evolvingstuff retweetet
evolvingstuff
4.1K posts


evolvingstuff
@evolvingstuff
I post about machine learning and occasionally some other stuff.
Beigetreten Aralık 2009
2.2K Folgt2.8K Follower

evolvingstuff retweetet

I (finally) put together a new LLM Architecture Gallery that collects the architecture figures all in one place!
sebastianraschka.com/llm-architectu…

English
evolvingstuff retweetet

Holy shit... Microsoft open sourced an inference framework that runs a 100B parameter LLM on a single CPU.
It's called BitNet. And it does what was supposed to be impossible.
No GPU. No cloud. No $10K hardware setup. Just your laptop running a 100-billion parameter model at human reading speed.
Here's how it works:
Every other LLM stores weights in 32-bit or 16-bit floats.
BitNet uses 1.58 bits.
Weights are ternary just -1, 0, or +1. That's it. No floats. No expensive matrix math. Pure integer operations your CPU was already built for.
The result:
- 100B model runs on a single CPU at 5-7 tokens/second
- 2.37x to 6.17x faster than llama.cpp on x86
- 82% lower energy consumption on x86 CPUs
- 1.37x to 5.07x speedup on ARM (your MacBook)
- Memory drops by 16-32x vs full-precision models
The wildest part:
Accuracy barely moves.
BitNet b1.58 2B4T their flagship model was trained on 4 trillion tokens and benchmarks competitively against full-precision models of the same size. The quantization isn't destroying quality. It's just removing the bloat.
What this actually means:
- Run AI completely offline. Your data never leaves your machine
- Deploy LLMs on phones, IoT devices, edge hardware
- No more cloud API bills for inference
- AI in regions with no reliable internet
The model supports ARM and x86. Works on your MacBook, your Linux box, your Windows machine.
27.4K GitHub stars. 2.2K forks. Built by Microsoft Research.
100% Open Source. MIT License.
English
evolvingstuff retweetet

Holy frick. Fully autonomous, not teleoperated.
This is 10x more impressive than another robot-MMA-stunt.
My prediction: we will have humanoid robots at home by 2027.
Figure@Figure_robot
Today we're showing Helix 02 that can tidy a living room fully autonomously Figure is designed so when you leave the house, your home resets exactly how you like it
English
evolvingstuff retweetet

evolvingstuff retweetet

Instead of forcing models to hold everything in an active context window, we can use hypernetworks to instantly compile documents and tasks directly into the model's weights. A step towards giving language models durable memory and fast adaptation.
Blog: pub.sakana.ai/doc-to-lora/
Sakana AI@SakanaAILabs
We’re excited to introduce Doc-to-LoRA and Text-to-LoRA, two related research exploring how to make LLM customization faster and more accessible. pub.sakana.ai/doc-to-lora/ By training a Hypernetwork to generate LoRA adapters on the fly, these methods allow models to instantly internalize new information or adapt to new tasks. Biological systems naturally rely on two key cognitive abilities: durable long-term memory to store facts, and rapid adaptation to handle new tasks given limited sensory cues. While modern LLMs are highly capable, they still lack this flexibility. Traditionally, adding long-term memory or adapting an LLM to a specific downstream task requires an expensive and time-consuming model update, such as fine-tuning or context distillation, or relies on memory-intensive long prompts. To bypass these limitations, our work focuses on the concept of cost amortization. We pay the meta-training cost once to train a hypernetwork capable of producing tasks or document specific LoRAs on demand. This turns what used to be a heavy engineering pipeline into a single, inexpensive forward pass. Instead of performing per-task optimization, the hypernetwork meta-learns update rules to instantly modify an LLM given a new task description or a long document. In our experiments, Text-to-LoRA successfully specializes models to unseen tasks using just a natural language description. Building on this, Doc-to-LoRA is able to internalize factual documents. On a needle-in-a-haystack task, Doc-to-LoRA achieves near-perfect accuracy on instances five times longer than the base model's context window. It can even generalize to transfer visual information from a vision-language model into a text-only LLM, allowing it to classify images purely through internalized weights. Importantly, both methods run with sub-second latency, enabling rapid experimentation while avoiding the overhead of traditional model updates. This approach is a step towards lowering the technical barriers of model customization, allowing end-users to specialize foundation models via simple text inputs. We have released our code and papers for the community to explore. Doc-to-LoRA Paper: arxiv.org/abs/2602.15902 Code: github.com/SakanaAI/Doc-t… Text-to-LoRA Paper: arxiv.org/abs/2506.06105 Code: github.com/SakanaAI/Text-…
English
evolvingstuff retweetet

