first distributed agent framework designed for scientific data analysis. 🔑 Key Features 1. Multi-Agent Collaboration – Built-in paradigms for distributed, cross-machine cooperation among agents and toolsets. 2. Native Toolset Support – Python, R, Julia, LaTeX, and more—designed for real scientific workflows. 3. Modular & Extensible – Developer-friendly design with shallow wrappers, plus LLM-driven toolset generation. 4. Evolvable Agents – Capable of evolving large-scale code projects to achieve superhuman performance (e.g., evolving upon the original Harmony [I Korsunsky, 2019, Nature Biotechnology] and Scanorama [BL Hie, 2019, Nature Biotechnology] implementations), and even evolving the system itself to adapt to new fields. 🎉 Stepwise Release Strategy We’re releasing PantheonOS in stages: Pantheon-CLI (today!), followed by Pantheon-Lab, Pantheon-Notebook, Pantheon-Slack, and more. 🌟 Pantheon-CLI Highlights - We're not just building another CLI tool. We're defining how scientists will interact with data in the AI era. - Open, Powerful, Python-First – The first fully open-source, endlessly extendable scientific “vibe analysis” framework. - Mixed Programming Magic – Combine Python, natural language, R, or Julia—seamlessly in the same environment. - PhD-Level Assistant – A command-line agent for complex real-world genomics and beyond, handling workflows at the PhD level. - Privacy by Design – Run entirely offline with local LLMs—your data never leaves your computer. ✅ Proven Applications (10 Demonstrations) Computational biology: 1. ATAC-seq: From raw reads to peak matrix 2. RNA-seq: From raw reads to expression matrix 3. Complex single-cell workflows (PhD-level) 4. Hybrid natural language + R for Seurat annotation 5. Learning from web tutorials + invoking single-cell foundation models 6. Cell segmentation on 10x Genomics HD Visium data And beyond: 7. Mixed Python & R programming examples 8. Molecular docking & structural analysis 9. Exploratory factor analysis for behavioral survey data 10. Customer segmentation & finance analytics 🌐 Learn More & Get Started Website: pantheonOS.stanford.edu Pantheon-CLI Documentation: pantheon-cli-docs.netlify.app GitHub Repo: github.com/aristoteleo/pa… 💬 Join our community: PantheonOS Slack: pantheonos.slack.com/ssb/redirect PantheonOS Discord: discord.com/invite/74yzAGYW
English
Weize Xu retweetet

Ever imagined running Seurat with natural language and exploring your data step by step? No code
This Pantheon-CLI case study shows a full single-cell workflow—normalization, clustering, QC, marker detection, and cell type mapping—all through conversation. youtube.com/watch?v=z407b9…
YouTube
English
Weize Xu retweetet
🚀 Introducing PantheonOS (pantheonOS.stanford.edu): A Fully Open-Source Agent OS for Science
PantheonOS began as a research project in my Stanford lab and has since evolved into a vision to redefine data science in the era of AI—starting with computational biology, especially single-cell and spatial genomics.
PantheonOS is a general agent platform built from the ground up. It is arguably the first distributed agent framework designed for scientific data analysis.
🔑 Key Features
1. Multi-Agent Collaboration – Built-in paradigms for distributed, cross-machine cooperation among agents and toolsets.
2. Native Toolset Support – Python, R, Julia, LaTeX, and more—designed for real scientific workflows.
3. Modular & Extensible – Developer-friendly design with shallow wrappers, plus LLM-driven toolset generation.
4. Evolvable Agents – Capable of evolving large-scale code projects to achieve superhuman performance (e.g., evolving upon the original Harmony [I Korsunsky, 2019, Nature Biotechnology] and Scanorama [BL Hie, 2019, Nature Biotechnology] implementations), and even evolving the system itself to adapt to new fields.
