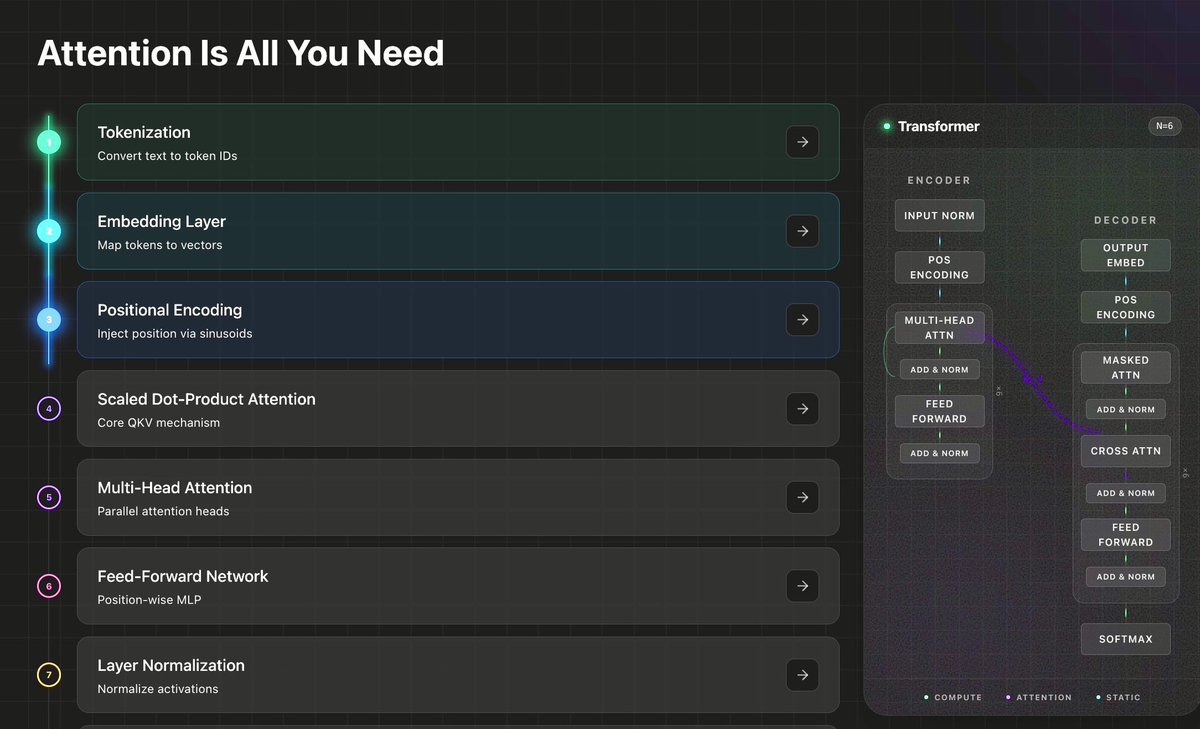
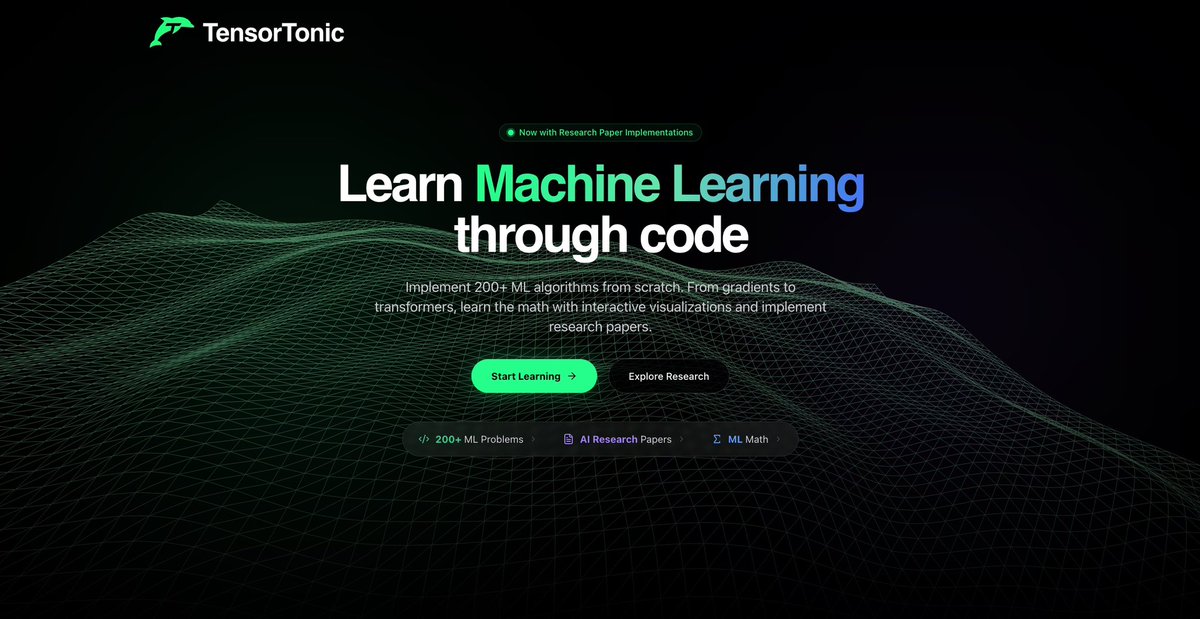
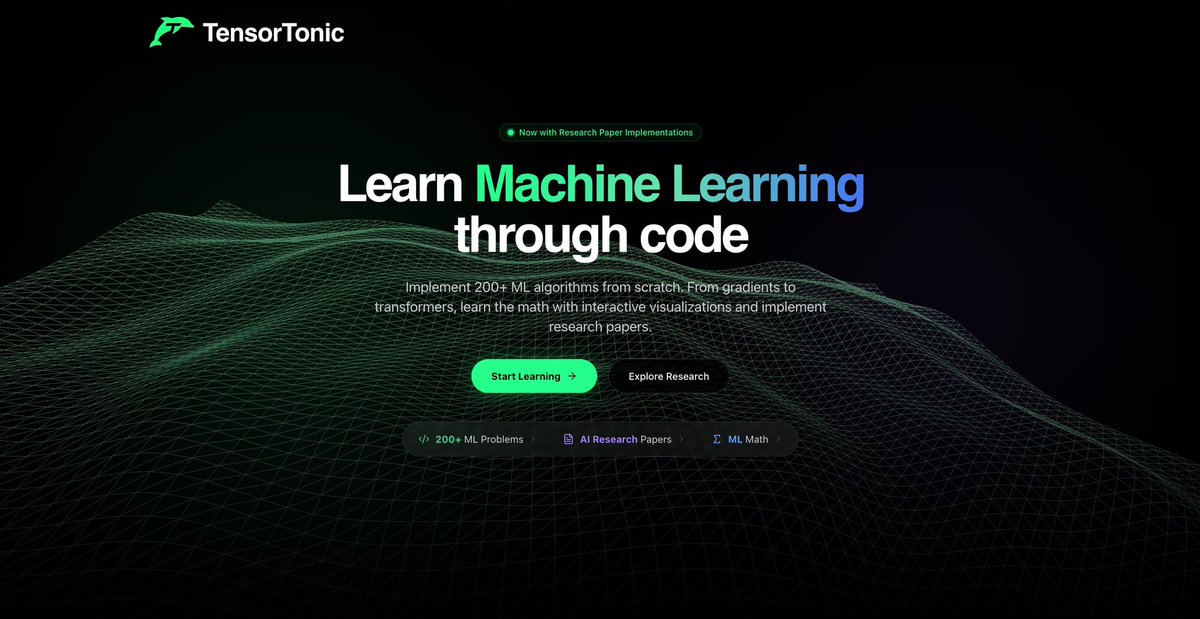
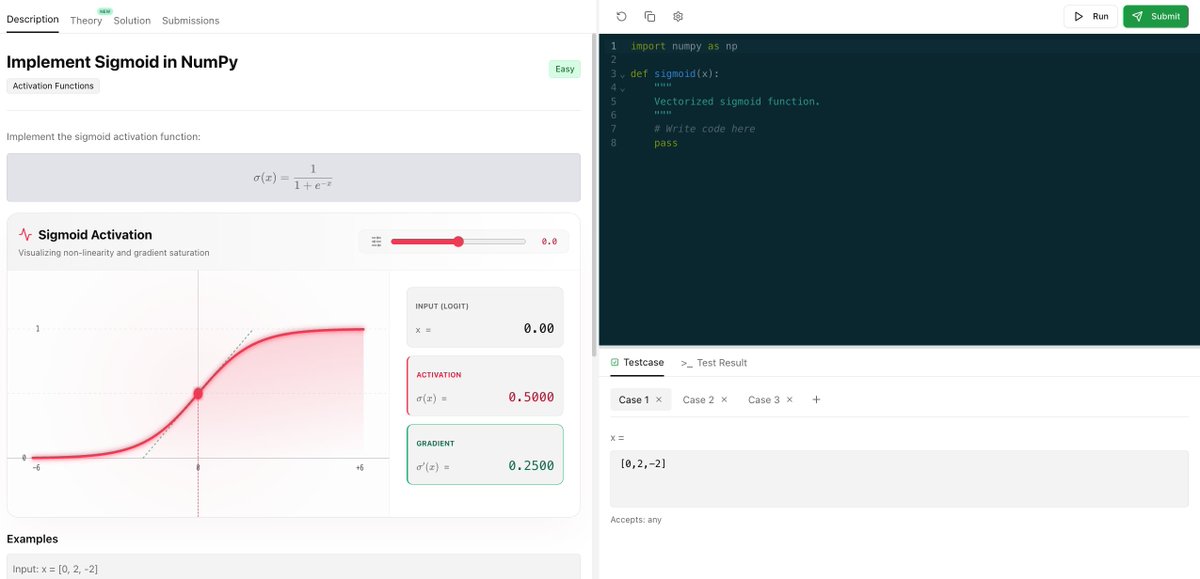
Angehefteter Tweet

TensorTonic Pro is launching soon. The waitlist is live. ⏱️
Members on the waitlist will:
-> Get early access
-> Receive an exclusive launch discount
If you’ve been enjoying TensorTonic, this is your chance to get in early.
Registration link in comments.

English