
Yebin Liu
42 posts

Yebin Liu
@YebinLiu
Professor, Tsinghua University 3D Vision, Digital Human
Beijing Beigetreten Mart 2022
179 Folgt1.8K Follower
We have build a code repository of our group projects and made public some source codes, including the latest works of DreamCraft3D, GPS-Gaussian, HumanNorm, and HAvatar.
See: github.com/thu3dhuman

English
Yebin Liu retweetet

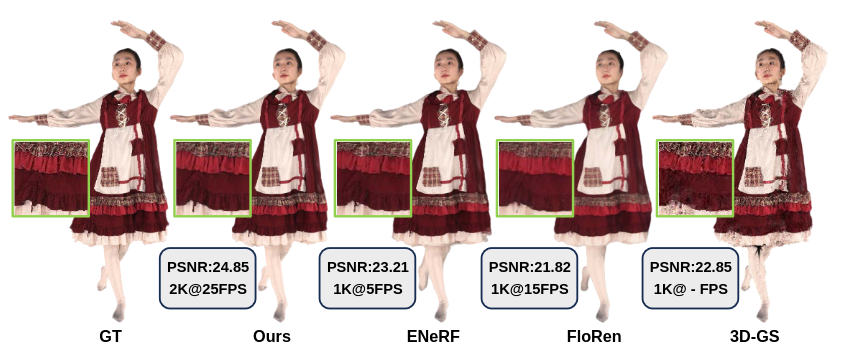
It is truly Christmas today: More code dropped: "GPS-Gaussian: Generalizable Pixel-wise 3D Gaussian Splatting for Real-time Human Novel View Synthesis"
github.com/ShunyuanZheng/…
English
Gaussian Splatting relies on per-frame parameter optimizations for several minutes. Our generalizable pixel-wise 3D Gaussian Splatting enable instantly and realtime rendering without necessitating any fine-tuning or optimization for an unseen character. shunyuanzheng.github.io/GPS-Gaussian
English
Yebin Liu retweetet

Thrilled to share my latest work, Control4D! 🌟 This groundbreaking paper introduces advanced human editing capabilities, all in 4D space. Control4D sets new standards in quality, efficiency, and consistency for 4D editing.
Imagine creating fun and unique effects, like some famous tech CEOs grilling in a leather jacket, or pouring coffee – the possibilities are endless. Transform into your favorite superhero, wear elf king's silver armor, or have a digital meet-and-greet with a star. All of this is happening in a 4D scene within several minutes!
Check out our project page at control4darxiv.github.io for more exciting details.
English
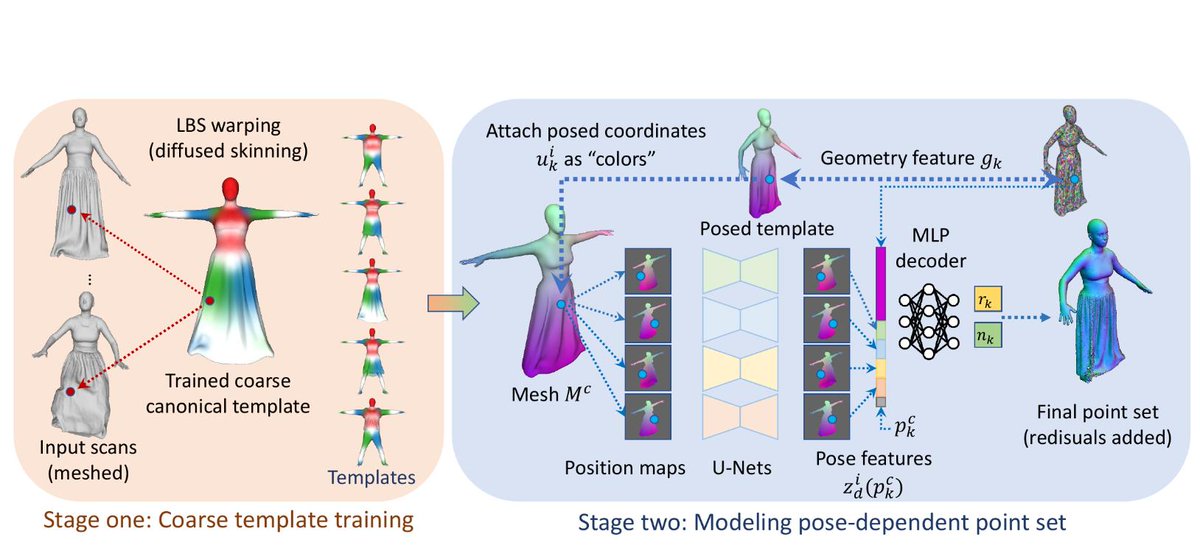
Animatable Gaussians: Learning Pose-dependent Gaussian Maps for High-fidelity Human Avatar Modeling
Projectpage: animatable-gaussians.github.io
English