🎉 Stepwise Release Strategy
We’re releasing PantheonOS in stages: Pantheon-CLI (today!), followed by Pantheon-Lab, Pantheon-Notebook, Pantheon-Slack, and more.
🌟 Pantheon-CLI Highlights
- We're not just building another CLI tool. We're defining how scientists will interact with data in the AI era.
- Open, Powerful, Python-First – The first fully open-source, endlessly extendable scientific “vibe analysis” framework.
- Mixed Programming Magic – Combine Python, natural language, R, or Julia—seamlessly in the same environment.
- PhD-Level Assistant – A command-line agent for complex real-world genomics and beyond, handling workflows at the PhD level.
- Privacy by Design – Run entirely offline with local LLMs—your data never leaves your computer.
✅ Proven Applications (10 Demonstrations)
Computational biology:
1. ATAC-seq: From raw reads to peak matrix
2. RNA-seq: From raw reads to expression matrix
3. Complex single-cell workflows (PhD-level)
4. Hybrid natural language + R for Seurat annotation
5. Learning from web tutorials + invoking single-cell foundation models
6. Cell segmentation on 10x Genomics HD Visium data
And beyond:
7. Mixed Python & R programming examples
8. Molecular docking & structural analysis
9. Exploratory factor analysis for behavioral survey data
10. Customer segmentation & finance analytics
🌐 Learn More & Get Started
Website: pantheonOS.stanford.edu Pantheon-CLI Documentation: pantheon-cli-docs.netlify.app GitHub Repo: github.com/aristoteleo/pa…
💬 Join our community:
PantheonOS Slack: pantheonos.slack.com/ssb/redirect
PantheonOS Discord: discord.com/invite/74yzAGYW
English
Weize Xu retweetet

🚨 New to single-cell analysis? Still stuck in a trial-and-error loop?
🚨 Already experienced? Your “optimal” preprocessing pipeline might not actually be optimal.
🚨 Relying on a BioAgent? It likely runs standard procedures that are broadly accepted — but not truly optimal for your dataset or downstream task.
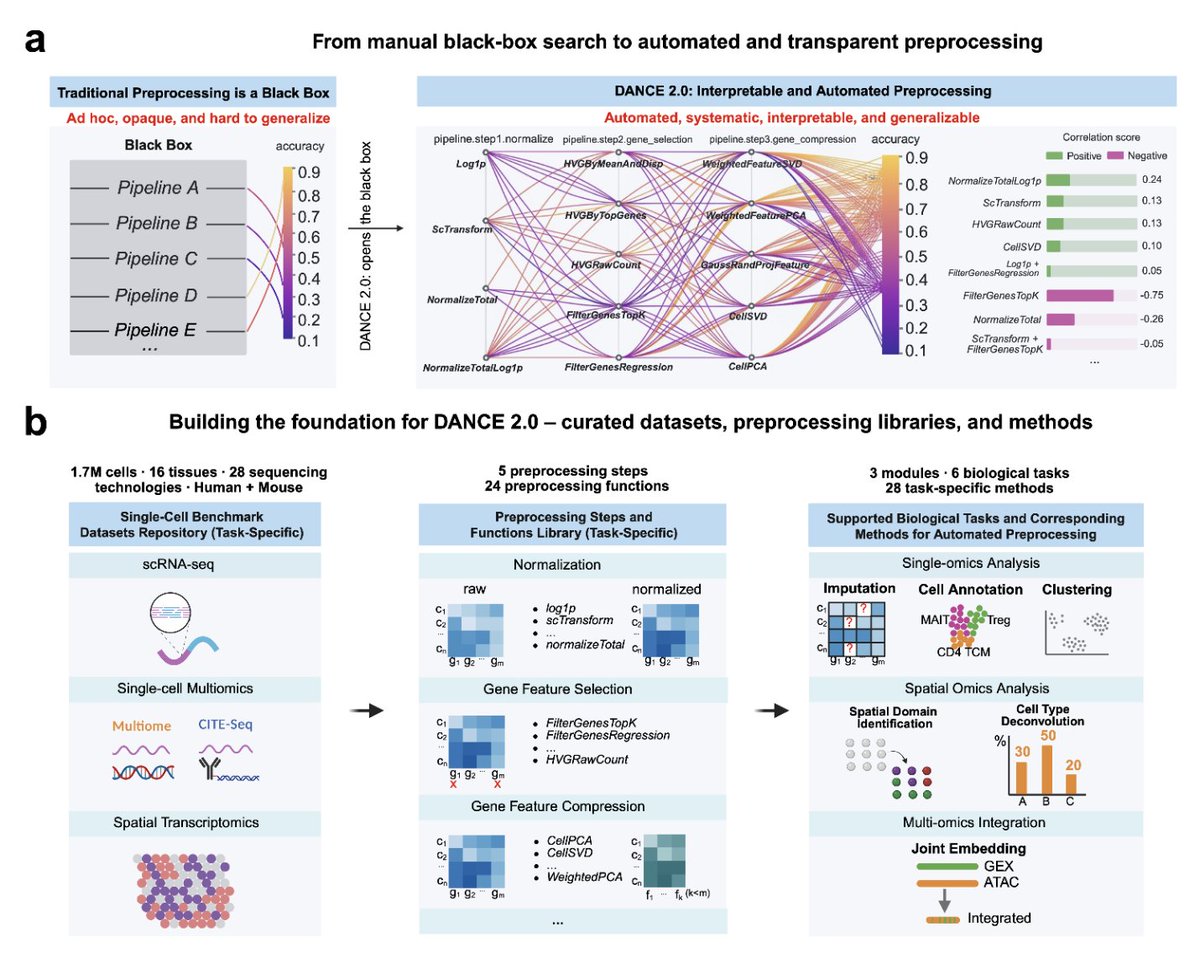
