Sabitlenmiş Tweet

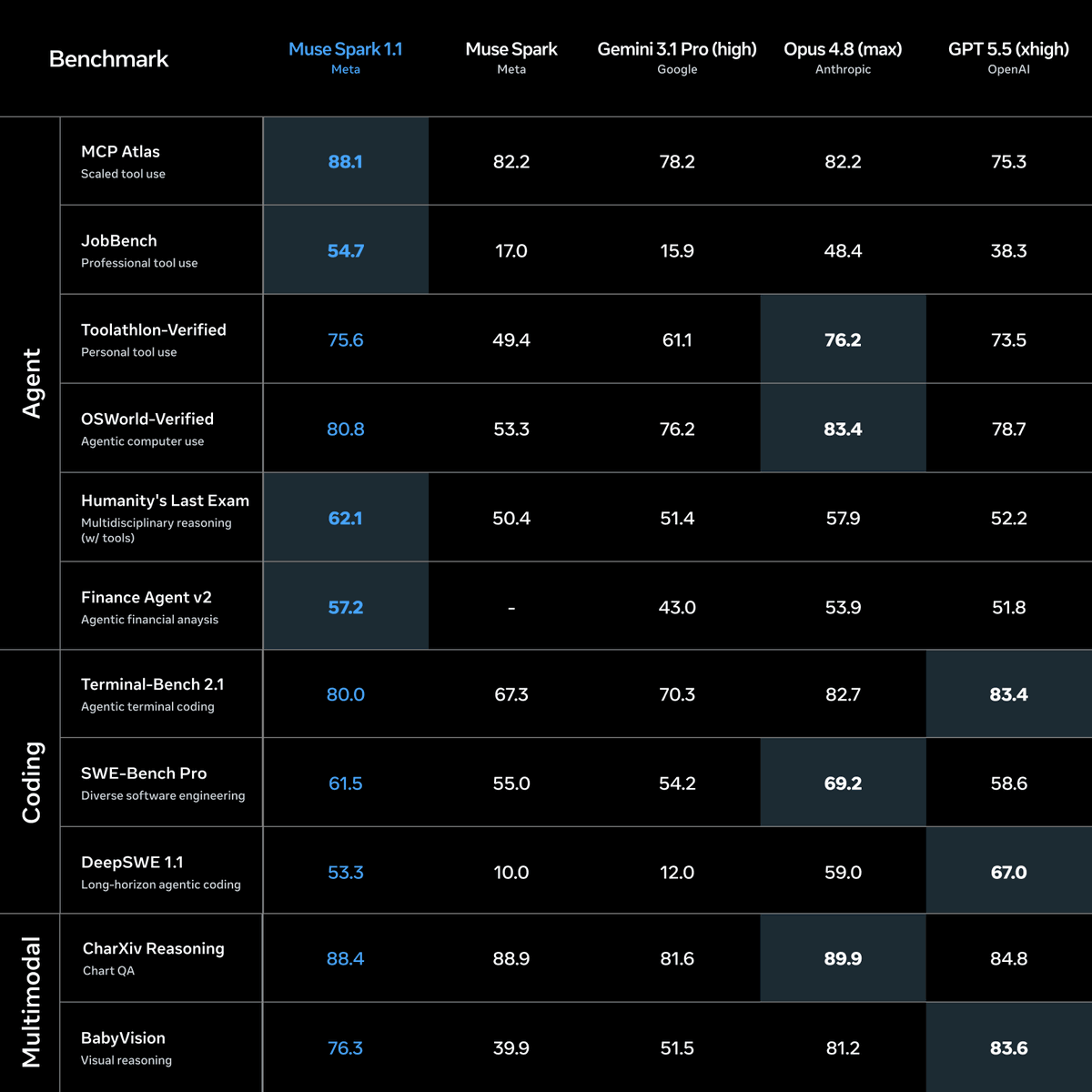
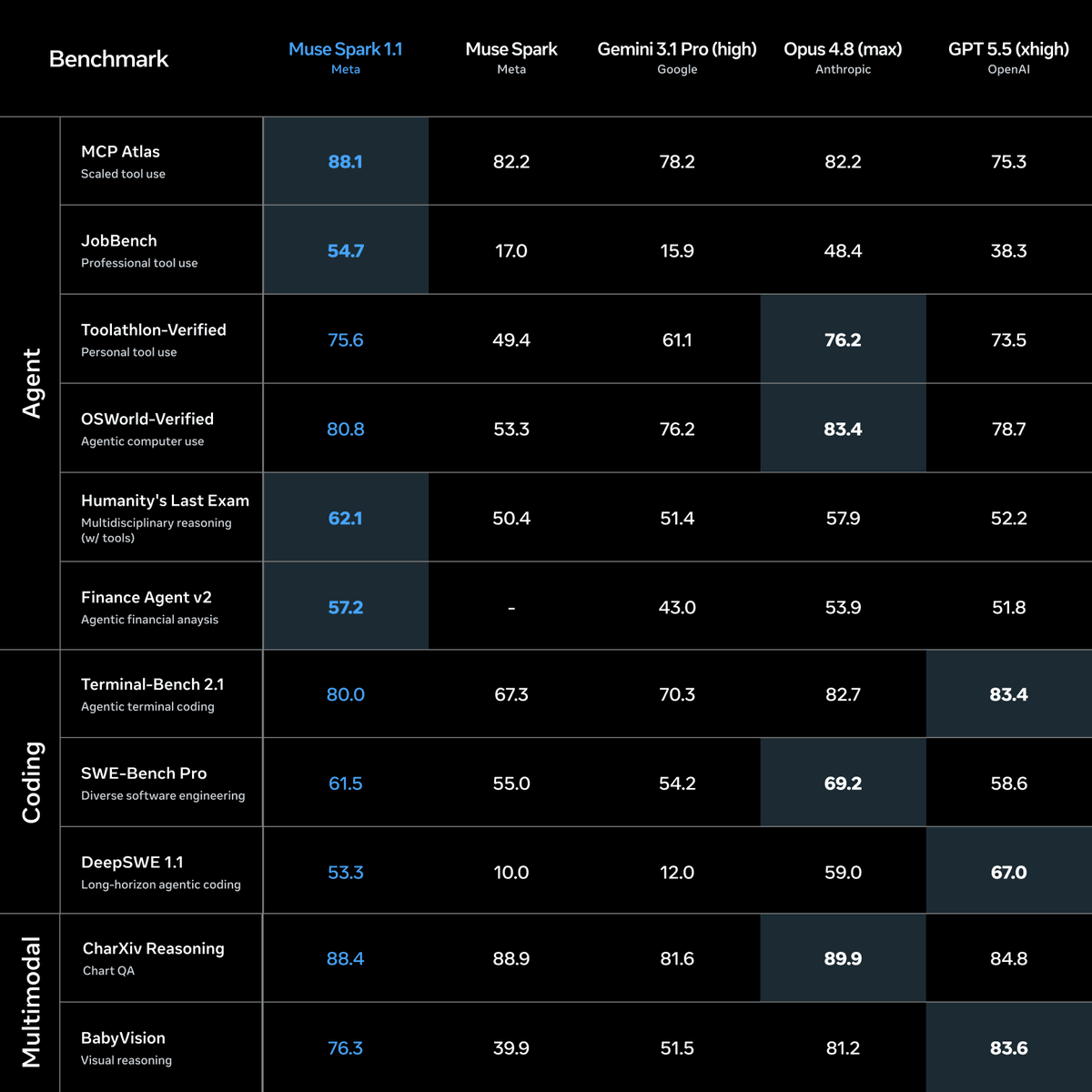
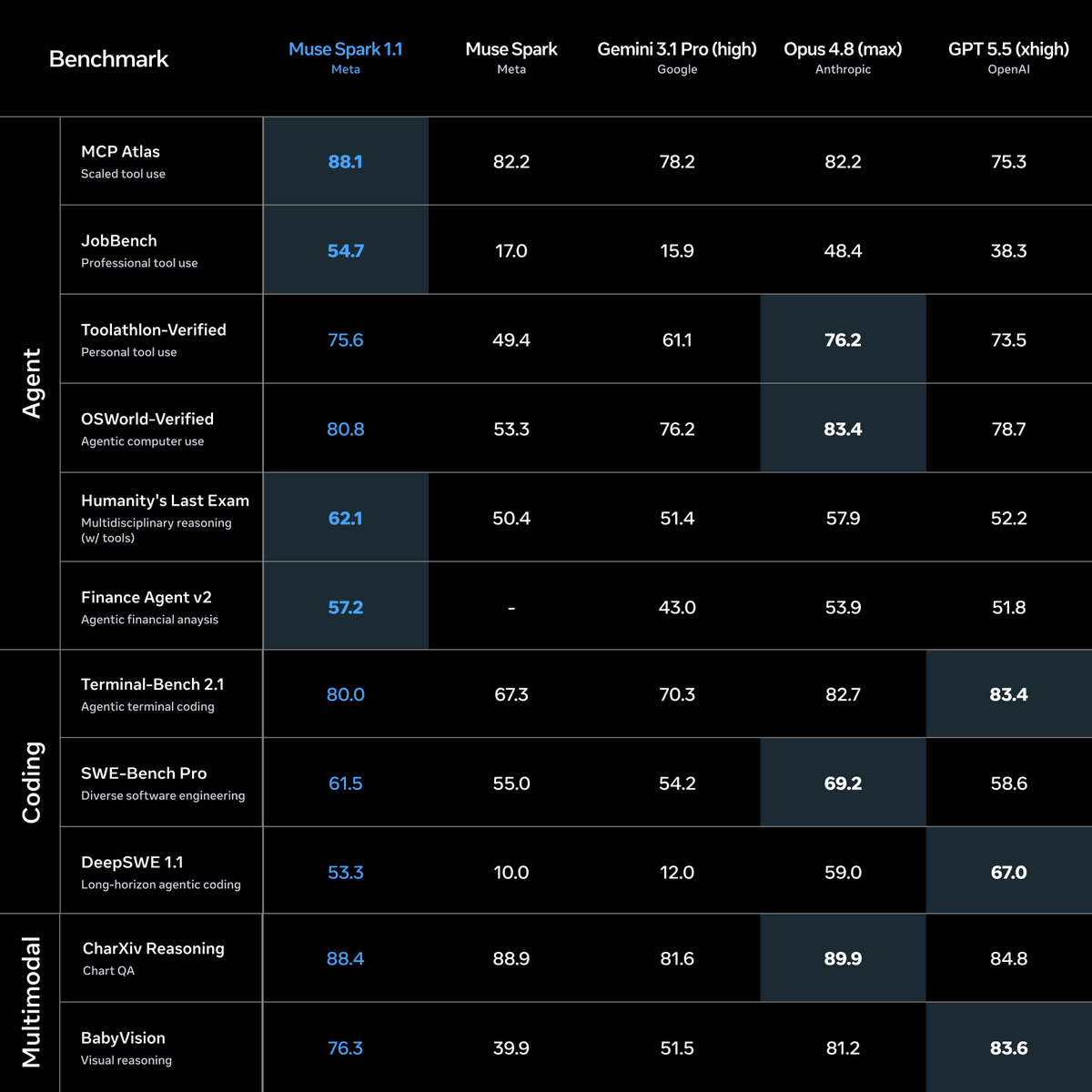
