𝗡𝗼𝘁 𝗮𝗹𝗹 𝗵𝘂𝗺𝗮𝗻 𝗶𝗻𝗽𝘂𝘁 𝗶𝘀 𝗲𝗾𝘂𝗮𝗹 - 𝘀𝗺𝗮𝗿𝘁 𝗔𝗜 𝘁𝗲𝗮𝗺𝘀 𝗸𝗻𝗼𝘄 𝘄𝗵𝗲𝗻 𝘁𝗼 𝘂𝘀𝗲 𝘄𝗵𝗶𝗰𝗵 𝘁𝘆𝗽𝗲.
In hybrid intelligence systems, it’s not about more input, it’s about the right input at the right time. Research shows crowd-sourced labeling can reach expert-level quality when structured properly - but only if the task fits the model.
𝗪𝗵𝗲𝗻 𝗰𝗿𝗼𝘄𝗱 𝗶𝗻𝗽𝘂𝘁 𝘀𝗵𝗶𝗻𝗲𝘀
Clear, objective, high-volume tasks (tagging categories, basic classification)
Well-designed workflows with quality checks (label aggregation, confidence weighting)
Scalable early-stage data for bootstrapping models or surfacing patterns
Crowds work best when nuance isn’t critical and noise can be managed with smart aggregation and automation.
𝗪𝗵𝗲𝗻 𝗱𝗼𝗺𝗮𝗶𝗻 𝗲𝘅𝗽𝗲𝗿𝘁𝘀 𝗮𝗿𝗲 𝗶𝗻𝗱𝗶𝘀𝗽𝗲𝗻𝘀𝗮𝗯𝗹𝗲
High-stakes, context-rich decisions (legal, medical, ethical)
Ambiguous edge cases where generic labels fail
Model evaluation and grounding to prevent shortcuts that appear correct statistically but fail in reality
Experts provide the context and judgment machines and crowds cannot infer.
🔄 𝗧𝗵𝗲 𝗽𝗼𝘄𝗲𝗿 𝗶𝘀 𝗶𝗻 𝗼𝗿𝗰𝗵𝗲𝘀𝘁𝗿𝗮𝘁𝗶𝗼𝗻
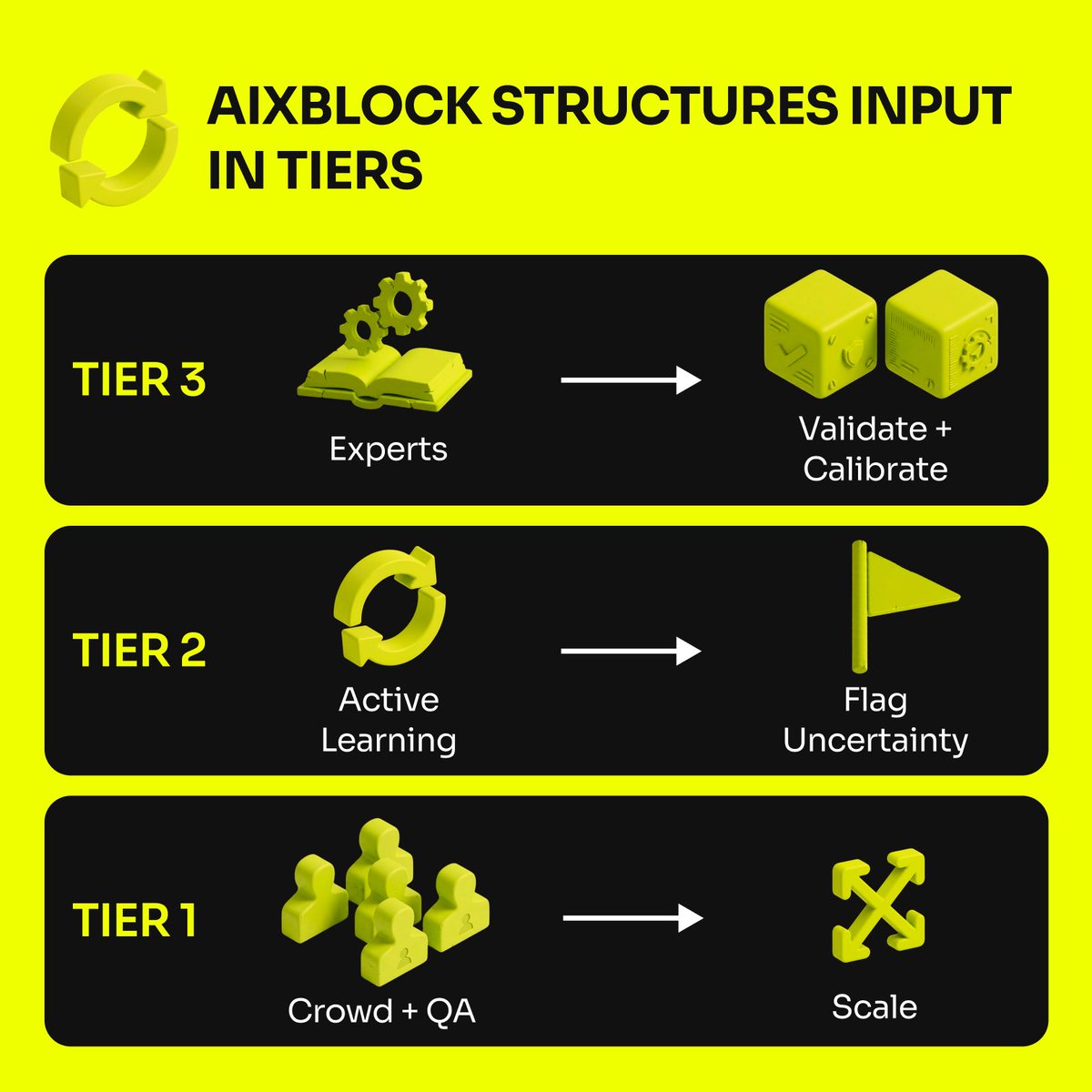
AIxBlock structures input in tiers:
1. Crowd + automated quality checks → scale and coverage
2. Active learning loops → uncertain or low-confidence items flagged for expert review
3. Domain expert calibration → anchors AI in real-world reasoning
This layered approach turns raw data into trustworthy intelligence, not just bigger datasets.
Crowds = scale. Experts = meaning.
AIxBlock combines both so your models learn fast without losing fidelity.
In AI, trust isn’t optional - it’s engineered.



English