
@WilliambilSf You just open bankr.bot/terminal to the menu and chat AI, type create a coin with the name Aevon and you already have your own coin
English
Aetjess
16 posts


The AI API market is fragmented Developers have to manage more than 5 API keys just to access various models I built Aevon to solve that problem: one key, over 30 leading models, compatible with OpenAI Built it myself. It's up and running. Now I'm looking for the right investors to help take this to the next level. If you're investing in AI infrastructure let's connect. aevon.sh #AI #Startup #BuildInPublic


Launching NayanaOCR Corpus 👉🏼 1M+ Document images across 22 languages Largest open source synthetic > multilingual > multimodal > multitask document corpus

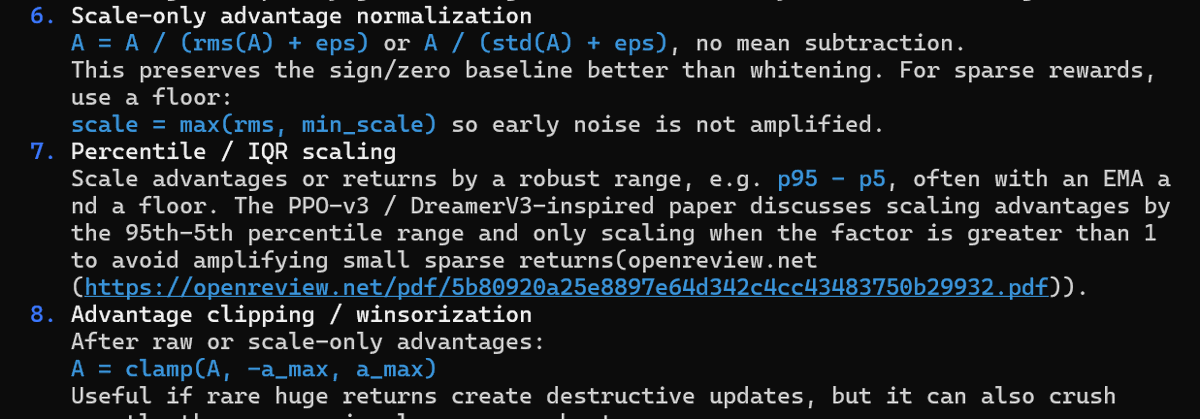












Recently, we took time to consolidate all of the work behind M2 and published it here: our M2 paper on arXiv It’s been just over six months since we first open-sourced M2 on December 23 last year. During that time, a number of our ideas and systems have been broadly adopted by the open-source community — including CISPO, Forge RL System, Self-Evolution. Over the past six months, we’ve felt incredible enthusiasm from the open-source community. Nearly every model release reached the #1 spot on the Hugging Face leaderboard. Now it’s time for a new chapter. We’re getting ready for M3. MSA paper is on the road. arxiv.org/abs/2605.26494



