Angehefteter Tweet

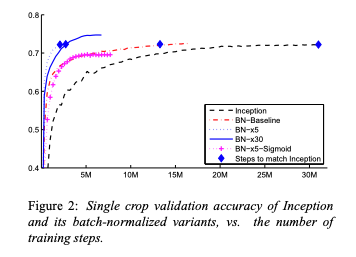
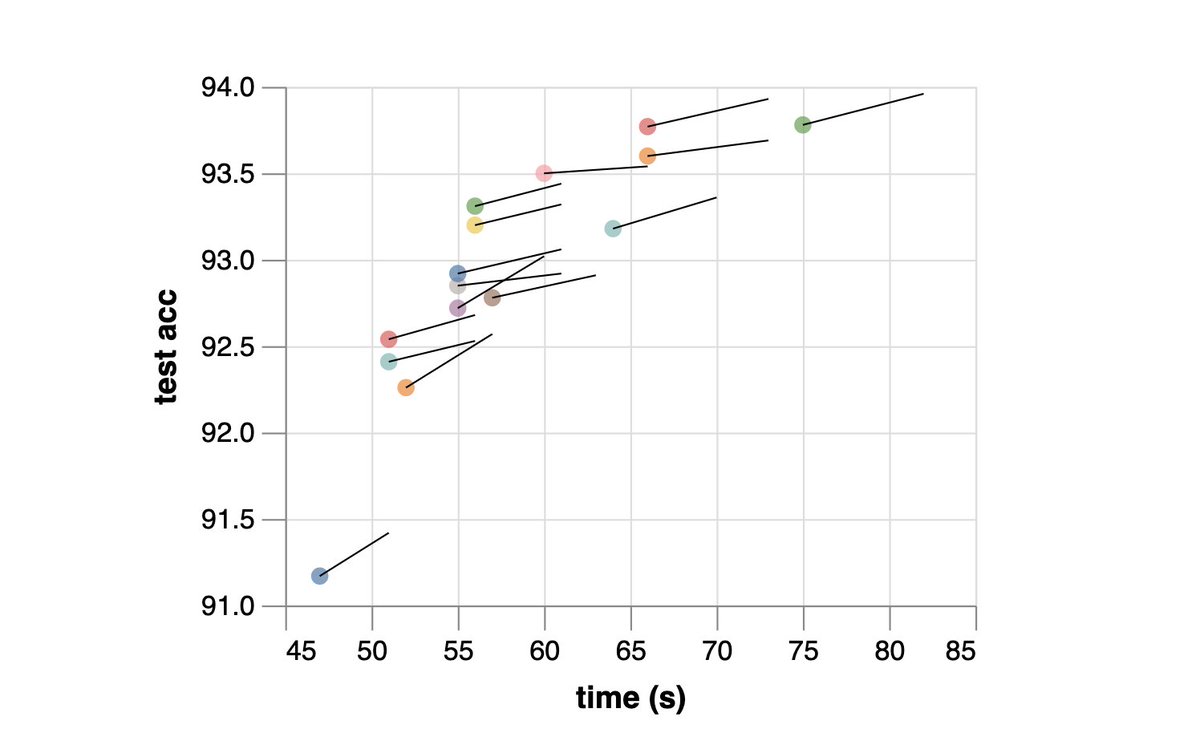
Ever wanted to train CIFAR10 to 94% in 26 SECONDS on a single-GPU?!
In the final post of our ResNet series, we open a bag of tricks and drive training time ever closer to zero...
Colab: colab.research.google.com/github/davidcp…
Blog: myrtle.ai/how-to-train-y…
English