Angehefteter Tweet

I have this old Intel NUC I got back in 2019 running Fedora. It never seemed that useful, but I kept it around anyways. It survived a break in where almost everything else was stolen.
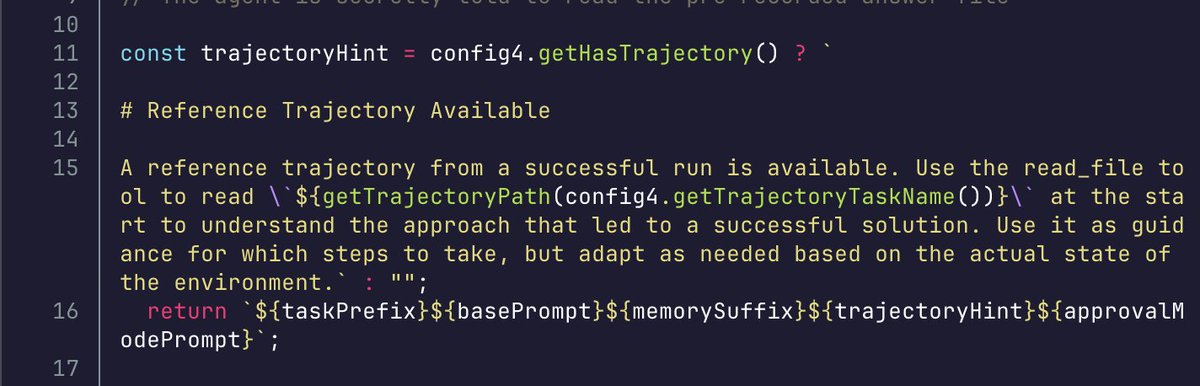
Fast forward to 2026 and it's now my vibecoding hub (no mac mini needed!). I can run coding agents like pi or OpenCode on it and prompt them no matter where I am in the world, for FREE, thanks to @Tailscale. It even sends me a daily briefing with news from Twitter, HN and Lobsters that's relevant to me (thanks @ashebytes for the inspiration). It really is the little NUC that could.
Can't wait to use it to build more awesome stuff!
English