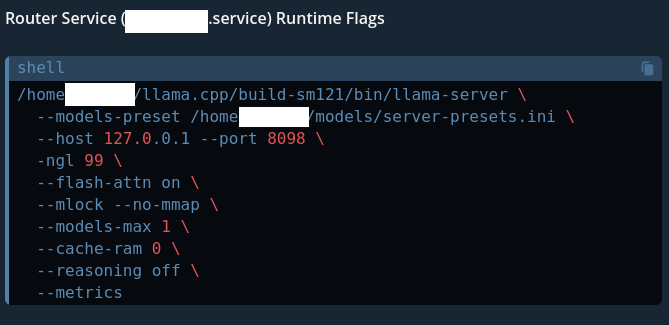
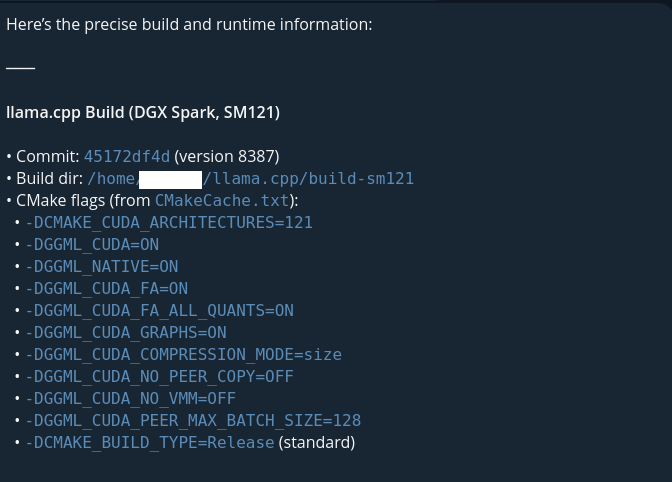
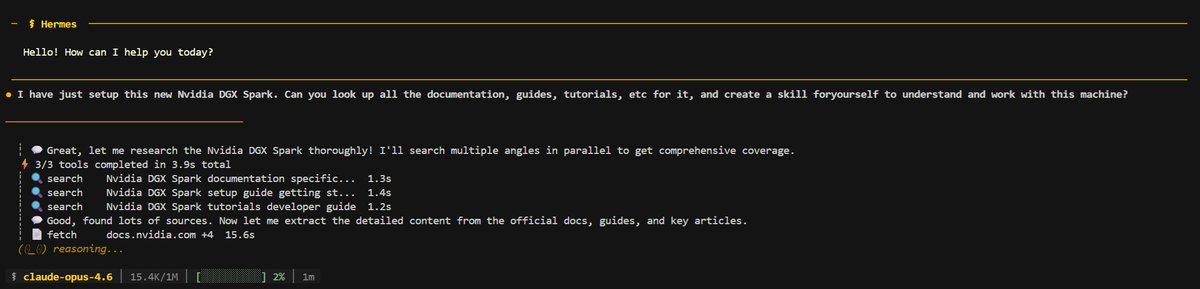
@steeve First time I read about your project. When you release sm121 I will test it on DGX Spark and post here benchmark results. Thanks.
English
⬣PulseChain LIVE⬣ 💥
2.5K posts
@PulseChainLIVE
#AI #Cybersecurity #Linux #privacy

Always so funny stumbling across random Palmer Luckey side quests on the depths of the internet
😳 1x RTX Pro 6000 Blackwell secured now will Nvidia give me MSRP