Yebin Liu retweetet

DreamCraft3D: Hierarchical 3D Generation with Bootstrapped Diffusion Prior
paper page: huggingface.co/papers/2310.16…
present DreamCraft3D, a hierarchical 3D content generation method that produces high-fidelity and coherent 3D objects. We tackle the problem by leveraging a 2D reference image to guide the stages of geometry sculpting and texture boosting. A central focus of this work is to address the consistency issue that existing works encounter. To sculpt geometries that render coherently, we perform score distillation sampling via a view-dependent diffusion model. This 3D prior, alongside several training strategies, prioritizes the geometry consistency but compromises the texture fidelity. We further propose Bootstrapped Score Distillation to specifically boost the texture. We train a personalized diffusion model, Dreambooth, on the augmented renderings of the scene, imbuing it with 3D knowledge of the scene being optimized. The score distillation from this 3D-aware diffusion prior provides view-consistent guidance for the scene. Notably, through an alternating optimization of the diffusion prior and 3D scene representation, we achieve mutually reinforcing improvements: the optimized 3D scene aids in training the scene-specific diffusion model, which offers increasingly view-consistent guidance for 3D optimization. The optimization is thus bootstrapped and leads to substantial texture boosting. With tailored 3D priors throughout the hierarchical generation, DreamCraft3D generates coherent 3D objects with photorealistic renderings, advancing the state-of-the-art in 3D content generation.
English
Yebin Liu retweetet

Now we release the source code of Next3D at github.com/MrTornado24/Ne…. Welcome to have a try😀
Jingxiang Sun@JingxiangSun42
🎉🎉 Our paper "Next3D: Generative Neural Texture Rasterization for 3D-Aware Head Avatars" has been accepted to present at #CVPR2023! We Introduce a 3D GAN for high-quality facial avatars and welcome to check out its applications on one-shot 3D animation and stylization😎
English

Our new Siggaph Asia 2022 paper proposes a real-time 3D-aware face editing framework that supports high-fidelity facial synthesis and fine-grained style editing of shape and appearance. mrtornado24.github.io/IDE-3D/
English
@CruxDatum The other video I tweet yesterday has black color. I will give some other results with black faces recently.
English

Our new Siggaph Asia 2022 paper proposes a real-time 3D-aware face editing framework that supports high-fidelity 3D face style editing. mrtornado24.github.io/IDE-3D/
English

@YebinLiu thats pretty crazy. can you make non humans? like creatures in 3d, like monsters you'd fight in video game?
English

Yebin Liu retweetet

Demo code for PyMAF-X is now released on GitHub. 👏👏Please check out the new branch of PyMAF: github.com/HongwenZhang/P…
Issues, pull requests, and discussions are welcome! 😃
Yuliang Xiu@yuliangxiu
Have tried several SMPL-based pose estimators on very challenging images, and PyMAF performs most robustly. Hence I finally set PyMAF as the default HPS of ICON. Cannot wait to replace PyMAF with PyMAF-X!
English
Source code (including training code) public at:
github.com/jsnln/fite
#ECCV2022 Learning Implicit Templates for Point-Based Clothed Human Modeling
jsnln.github.io/fite/
English
@Michael_J_Black See tab.1 in the main paper for evaluation of camera setting. Also, we will public the source code for the diffusion stereo part soon, as well as the data.
English

@YebinLiu The demo video on the project page won't play for me. I'm really intrigued by the quality from sparse views and am wondering about the camera setup. How are the cameras arranged?
English
#ECCV2022(Oral). Diffusion model is also good at stereo matching! In this work, by learning diffusion stereo matching on the high quality human scan datasets, we achieve high quality reconstruction using only 8 camera views on real world data.
Project: liuyebin.com/diffustereo/di…
English
@Michael_J_Black We have uploaded the video demo and the supp.doc. For the reconstruction of synthetic 8 view data, our cameras are evenly spaced. For the reconstruction of real data, we need to make the stereo camera denser to about 25 degree to improve the performance (still 8 cameras total).
English
@Hotmedal I would say currently for a human model reconstruction, the time (about 20 seconds) is similar to traditional dense view-based MVS reconstruction approach. For reconstruction on large terrains, you need to retrain the diffusion stereo model using 3D terrain dataset.
English