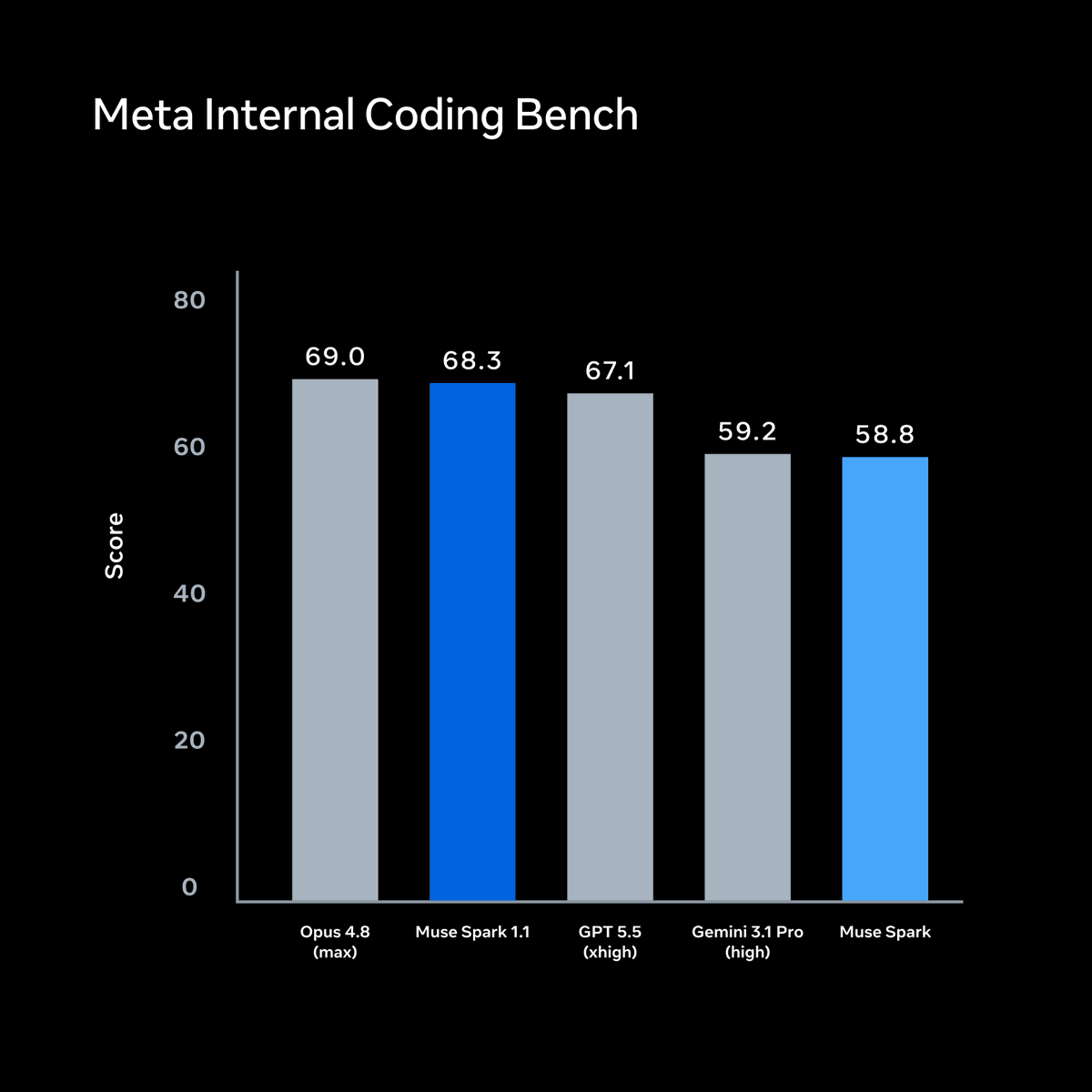
We’re excited to introduce Muse Spark 1.1, a significant upgrade from the first Muse Spark model we released earlier this year.
