@_Mezamorta_ İran'ın vereceği karşılığa göre değişir cevap açıkçası.
Türkçe
Cuma Cevik
12.7K posts

@cevikfinance
Entrepreneur | Trader & Investor | Not Financial Advice


Stock markets around the world since the war started:
Morgan Stanley on "TurboQuant – Implications for Technology" Analyst comments: "This compression algorithm makes AI inference 8x faster while using 6x less memory. It affects only the KV cache during inference and gives much more output per GPU. The read-through is positive for hyperscalers and LLMs given the ROI opportunity. It is a long-term positive for computing and memory. Implications for memory: neutral to positive long term Short-term impact: TurboQuant targets only the Key Value (KV) cache during inference, which is the temporary key/value vector that grows with context length. Model weights, including HBM usage on GPU/TPU, and training workloads are not affected. It allows 4-8x longer context on the same hardware, or much larger batch sizes, without running out of memory. This is not a 6x reduction in memory or total hardware needed, but an efficiency gain that increases throughput per GPU. Long-term impact: The Jevons paradox effect is that efficiency increases total demand. The inference economics are shifting: by shrinking data size and movement, TurboQuant aims to improve throughput per accelerator and lower cost per query. The biggest bottleneck in scaling AI services today is KV cache memory. If models can run with materially lower memory requirements without losing performance, the cost of serving each query drops meaningfully, resulting in more profitable AI deployment. Models that need cloud clusters can fit on local hardware, effectively lowering the barrier to deploying AI at scale. More applications become viable, more models remain active, and utilization of existing infrastructure improves. In that sense, TurboQuant is less about incremental optimization and more about shifting the cost curve of AI deployment. Broader tech implications: another DeepSeek moment Positive for hyperscalers and model platforms: We cite the ROI opportunity from much cheaper per-unit quality in long-context inference and retrieval-heavy applications. Neutral near-term implications for computing and memory: Better compression means lower memory traffic and lower GPU-hours requirement per workload. However, a lower cost per token can also lead to higher product adoption demand, including larger batch sizes and longer context. This may be negative at the margin for the software layer, as compression can be embedded directly into platform infrastructure."

🚨"RAM": Fiyatları Düşüyor 🚨 Çünkü Google'ın bellek kullanımını 6 kat azaltan ve hızı 8 kat artıran bir yapay zeka algoritması geliştirdiğini duyurmasının ardından RAM şirketlerinin hisse senetleri düştü ve milyonlarca dolarlık zarar bildirdiler.

