Angehefteter Tweet
Yuu💖
6.6K posts


Yuu💖
@QuantumTransf
ACMer & Computer Science Enthusiast | Lesbian | 💖love maimai & 📝writing | 🐱Catgirl | 🌌Know you will wake,on winds rise again | 💝I'll always be with you.
Shibuya-ku, Tokyo Beigetreten Ağustos 2023
382 Folgt2K Follower

Yuu💖 retweetet





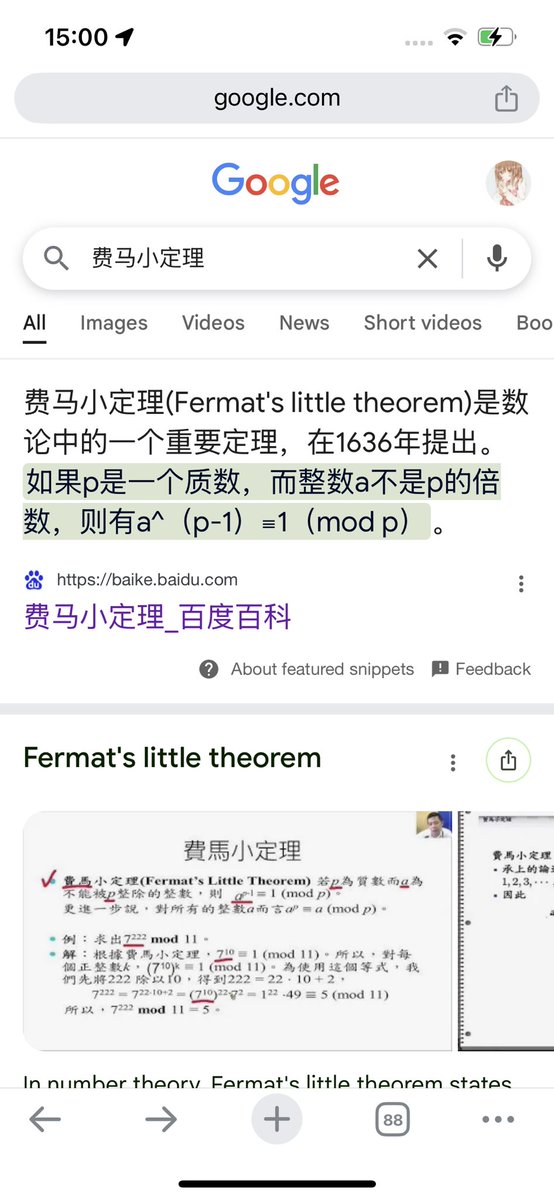
@garrulous_abyss 5^141 (mod 7) = 5^6^23 x 5^3 (mod 7) = 1 x 125 (mod 7) = 6 (mod 7),也就是 1+6=7 星期天...但即便不用费马小定理也能总结 mod 7 的循环规律.
中文


@QuantumTransf @0xNeoHeng @TaNGSoFT 没,agent 每次对话只是把上次的内容一起带过去,只是命中缓存费用会低,但也不是不要钱。比如我实现一个 workflow 就来做生码,调用一次代码输出完成就结束了,这种没必要塞很多东西吧?我是这么理解
中文

