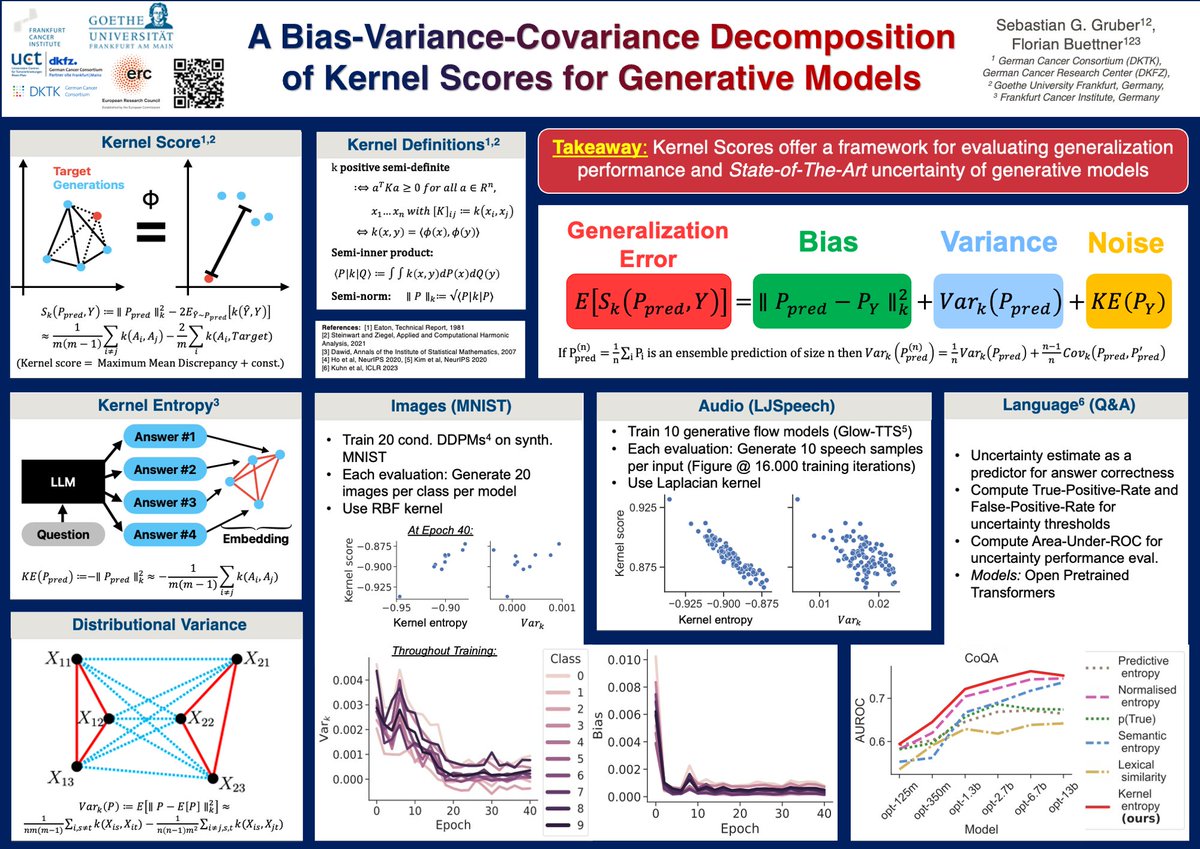
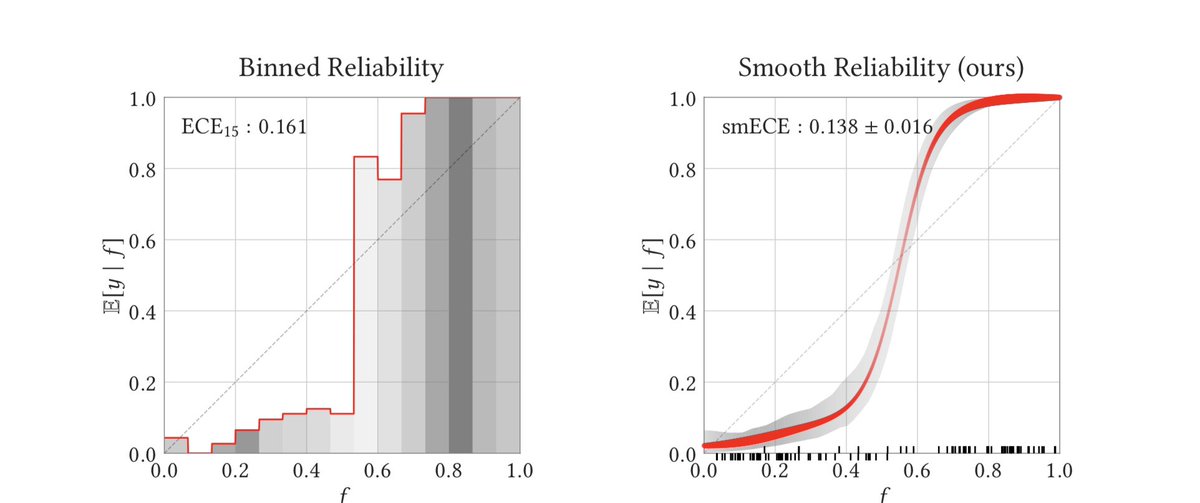
@pfau @FrnkNlsn Finally, it happened!! :D I wrote one of the papers citing your old version. Maybe, interestingly for you, I provided the bvd in the dual space, and also for functional cases arxiv.org/pdf/2210.12256
English
Sebastian G. Gruber
50 posts
@SebGGruber
Postdoc in Uncertainty Quantification (Machine Learning)