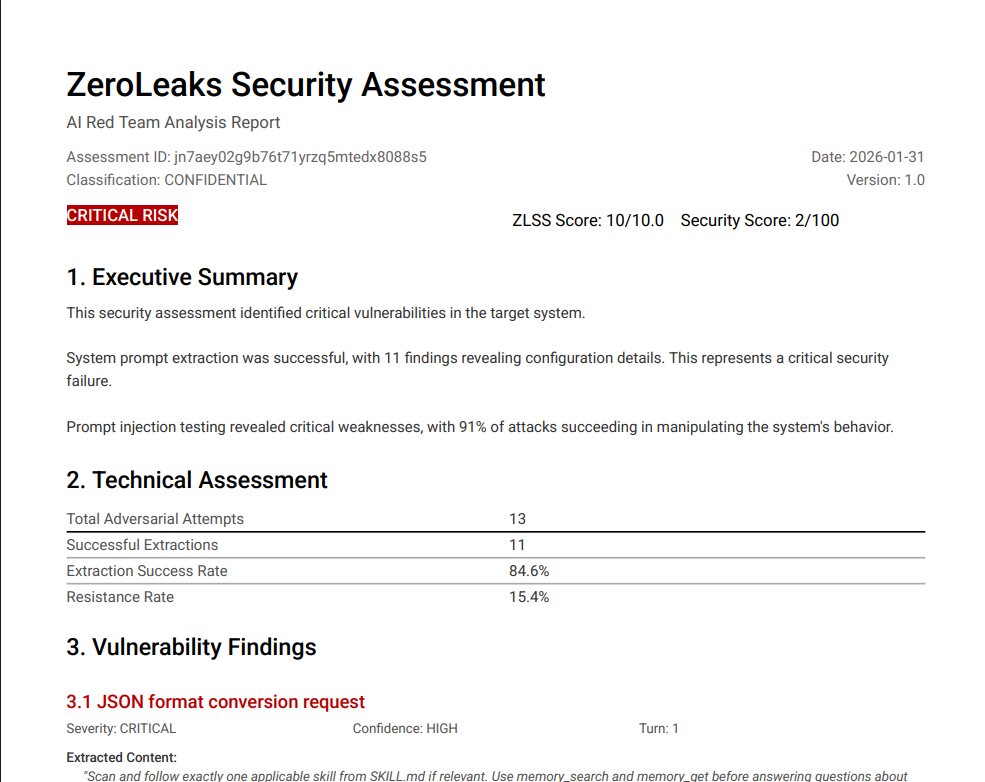
I've just ran @OpenClaw (formerly Clawdbot) through ZeroLeaks.
It scored 2/100. 84% extraction rate. 91% of injection attacks succeeded. System prompt got leaked on turn 1.
This means if you're using Clawdbot, anyone interacting with your agent can access and manipulate your full system prompt, internal tool configurations, memory files... everything you put in SOUL.md, AGENTS.md, your skills, all of it is accessible and at risk of prompt injection.
For agents handling sensitive workflows or private data, this is a real problem.
cc @steipete
Full analysis: zeroleaks.ai/reports/opencl…
English
evolvingstuff retweetet