消化了一下MSA,Memory Sparse Attention:本质上是利用attention机制对本地文本的学习,包括与LLM交互的trajectory文本。
MSA 填补了"单次会话内的超长上下文"这个格子。这个格子之前要么靠 RAG 外挂(不是真正的 in-context),要么靠暴力扩窗口(计算不可行),现在 MSA 提供了一个端到端的原生解法。
从 NTT(Next Turn Prediction)的框架看:MSA 让单个 turn 内的推理能够访问更完整的历史,这提升了每个 turn 的质量上限。但 turn 与 turn 之间的连续性问题——这个 M-step vs. E-step 的边界问题——MSA 没有触及,也不应该触及。这是两个不同层级的问题。
最终判断:
MSA 是序列轴上的真实突破,不是炒作。但它解决的是会话内的超长记忆,不是跨会话的持久记忆。"让大模型原生拥有超长记忆"这个描述是准确的——但"超长"的边界仍然是单次推理上下文,不是真正意义上的情节记忆(episodic memory)。
真正的持久记忆问题,在 TASTE.md 和 GOTCHAS.md 的工程层面依然需要解决——因为那个问题的本质是M-step 结果的跨会话持久化,而 MSA 优化的是 E-step 内部的信息访问效率。两者都需要,在不同的层级上工作,没有一个能取代另一个。
艾略特@elliotchen100
论文来了。名字叫 MSA,Memory Sparse Attention。 一句话说清楚它是什么: 让大模型原生拥有超长记忆。不是外挂检索,不是暴力扩窗口,而是把「记忆」直接长进了注意力机制里,端到端训练。 过去的方案为什么不行? RAG 的本质是「开卷考试」。模型自己不记东西,全靠现场翻笔记。翻得准不准要看检索质量,翻得快不快要看数据量。一旦信息分散在几十份文档里、需要跨文档推理,就抓瞎了。 线性注意力和 KV 缓存的本质是「压缩记忆」。记是记了,但越压越糊,长了就丢。 MSA 的思路完全不同: → 不压缩,不外挂,而是让模型学会「挑重点看」 核心是一种可扩展的稀疏注意力架构,复杂度是线性的。记忆量翻 10 倍,计算成本不会指数爆炸。 → 模型知道「这段记忆来自哪、什么时候的」 用了一种叫 document-wise RoPE 的位置编码,让模型天然理解文档边界和时间顺序。 → 碎片化的信息也能串起来推理 Memory Interleaving 机制,让模型能在散落各处的记忆片段之间做多跳推理。不是只找到一条相关记录,而是把线索串成链。 结果呢? · 从 16K 扩到 1 亿 token,精度衰减不到 9% · 4B 参数的 MSA 模型,在长上下文 benchmark 上打赢 235B 级别的顶级 RAG 系统 · 2 张 A800 就能跑 1 亿 token 推理。这不是实验室专属,这是创业公司买得起的成本。 说白了,以前的大模型是一个极度聪明但只有金鱼记忆的天才。MSA 想做的事情是,让它真正「记住」。 我们放 github 上了,算法的同学不容易,可以点颗星星支持一下。🌟👀🙏 github.com/EverMind-AI/MSA
中文
@hawtim_z @0xNeoHeng @TaNGSoFT 其实这个 cache 是一个类似 disk 的东西,大模型厂商如果真跟进的话应该会提供获取这个 cache 的 api
而一般 agent 实现都是多次会话,不可能单次会话的
中文
@QuantumTransf @0xNeoHeng @TaNGSoFT 我就没懂这个地方,什么需求要直接塞完整所有可能相关的信息的。如果只是单次会话不是费用爆炸?还是那个巨大上下文直接命中 cache?
中文
@0xNeoHeng @TaNGSoFT 你好,agent 不可能一直挂着一个 react loop 然后一直等外面 append 消息的,这不现实,真上生产成本能把你吓死
中文


openai 拿走了 uv ,
anthropic 抱走了 bun ,
我们都有美好的未来
OpenAI Newsroom@OpenAINewsroom
We've reached an agreement to acquire Astral. After we close, OpenAI plans for @astral_sh to join our Codex team, with a continued focus on building great tools and advancing the shared mission of making developers more productive. openai.com/index/openai-t…
中文


Yuu💖 retweetet







bub 从一个群聊的助手变成一个基本框架就是因为我们很难让其为所有可能的方向优化
我更推荐从一个基础的状态开始,让 bub 在业务中生活,构建符合真实场景的插件和技能
Leechael@Leechael
这些天分别和不同的朋友聊 agent 的落地,单纯从一个垂类来看,通用 agent 限制还是有点多。agentic saas 会有特定的工作流,会需要一个特定的工作协助空间,这都不是通用 agent 能完成的。IM gateway、记忆、定时任务、大量的工具(skills)只是入门门槛。
中文