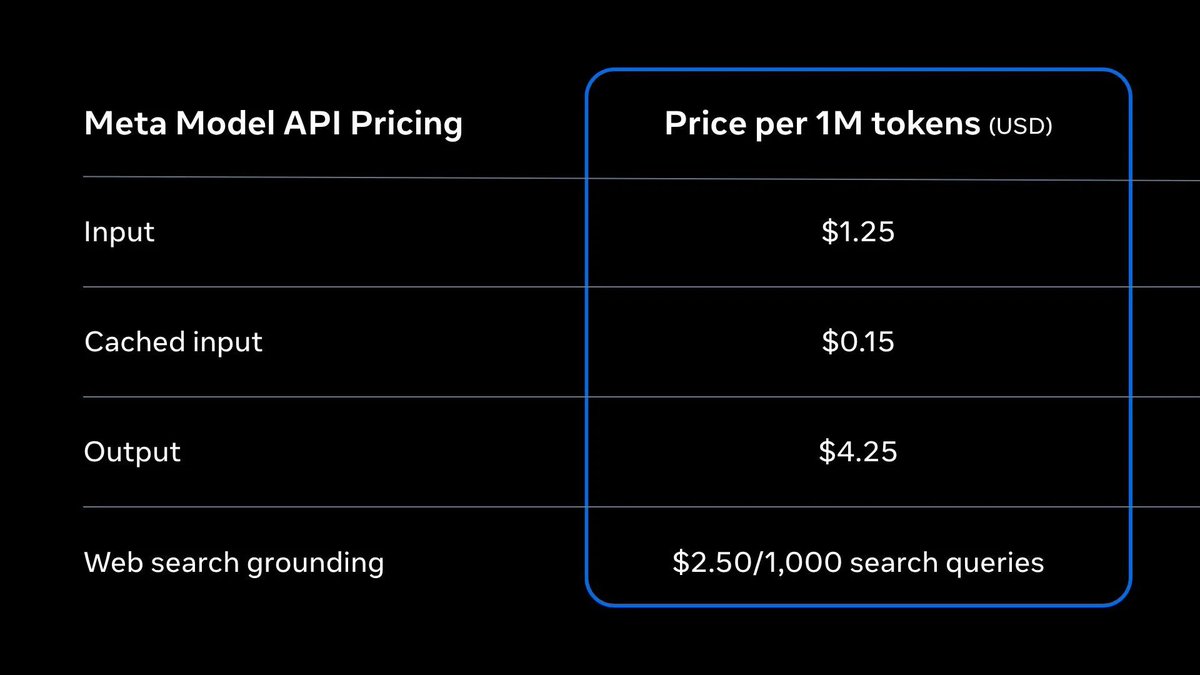
Along with this release, we are launching a public preview of the new Meta Model API where developers can access Muse Spark 1.1.
The model is also available now in "Thinking" mode in the Meta AI app and on meta.ai.
Learn more: go.meta.me/ff8e2c

English