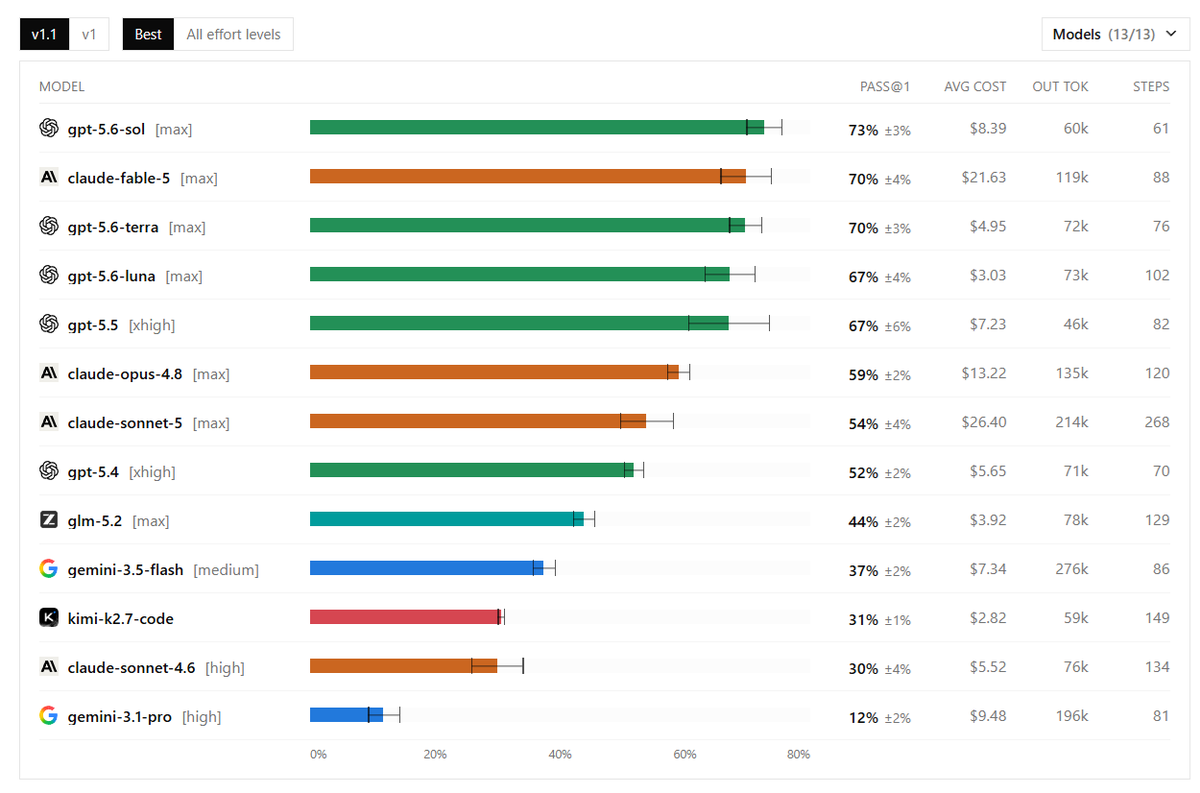
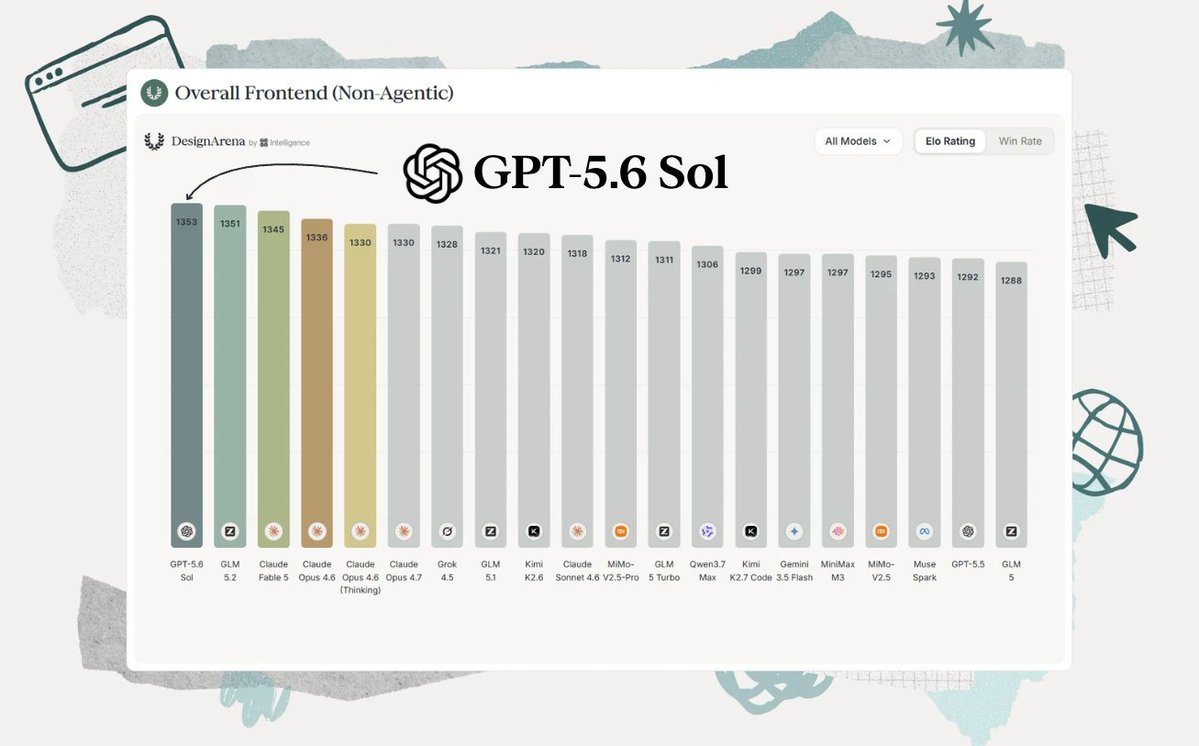
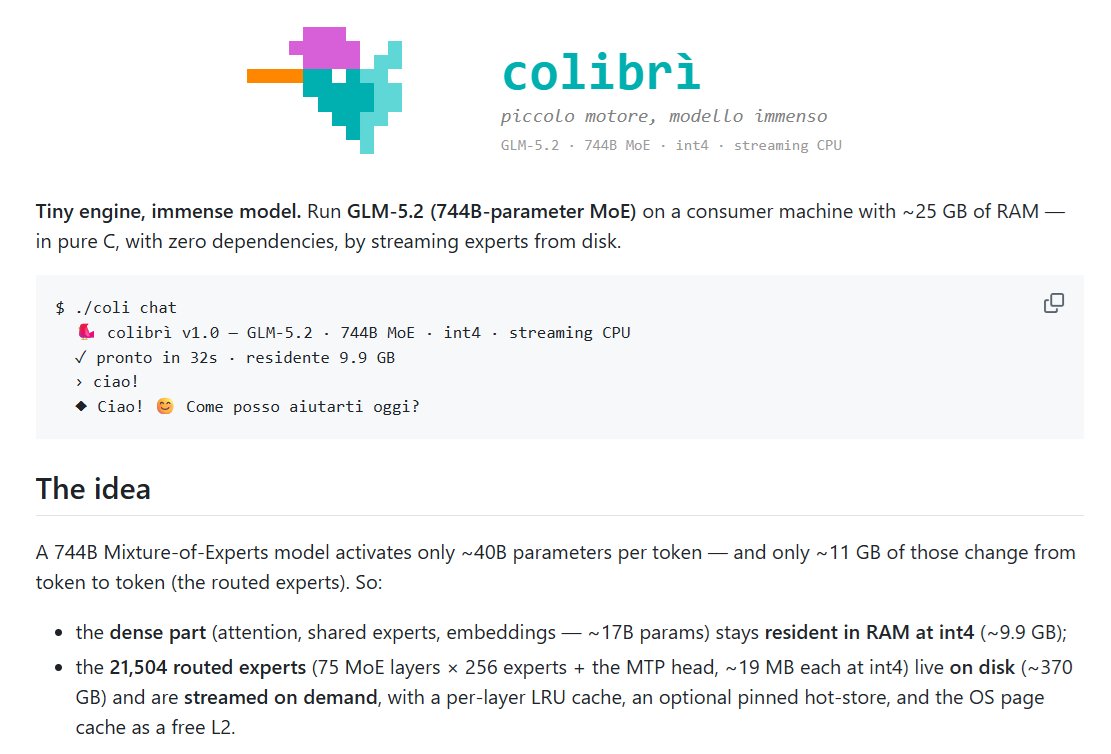
Sabitlenmiş Tweet

🎗️ "Medium-Sized" LLM Burners Coming Soon! 🔥
This Could Make Local HyperToken Generation a Reality. ⚡️ NVIDIA’s worst nightmare? 😱
⚙️ Application-Specific Hardware
Taalas new PCIe ASIC board would burn the entire medium-sized Qwen 3.5-27B LLM straight into silicon 🤯 (already doing it with small models)
Taalos said medium models on ASIC would be available in their lab by Spring '26.
💭Imagine:
🚫 No more loading weights
🚀 ~10,000 Tokens Per Second locally (Llama 3.1 8B already @ 17,000 tps)
💻 Standard PC slot, ultra-low power (10x less) 🔋
🌍 100% offline with no cloud, no GPU farm
💰 Reddit unit cost rumor $300 to $400
🖥️ Imagine HyperToken generation on your desktop.
🤖 AI agents that think at light speed. ⚡️ Are you ready? 👀

English