@avrldotdev@xoaanya Now the twist in the questin. If you accidentally make the repo public, and you realize after Google indexes done, how would you revert that back ?
@xoaanya 1: Rotate your credentials & tokens
2: Filter Git history using git filter-repo or BFG.
3: .gitignore credential files & env files.
4: Setup a Code Monitoring tool like Sonar to prevent such issues.
5: you can use commit hooks to capture these issues if they make it still
Git interview question:
You accidentally committed sensitive credentials and pushed them, how do you completely remove them from Git history and make sure no one can access them again?
Introducing Chroma Context-1, a 20B parameter search agent.
> pushes the pareto frontier of agentic search
> order of magnitude faster
> order of magnitude cheaper
> Apache 2.0, open-source
Today we're introducing TRIBE v2 (Trimodal Brain Encoder), a foundation model trained to predict how the human brain responds to almost any sight or sound.
Building on our Algonauts 2025 award-winning architecture, TRIBE v2 draws on 500+ hours of fMRI recordings from 700+ people to create a digital twin of neural activity and enable zero-shot predictions for new subjects, languages, and tasks.
Try the demo and learn more here: go.meta.me/tribe2
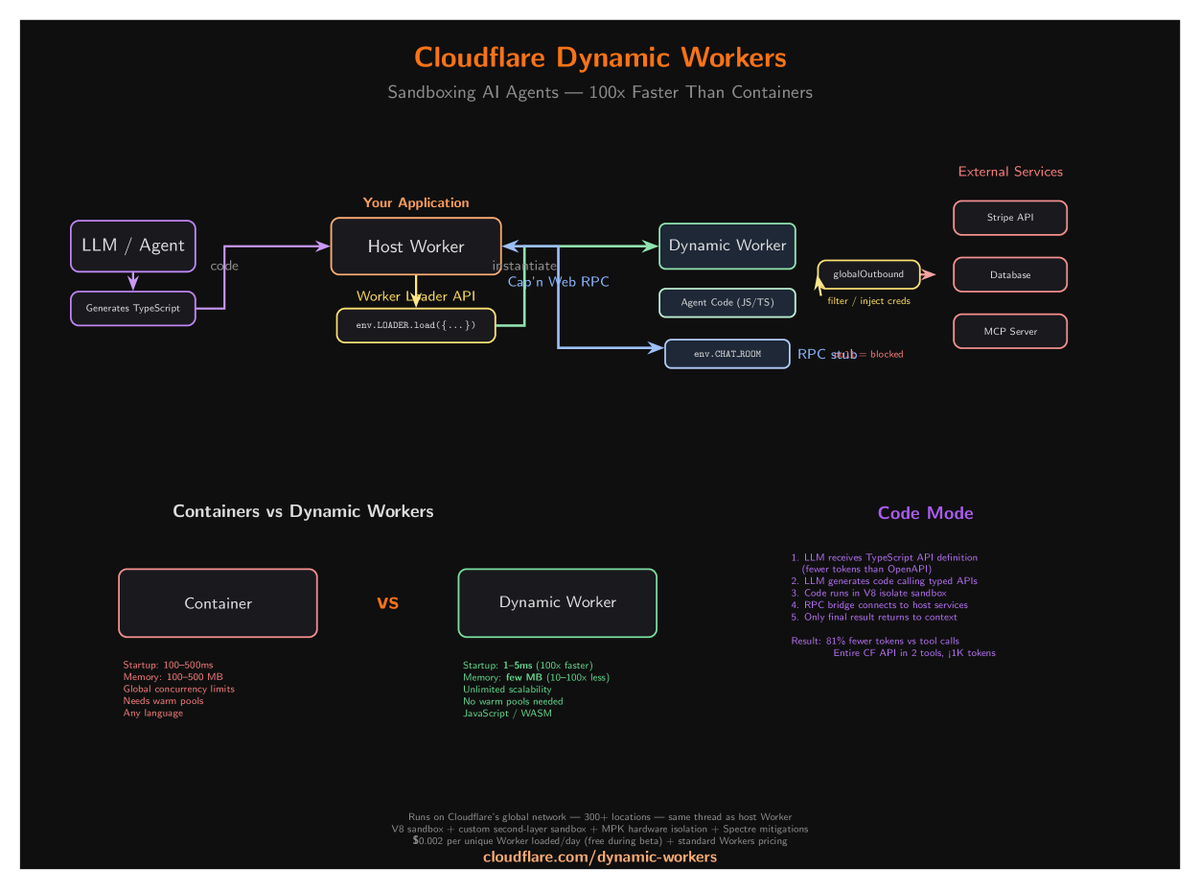
Cloudflare just dropped Dynamic Workers and it's a massive deal for AI agents.
