Angehefteter Tweet

@grok and @suno helped us make this music video in under 1 day. BLANKET MEN (Cape of Concrete) youtu.be/chkHki32PSI?si… via @YouTube

YouTube
English
Eric Henderson
12.3K posts

@ZippyNetworks
Government Abuse is BAD for business. Getting ripped off on business phone / internet? Veteran-owned Business Telecom consulting. Free quotes USA lowest prices.



@VideoCardz Intel Arc Pro B70 has 32 Xe cores, 256 XMX engines, up to 367 peak TOPS, and 608 GB/s memory bandwidth with 32 GB GDDR6. 160W to 290W power. 32 GB would be nice for AI interference! But its memory bandwidth is only 34% of Nvidia RTX 5090, price is also ~34%, $949 MSRP.







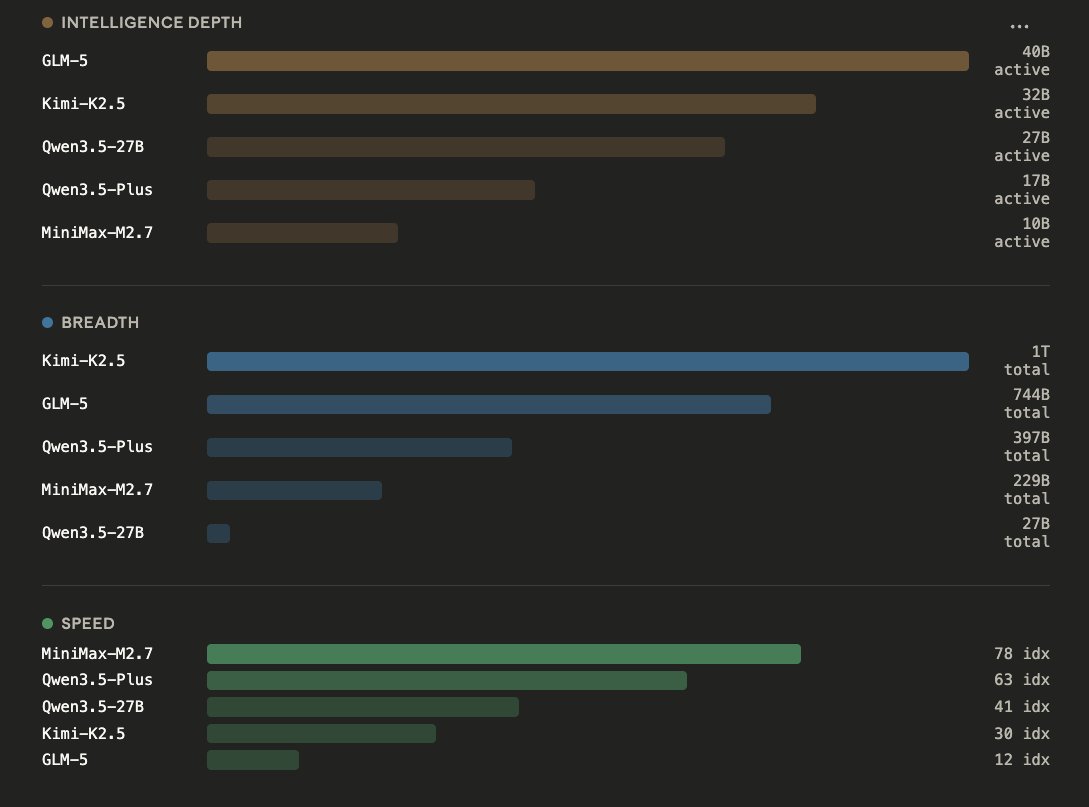
People are not lying when they say Qwen3.5-27B is incredibly capable. 1. Bubble size = total params - World Knowledge, Languages, Skills 2. X axis = active params - Raw Intelligence per token 3. Y axis = tokens/s - Speed of prefill and generation (decode) GLM-5 | 744B params | 40B active Kimi-K2.5 | 1T params | 32B active Qwen3.5-27B | 27B active params Qwen3.5-Plus | 397B params | 17B active MiniMax-M2.7 | 229B params | 10B active MoEs can store much more world knowledge, and breadth of information. For a Mixture-of-Expert, you can stack it up to 1T params, so you can give it 20 Trillion tokens or more of training data, it learns more. But during runtime, only a small portion of that gets activated. Taking MiniMax-M2.5 as an example: Only 10B are active at a time, so while you use it you get the speed and closer intelligence to nemotron-8B it's just MiniMax-M2.5 can know much more, and thus perform better.