No matter where you are — 💡DANCE 2.0 is here for you. We turn single-cell preprocessing from a trial-and-error guessing game into a systematic, data-driven, and interpretable workflow.
🔍 Highlights of DANCE 2.0:
1. Overview
DANCE 2.0 automatically searches for optimal preprocessing pipelines tailored to your new methods and datasets.
It’s not just a recommendation engine — we open the black box of preprocessing and reveal which patterns hurt or help your downstream task performance. (See Figure 1)
2. Method-Aware Preprocessing (MAP)
Have a new downstream task method? Just plug it into DANCE 2.0.
We’ll run a systematic pipeline search to find what preprocessing works best for it.
Our large-scale experiments show DANCE 2.0 significantly outperforms original study pipelines across tasks like annotation, clustering, imputation, joint embedding, and cell type deconvolution. (See Figure 2)
3. Dataset-Aware Preprocessing (DAP)
Need to preprocess a new dataset?
DANCE 2.0 uses similarity-based atlas matching to recommend optimal pipelines on the fly.
We built a preprocessing atlas where each dataset is paired with its optimal pipeline (pre-computed via DANCE 2.0).
Your query dataset is matched to similar ones, and inherits the best preprocessing accordingly. (See Figure 4)
4. Interpretable Insights: Unlocking the Preprocessing Black Box
Through extensive experiments, we found that even within the same task, the optimal preprocessing varies across datasets and methods — depending on dataset characteristics like tissue type, sparsity, or technical noise.
DANCE 2.0 exposes and explains these hidden dependencies. (See Figure 5)
5. A Scientific Asset
We executed over 325,000 pipeline searches across 6 major downstream tasks.
Each run is labeled with task-specific performance, offering an unparalleled resource for benchmarking and insight discovery.
🔗 Paper: biorxiv.org/content/10.110…
💻 Github: github.com/OmicsML/dance (will be open-sourced very soon!)
🌐 Web platform coming soon! You'll be able to upload your new dataset and get on-the-fly recommendations for optimal preprocessing — powered by DANCE 2.0.