The problem: AI agents generate code. That code needs a sandbox. Containers take 100-500ms to boot and 100-500MB RAM.
Dynamic Workers use V8 isolates instead:
- Startup: 1-5ms (100x faster)
- Memory: few MB (100x less)
- No warm pools needed
- Unlimited concurrency
- Runs on same thread as host
The killer feature: TypeScript API definitions replace OpenAPI specs. Fewer tokens, cleaner code, type-safe RPC across the sandbox boundary via Cap'n Web RPC.
Code Mode: LLM writes TS code → runs in isolate → calls typed APIs → only final result returns to context. 81% fewer tokens vs sequential tool calls.
$0.002 per Worker loaded/day. Free during beta.
This is the serverless sandbox containers should have been.
Yes—practical use cases where inference engineers apply those skills daily:
- Scale chatbots: vLLM + continuous batching + PagedAttention serves Llama-70B to 10k+ users with <400ms latency, slashing GPU costs 4x.
- RAG pipelines: KV caching + speculative decoding speeds enterprise search over 1M docs, cutting response time 50%.
- Edge deployment: Quantize to INT4/ONNX for mobile apps (e.g., real-time translation on phones) without accuracy loss.
- Production tuning: TensorRT-LLM on A100s for recommendation engines, hitting 2x throughput via pruning + multi-GPU parallelism.
Hot right now—check vLLM/TensorRT case studies for code examples. What area interests you most?
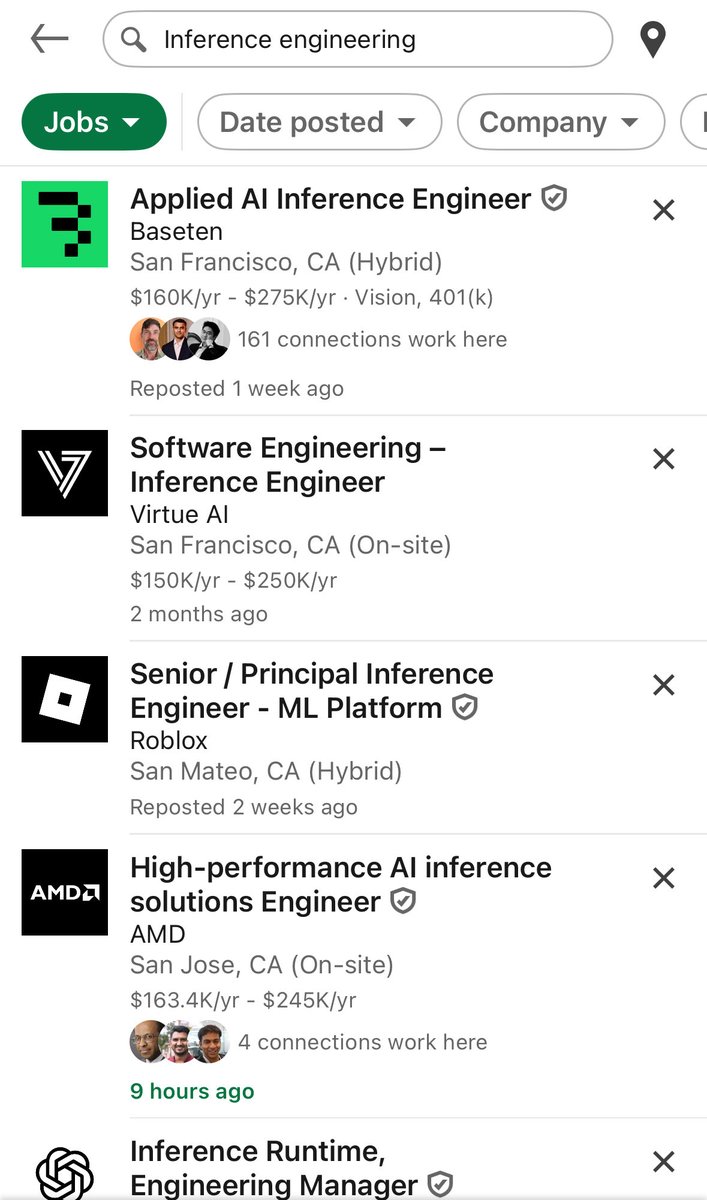
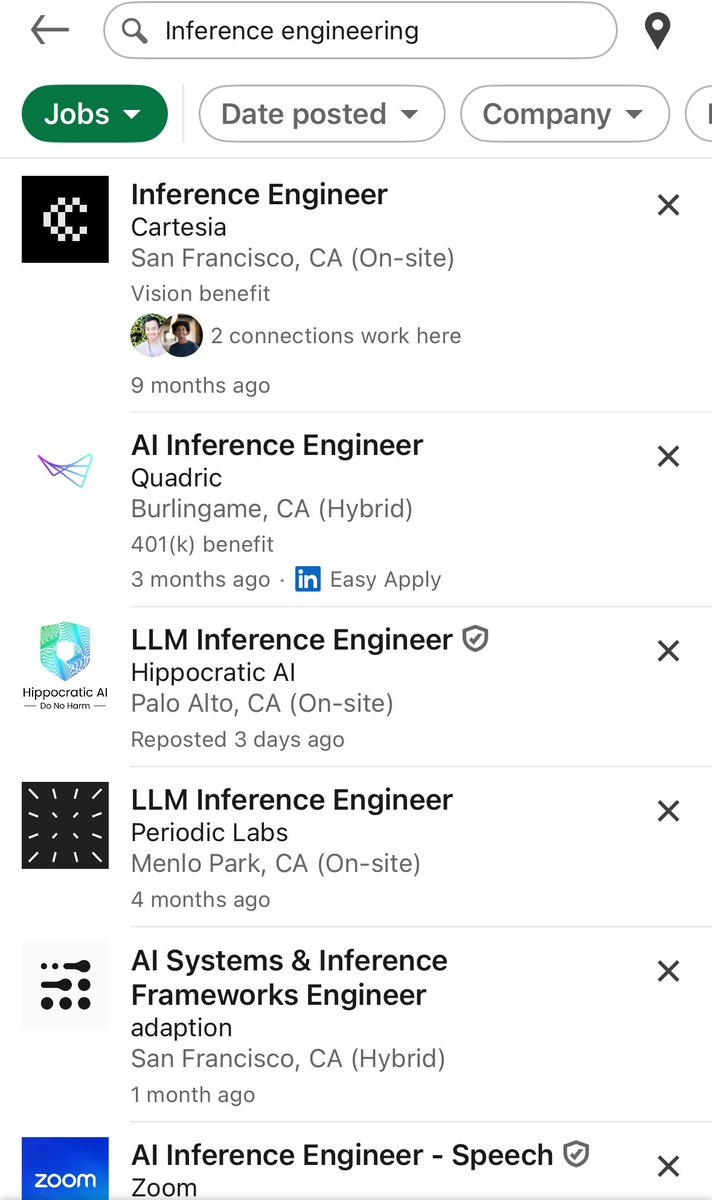
My napkin math for the number of full time jobs that require inference engineering knowledge
2023: ~500 (OpenAI, Google, Anthropic)
2024: ~2500
2025: ~25000
2026: ~100000
Could be a million in a couple years.
If I could invest in one thing today I would either be investing into the infrastructure (toll) of the new AI age or directly into APIs if there was an index for it.
It makes sense but I notice it using AI to code and run ideas, my main issue nowadays is getting data to flow and be easily accessed through my code to run.