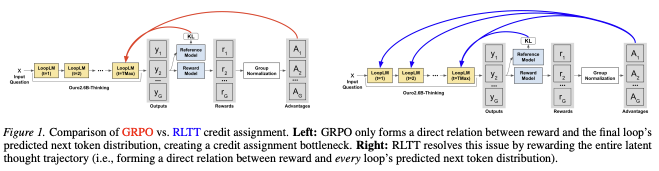
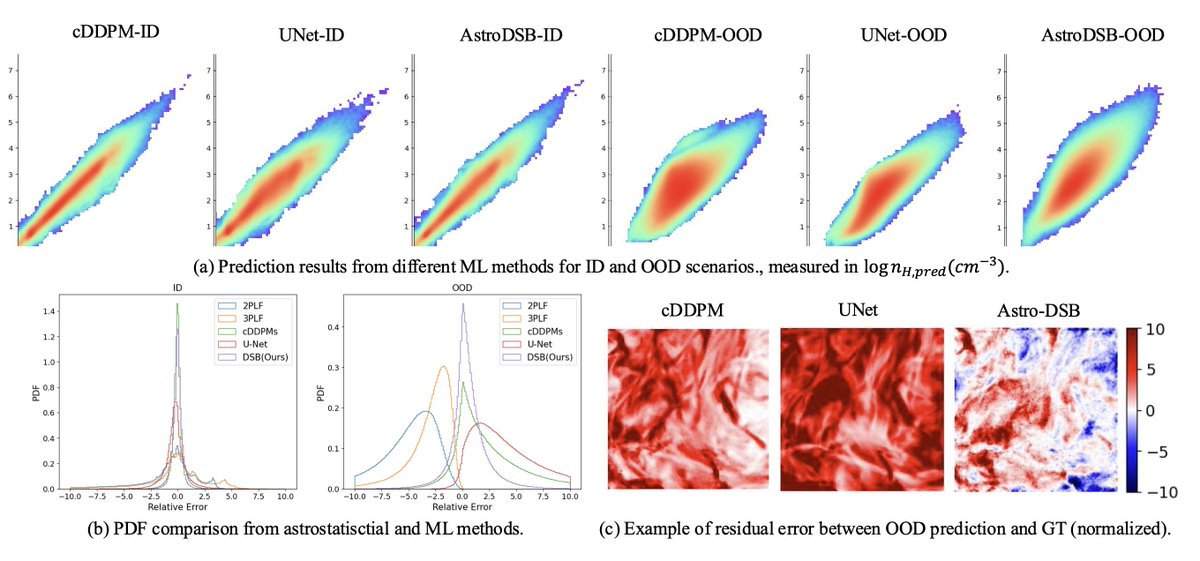
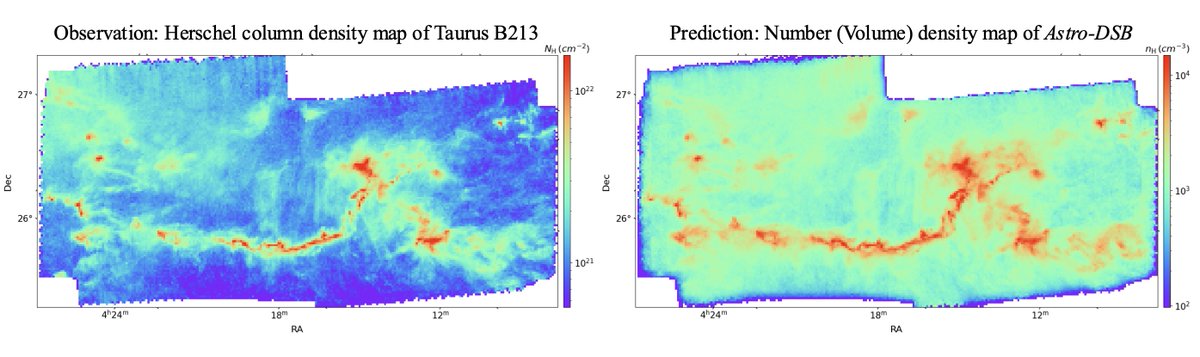
Princeton Visual AI lab retweetet

Fast weights were built for long term memory, but trained for short attention spans.
We introduce ReFINE, a phase-agnostic RL framework that improves long-context modeling in fast weight architectures.
arxiv.org/abs/2602.16704
1/8

English