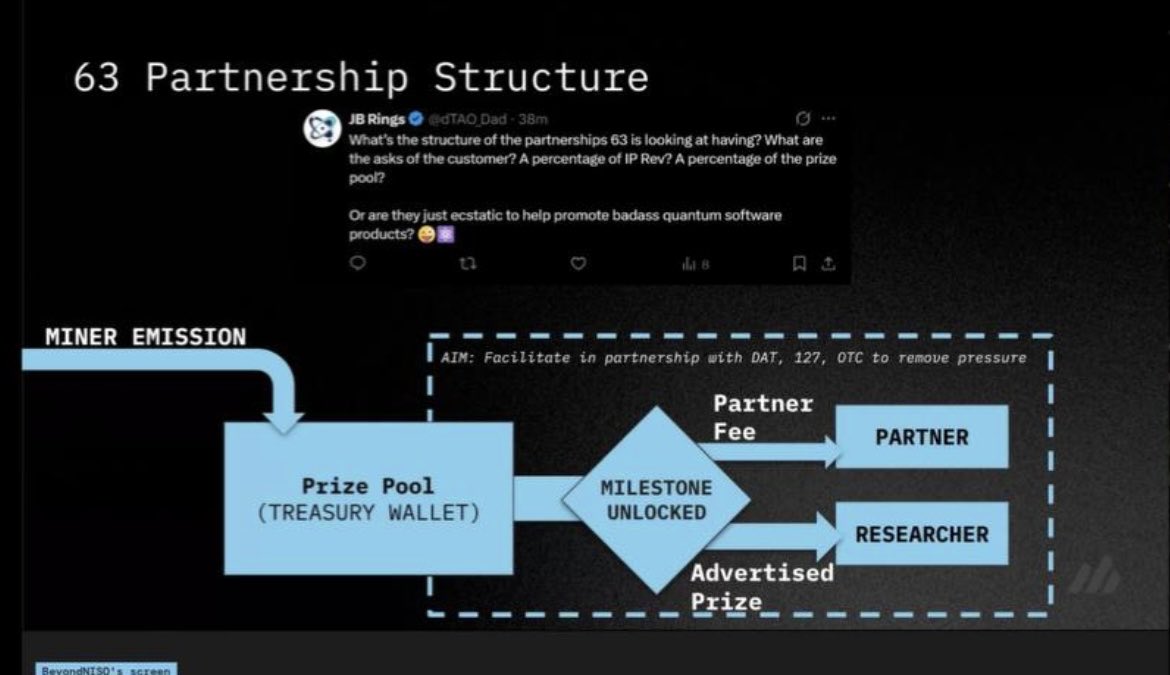
Quasar@QuasarModels
This is Quasar Attention, the mechanism behind the upcoming Quasar models, designed to support context lengths of up to 5 million tokens.
Attention has long been a bottleneck for processing extended context. Standard attention mechanisms struggle to scale beyond ~200k tokens in training, creating a ceiling on how much information models can reliably use.
One approach to solving this has been linear attention methods, such as gated delta attention (used in Qwen 3.5) or Kimi delta attention. These improve efficiency and allow longer sequences, but introduce trade-offs: instability at extreme lengths, quality degradation, and in practice, they are not strictly linear.
Quasar Attention takes a different approach. It uses a continuous-time formulation, implemented as a fully matrix-based system rather than relying on vector-state approximations. In practice, this improves stability, reduces cost, and maintains performance as sequence length increases.
In internal stress tests at 50 million tokens, KDA-based approaches begin to lose stability, while Quasar Attention remains stable. This allows performance to hold as sequence length increases, rather than degrading beyond a fixed threshold.
On BABILong, a Quasar-based model pretrained on 20B tokens and fine-tuned on 16k sequences was evaluated on contexts ranging from 1 million to 10 million tokens, maintaining consistent performance across that range. By contrast, models using gated delta attention show significant degradation at longer lengths, in some cases dropping to ~10% performance at 10 million tokens. (Note: results are indicative; setups are not directly comparable)
On RULER benchmarks, a Quasar-10B model (built on Qwen 3.5 with frozen base weights and Quasar Attention added), pretrained on 200B tokens, achieved 87% at 1 million tokens, outperforming significantly larger baselines, including Qwen3 80B, under the same evaluation conditions.
Taken together, this points to a shift in where long-context performance is won or lost: not in model size alone, but in the attention mechanism itself.
Quasar Attention represents a step change in long-context modelling, setting a new standard for stability and performance at scale.
We thank @TargonCompute for the compute and for being our compute provider and long-term partner in training the upcoming Quasar models
Here is the link to our paper 👇