Angehefteter Tweet

New paper on synthetic pretraining!
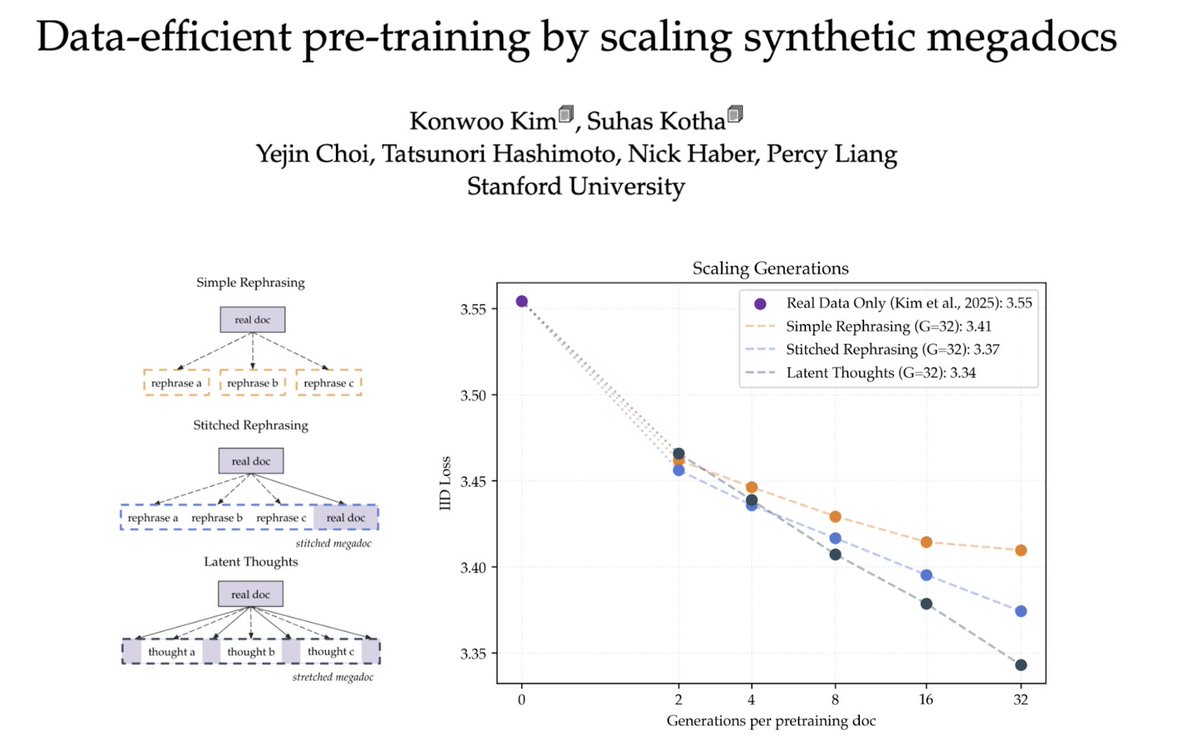
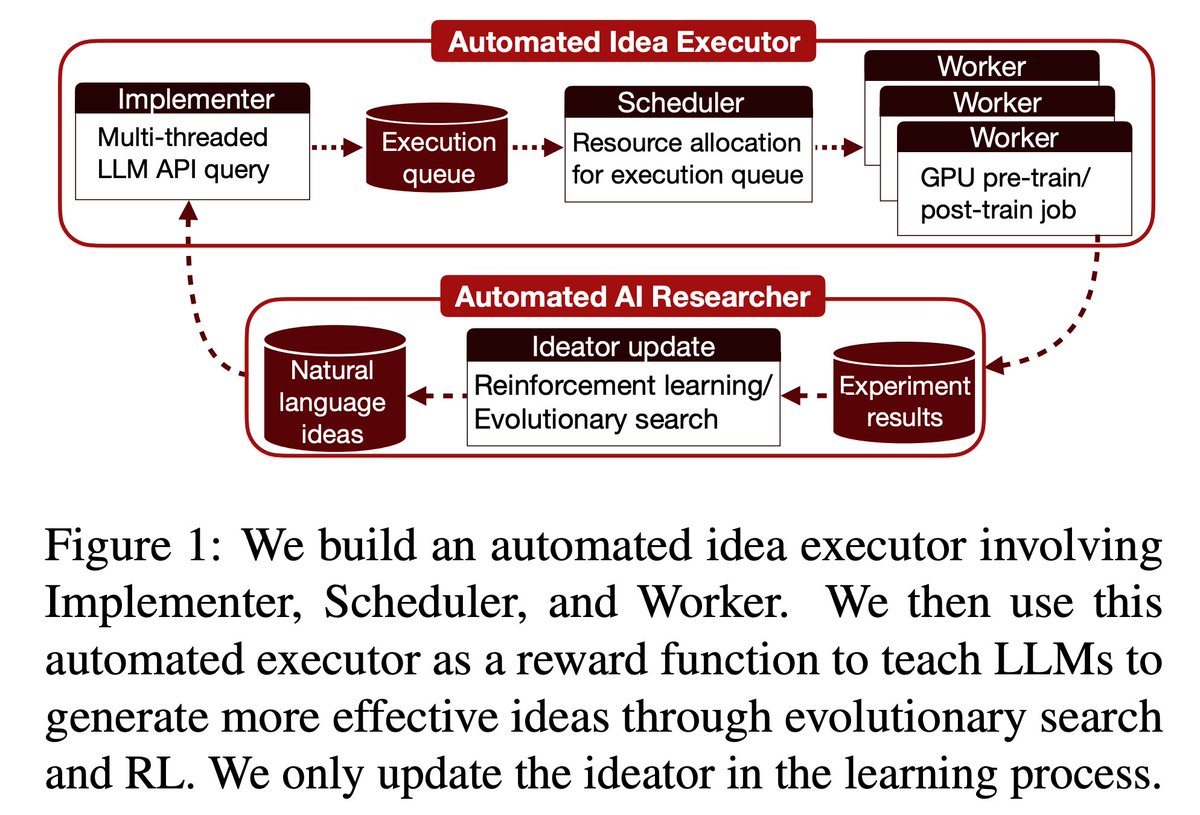
We show LMs can synthesize their own thoughts for more data-efficient pretraining, bootstrapping their capabilities on limited, task-agnostic data. We call this new paradigm “reasoning to learn”.
arxiv.org/abs/2503.18866
Here’s how it works🧵

English