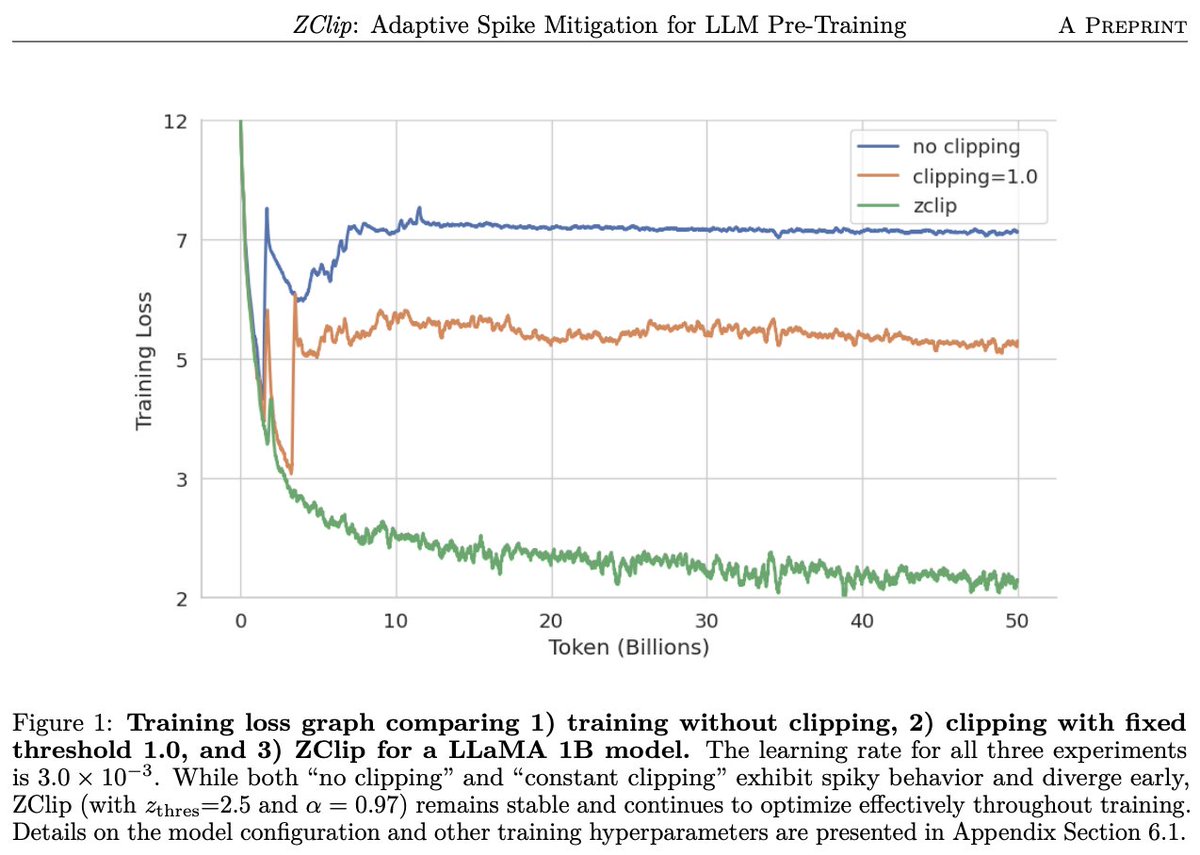
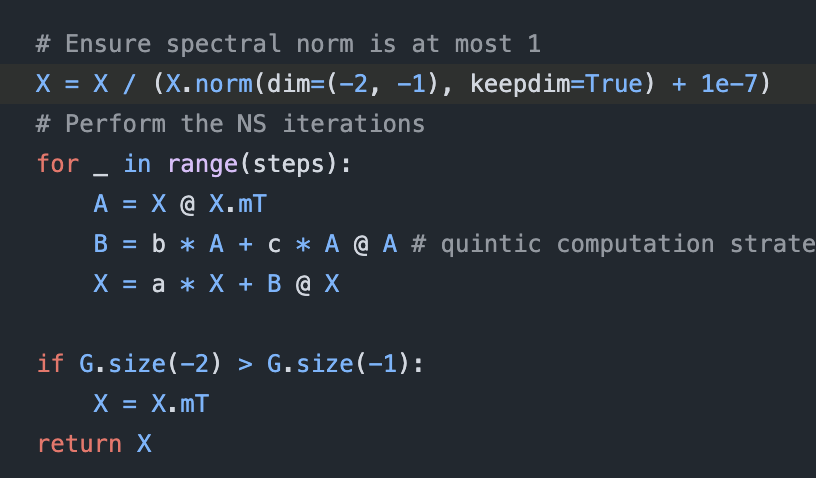
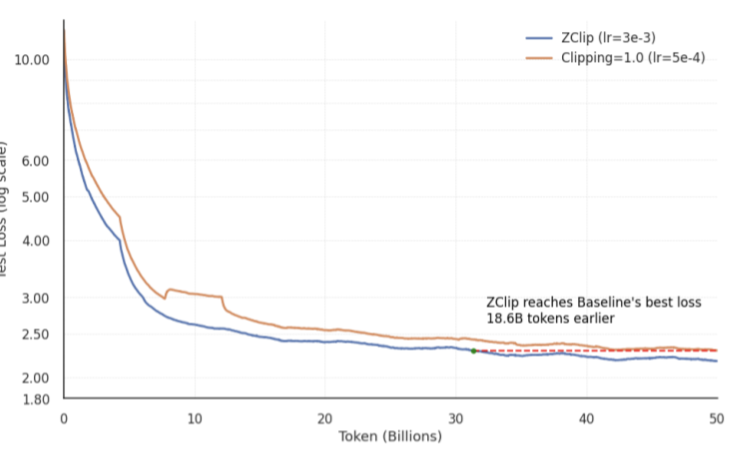
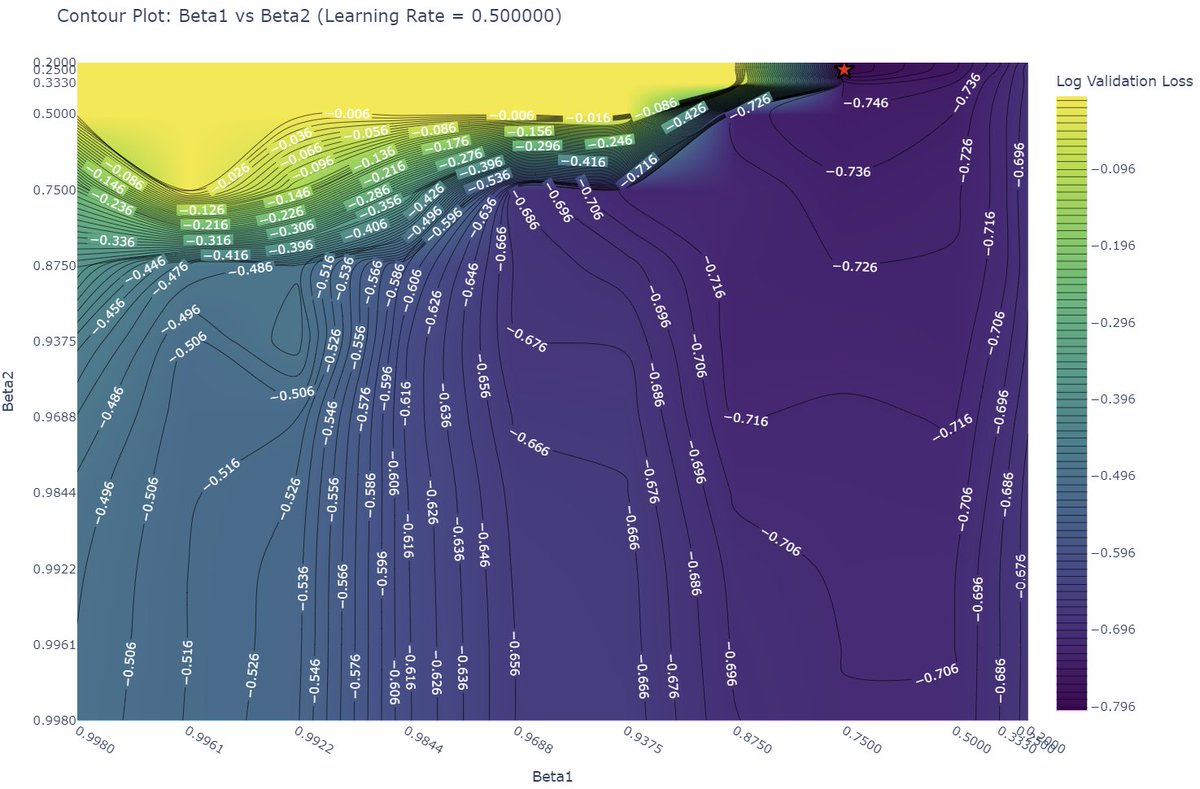
Sabitlenmiş Tweet

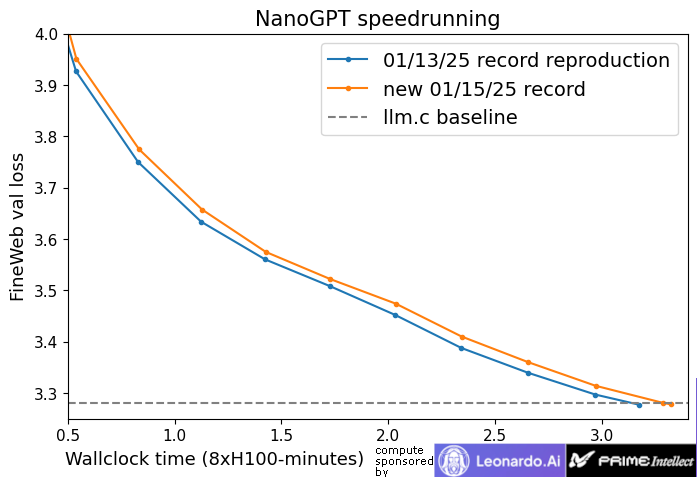
New NanoGPT training speed record: 3.28 FineWeb val loss in 3.17 minutes on 8xH100
Previous record (recreation): 3.32 minutes
Lots of changes!
- New token-dependent lm_head bias
- Fused several ops
- Multi-GPU grad bugfix
- Steps 1390 -> 1350
- Semi-ortho init
- (More in thread)
English