DANCE 2.0 will remain an open-source initiative — and we warmly invite the community to contribute, extend, and build upon it.
With amazing collaborators @Stanford @CMUCompBio @StanfordMed
Zhongyu Xing, @YixinxinWang @RemyLau3 @ShengLiu_ @ZhiHuangPhD @WenzhuoTang @Yuyingxie @james_y_zou @Xiaojie_Qiu @jmuiuc Guoxian Yu @tangjiliang
English
Weize Xu retweetet

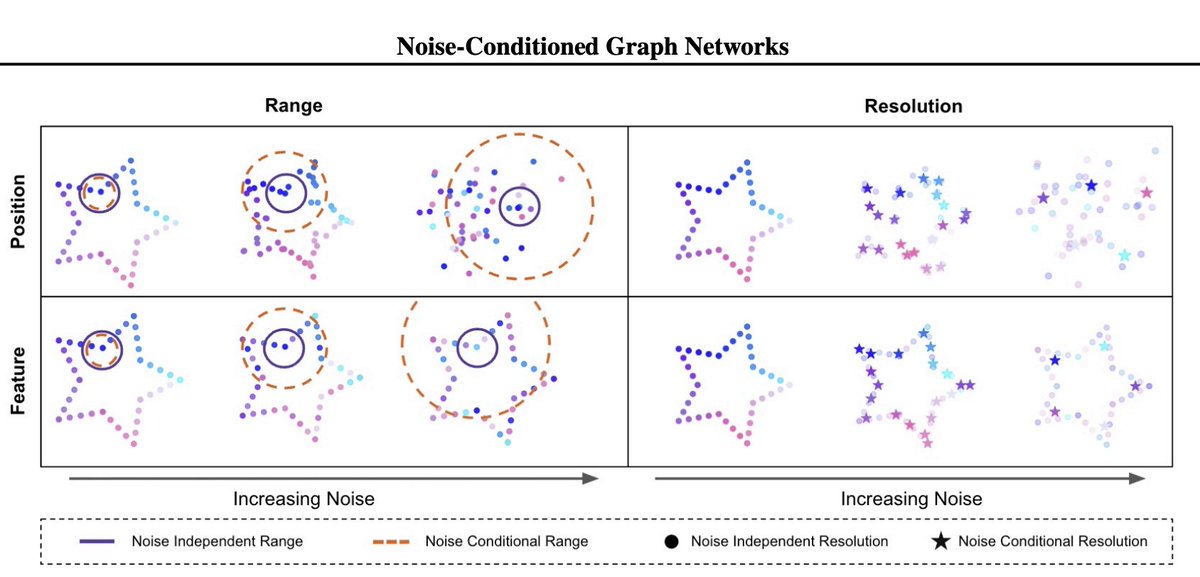
Why do diffusion models use the same GNN structure across denoising?
Our #ICML paper presents Noise-Conditioned Graph Networks, a class of GNNs that adapts the graph structure to the noise level of the generative process.
📄arxiv.org/abs/2507.09391
💻tinyurl.com/ncgn-code
🧵

English
Weize Xu retweetet
I'm thrilled to share that a rotation project fully led by my first PhD student, the amazing Peter Pao-Huang @peterpaohuang, has been accepted to ICML 2025!
Peter's paper, “Geometric Generative Modeling with Noise-Conditioned Graph Networks”, addresses a fundamental limitation in flow-based generative models for geometric graphs: the use of static GNN architectures that don’t adapt to noise. Peter introduces Noise-Conditioned Graph Networks (NCGNs), a novel architecture that dynamically adjusts its message-passing range and graph resolution depending on the noise level during generation.