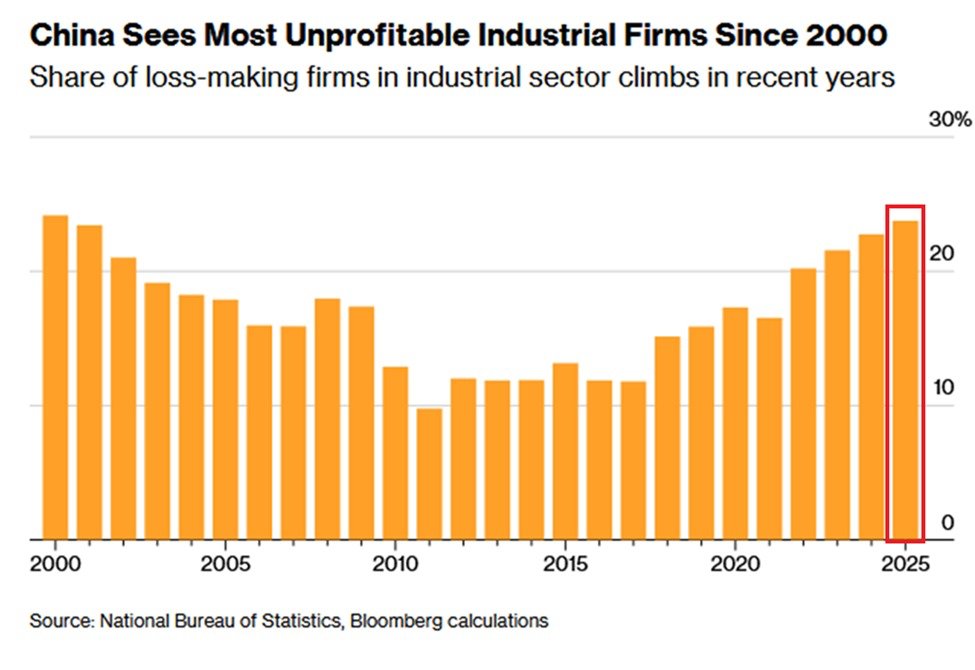






London house prices fell for the sixth consecutive month and at the fastest pace in nearly two years. Rising unemployment, higher interest rates, the new Mansion & higher 2nd home taxes, Rental reform & bleak economic outlook. ft.com/content/0ae454…
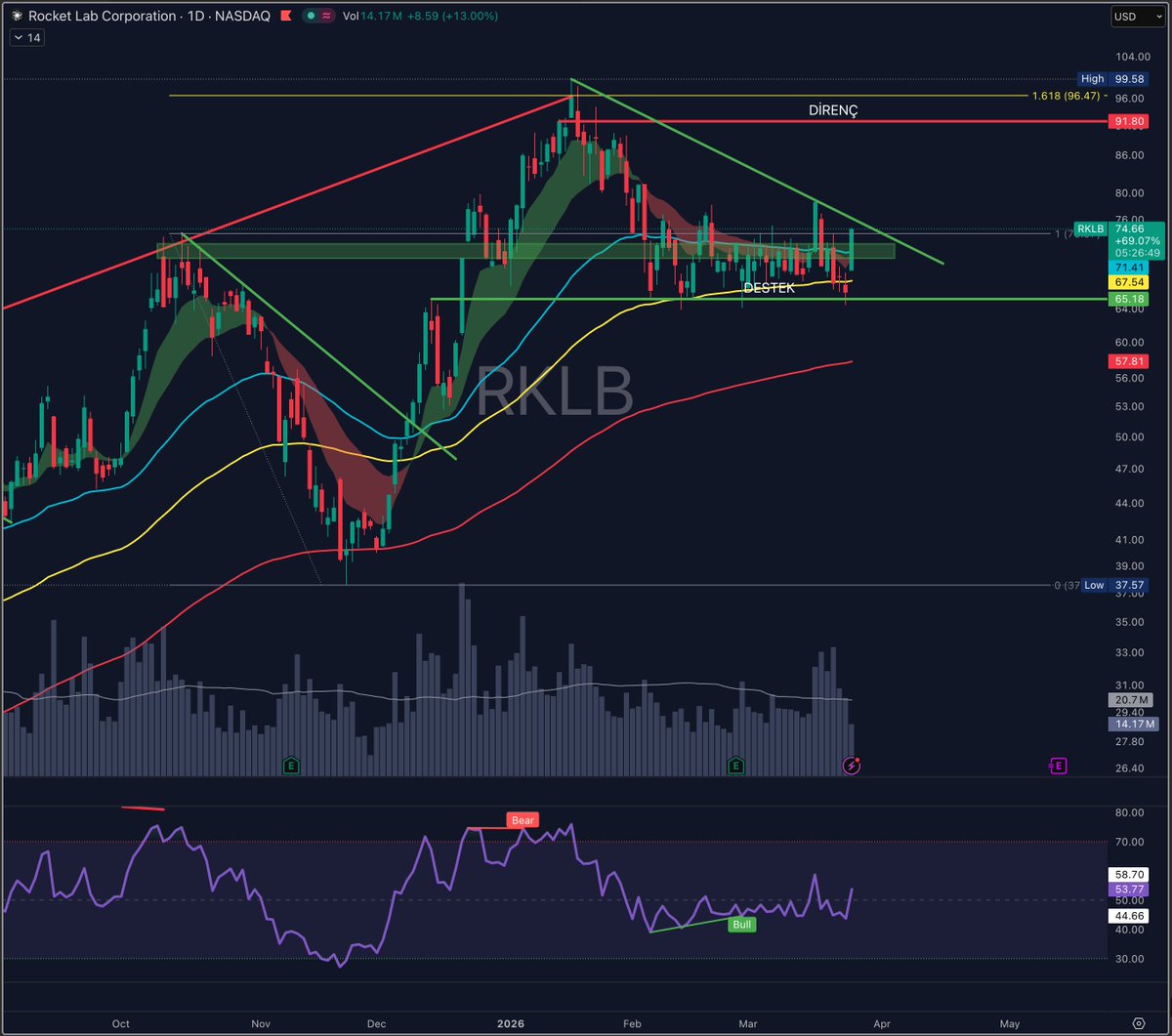
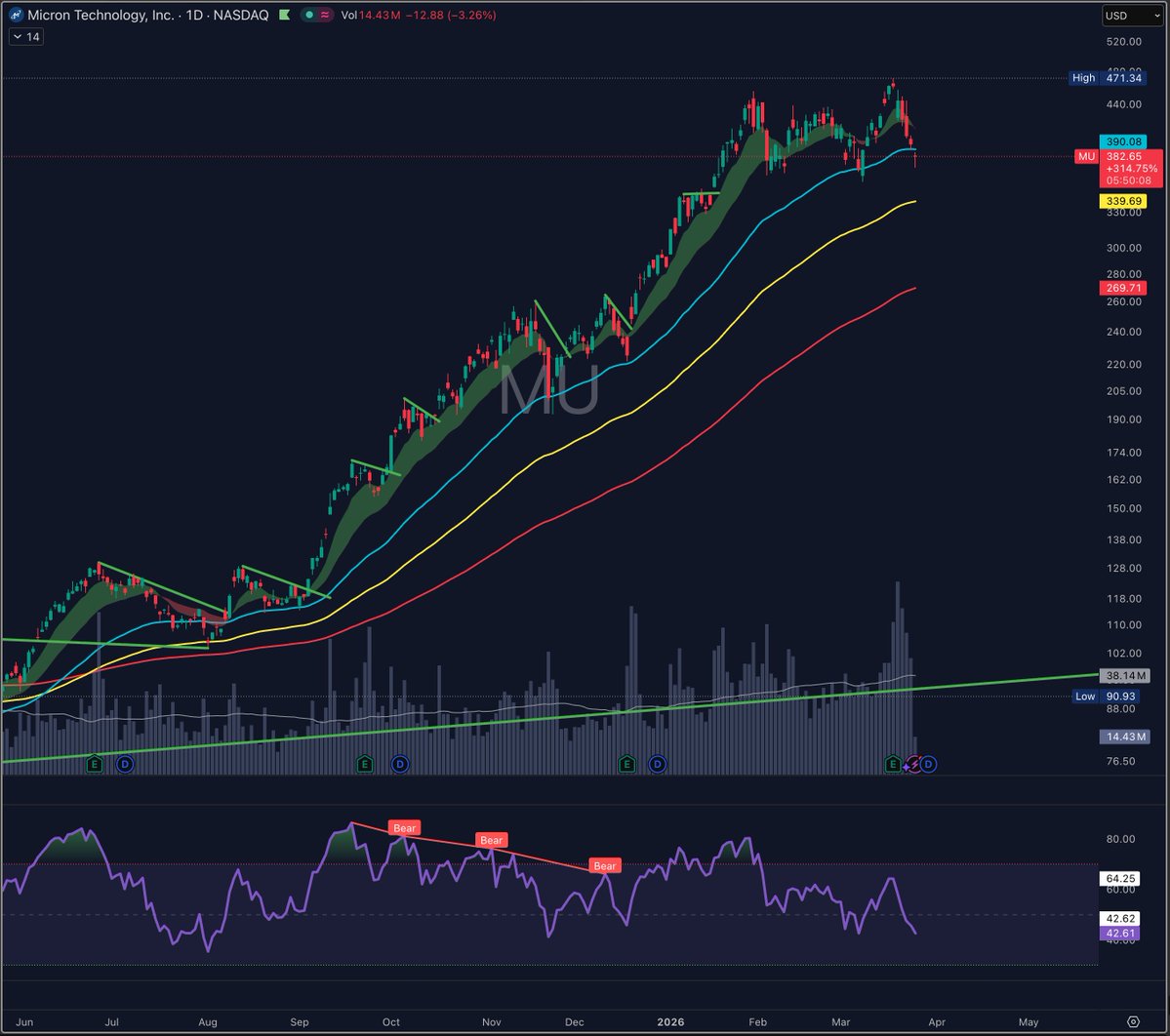
$MU ve $SNDK, $GOOGL’un TurboQuant duyurusunun ardından açılışta sert baskı altında. Piyasa bu gelişmeyi, özellikle long-context AI inference tarafında “memory verimliliğinde sıçrama” olarak fiyatlıyor. TurboQuant gibi çözümler, KV cache kullanımını optimize ederek model başına gereken bellek footprint’ini ciddi şekilde aşağı çekebilir. Bu da özellikle HBM ve yüksek bant genişlikli DRAM talebinin uzun vadeli büyüme hızına soru işareti koyuyor. Ancak burada ince bir detay var: Bu tarz optimizasyonlar toplam compute talebini artırabilir (daha fazla inference yapılabilir hale gelir) Yani kısa vadede “memory intensity ↓”, uzun vadede ise “total workload ↑” senaryosu oluşabilir