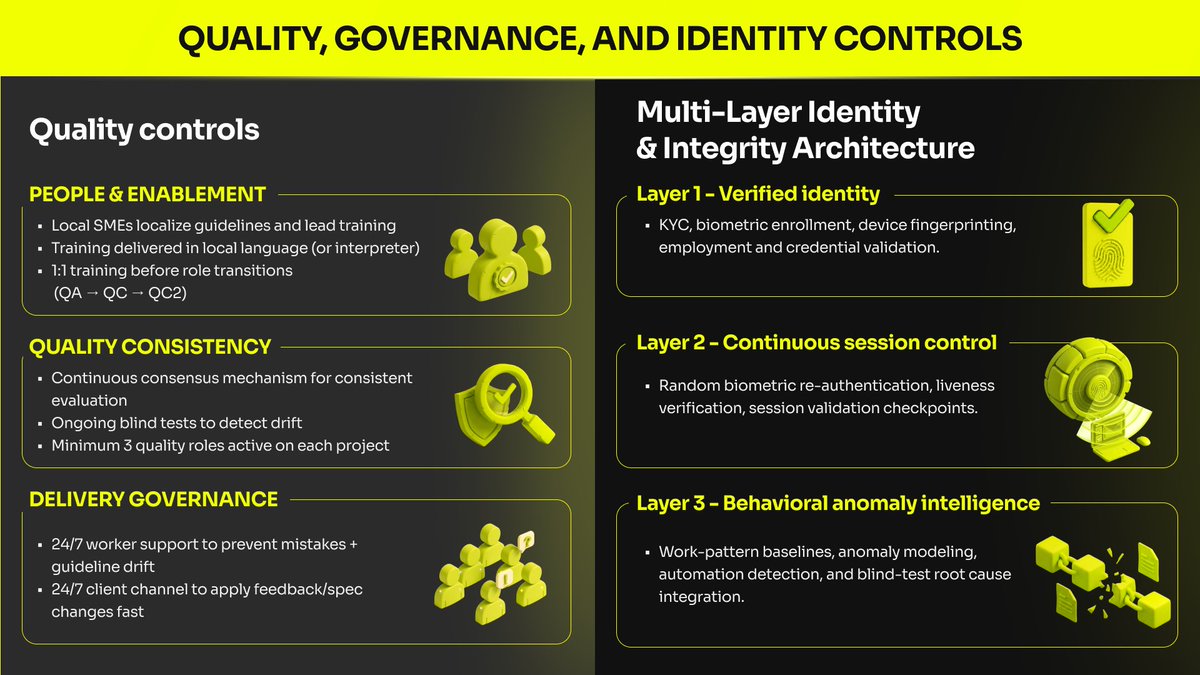
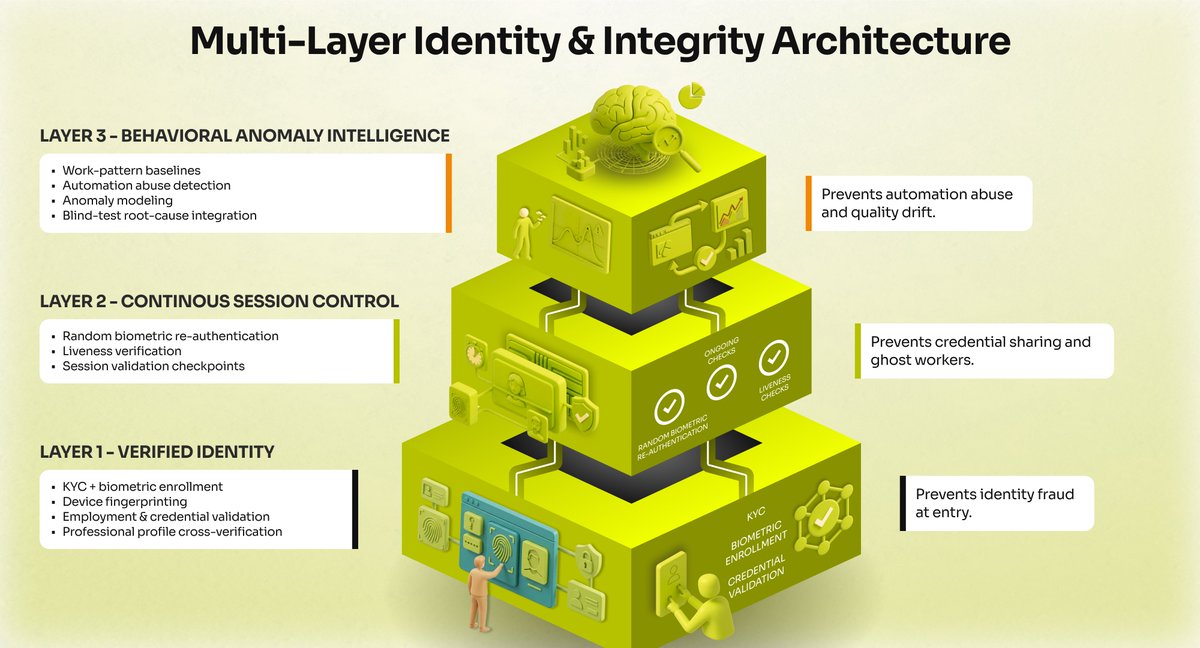
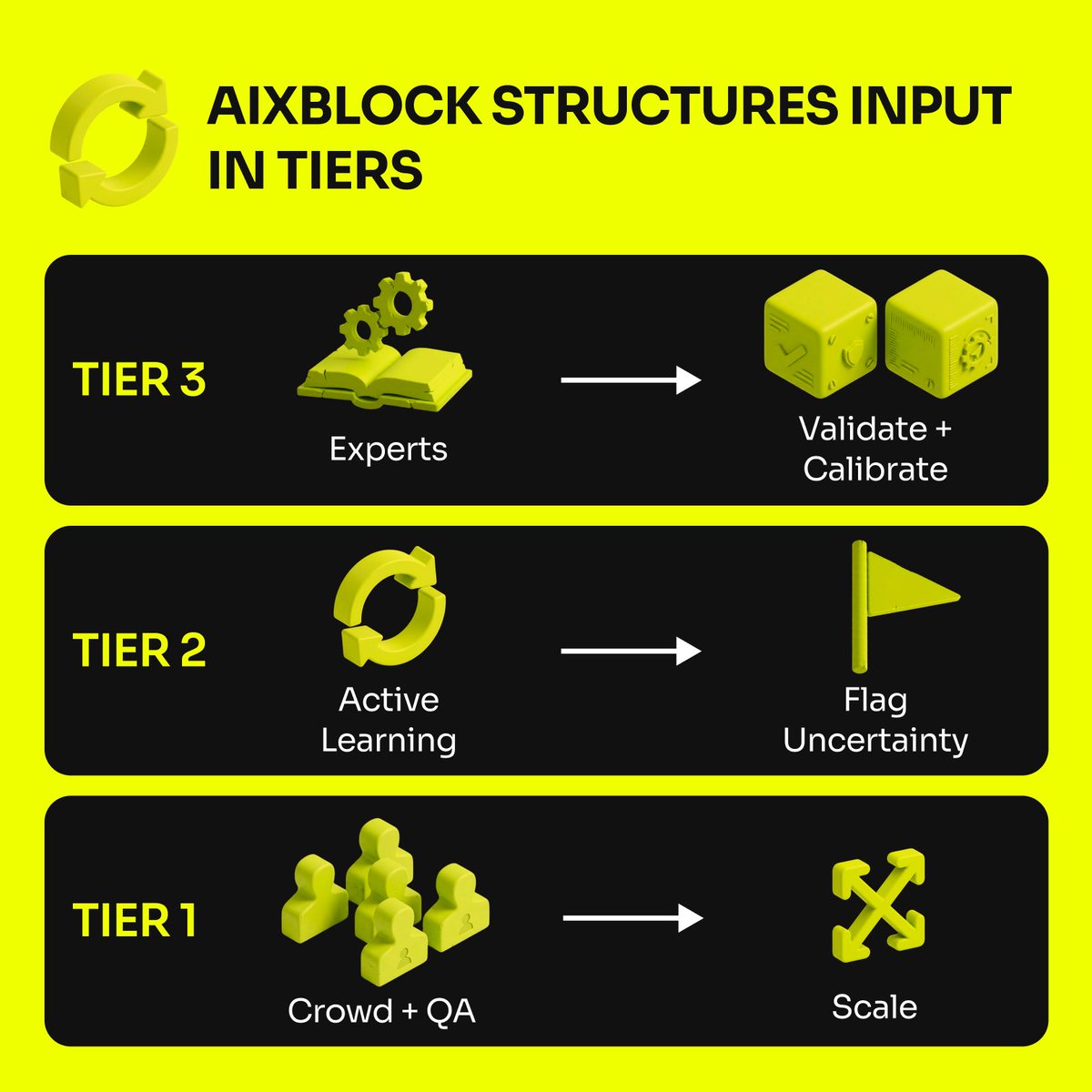
AIxBlock: 6 years. 3 chapters. One clear focus: We stopped chasing “more” - We doubled down on what ships. Chapter 1 — In the trenches (2019 →) 4 years collecting, transcribing, and labeling speech + text. 100+ languages. Accent variance. Real noise. We delivered large-scale projects for Fortune 500 companies and global tech unicorns and learned: quality is a system (sourcing, consent, QA, domain rules, reliable delivery) - not a promise. Chapter 2 — We built the system We asked a bigger question: what if we could build the entire infrastructure for AI development? How do we make that reliability repeatable? With backing from an EU innovation program, we built the infrastructure serious teams need: data engines, training/deployment toolkits, distributed computing, workflow automation, and self-hosted deployment when governance requires it. Chapter 3 — Today: clarity (our repositioning) We’re sharpening the promise: AIxBlock is an enterprise training data partner for speech and large language models. We deliver datasets for training, fine-tuning, and evaluation—designed for privacy, provenance, and provable quality in production settings. If you’re building voice AI / ASR / LLM models for production, comment “DATA” and we’ll send a 1-page product overview.