He developed a specific instantiation called Dynamic Message Passing (DMP), which enables state-of-the-art performance in diverse tasks, e.g. ModelNet40 (3D shapes) or spatiotemporal transcriptomics data, simulated for gene expression dynamics of limbs formation using reaction-diffusion systems involving Sox9, BMP, and Wnt. On this simulation dataset, he show consistency improvement of his approach over state-of-the-art algorithms on:
- Unconditional generation
- Temporal trajectory prediction
- Temporal and spatial imputation
- Gene expression inference and knockout prediction
These studies directly connects to the goals of the Predictive Virtual Cell initiative #virtualcell and related efforts across biology, engineering, AI, and systems modeling.
Please also see his thread here: x.com/peterpaohuang/…
Peter will present this work at ICML 2025 during the poster session on Wednesday, July 16, from 11 a.m. – 1:30 p.m. PDT, in East Exhibition Hall A-B, Poster #E-3110.
If you’re at ICML, especially if you're interested in generative AI, spatial omics, or virtual cell models, I encourage you to stop by his poster, chat with Peter, and explore potential collaborations. You can also check out his paper and code here:
📄arxiv.org/abs/2507.09391
📷tinyurl.com/ncgn-code
Congratulations again, Peter @peterpaohuang ! This is just the beginning 🎉
English

Officially became @drqinyu on July 4th!! 🎓 Huge thanks to @ilastik_team and @embl for the incredible journey. 💫




English
Weize Xu retweetet
We are thrilled to share our new single-cell foundation model, Tabula (preprint: t.co/GLZXx29NP5; package: github.com/aristoteleo/ta…)—a privacy-preserving predictive foundation model for single-cell transcriptomics, leveraging federated learning and tabular modeling.
Over the past year, we’ve seen a surge in foundation models for single-cell genomics, where genes are often arbitrarily ordered to mimic NLP paradigms. Furthermore, as we start to train on large datasets comprising thousands of individuals, the ethical and privacy concerns arise as well. To address these challenges, we introduce Tabula: a federated-learning-based, privacy-preserving foundation model that explicitly represents single-cell data using tabular modeling. Tabula demonstrates excellent performance across diverse tasks, including cell type annotation, multi-omics and multi-batch integration, gene imputation, denoising, and both gene perturbation and reverse perturbation predictions. Very excitingly, as one of the first examples of a truly predictive foundation model, Tabula accurately uncovers pairwise and even combinatorial regulatory logic across diverse biological systems, including hematopoiesis, pancreatic endogenesis, neurogenesis, and cardiogenesis, all of which have very well validated regulatory networks. For more details, please see @JiayuanDing 's excellent post here: x.com/JiayuanDing/st…
This is really an amazing collaboration with three brilliant young trainees, including @JiayuanDing Jianhui (@JilinJJ) and Shiyu (@shiyu_jiang23) and two other labs Jiliang (@tangjiliang), and Min Li..
Kudos to @JiayuanDing , the incredibly talented PhD student in my lab who led this project! Jianyuan is currently on the faculty job market and would be an outstanding addition to any institution. Please consider him and feel free to reach out to Jianyuan or me for more information.
Additionally, Shiyun @shiyu_jiang23 , who contributed to innovative approaches for pairwise and combinatorial perturbation prediction, is applying to PhD programs. Please consider this rising star to join your PhD program as well!
This work represents another important advance in my lab’s long time vision to establish a predictive “virtual embryo” model for human health. We are currently extending this approach to 3D Spatial Transcriptomics data as we previously reported in Spateo (x.com/Xiaojie_Qiu/st…) . If you are a developmental biologist, technology developer, or a machine learning expert, please consider joining us on this exciting journey, please reach out regarding potential positions at all levels in my lab (devo-evo.com/research. Email: xiaojie@stanford.edu). We also highly welcome graduate students from Stanford
@StanfordEng
@DevBioStanford
@ChemSysBio
@StanfordData
@StanfordAILab
for rotations in my new lab. I am excited about many collaboration opportunities within Stanford and the broader Bay Area as well.

English