TensorTonic retweetledi

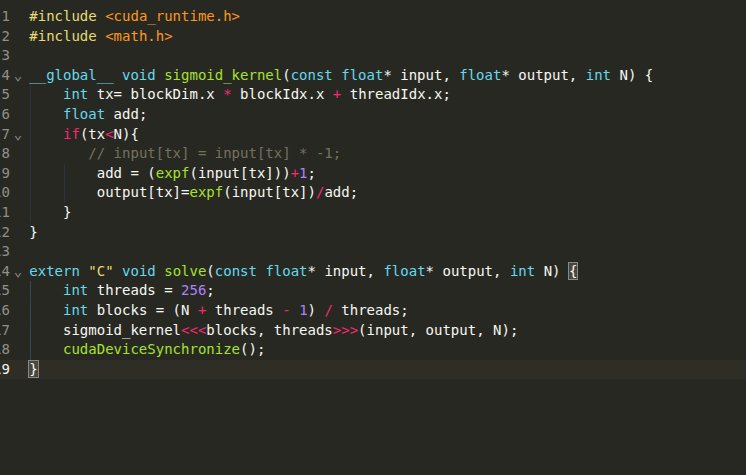
Implement a CUDA kernel for the sigmoid (logistic) activation in C
in both naive and vectorized load approach
in both the way the roofline ratio was 0.375 FLOP/byte.
However, In vectorized approach(i.e each thread processing 16 byte)
it required fewer instruction to compute i.e 16 byte per instruction
also it lead to proper utilization of Pcie bus due to its saturation
Here's the code img for both the implementation
Submited on @TensorTonic

English