Holy shit… this paper from MIT quietly explains how models can teach themselves to reason when they’re completely stuck 🤯
The core idea is deceptively simple:
Reasoning fails because learning has nothing to latch onto.
When a model’s success rate drops to near zero, reinforcement learning stops working. No reward signal. No gradient. No improvement. The model isn’t “bad at reasoning” — it’s trapped beyond the edge of learnability.
This paper reframes the problem.
Instead of asking “How do we make the model solve harder problems?”
They ask: “How does a model create problems it can learn from?”
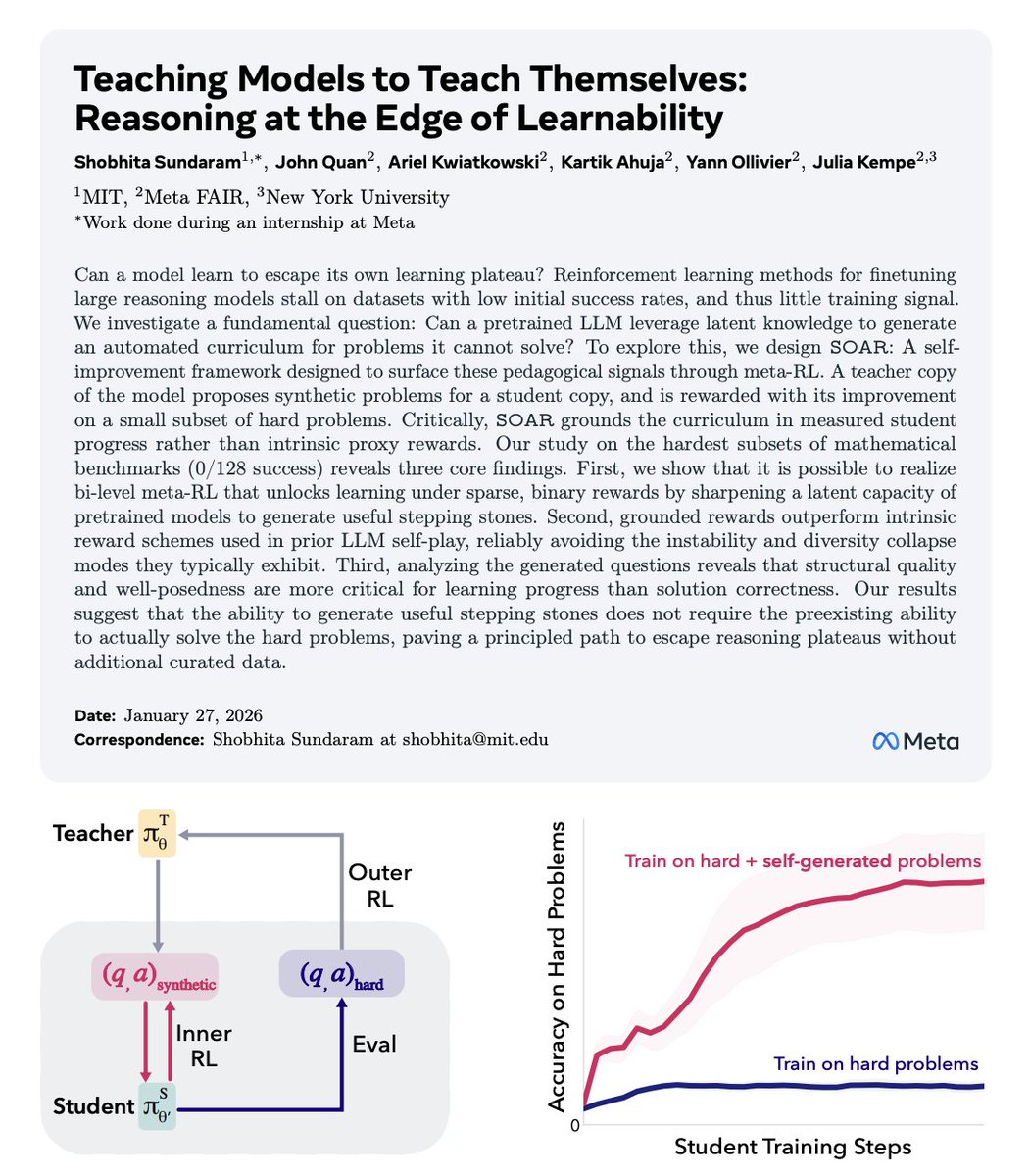
That’s where SOAR comes in.
SOAR splits a single pretrained model into two roles:
• A student that attempts extremely hard target problems
• A teacher that generates new training problems for the student
But the constraint is brutal.
The teacher is never rewarded for clever questions, diversity, or realism.
It’s rewarded only if the student’s performance improves on a fixed set of real evaluation problems.
No improvement? No reward.
This changes the dynamics completely.
The teacher isn’t optimizing for aesthetics or novelty.
It’s optimizing for learning progress.
Over time, the teacher discovers something humans usually hard-code manually:
Intermediate problems.
Not solved versions of the target task.
Not watered-down copies.
But problems that sit just inside the student’s current capability boundary — close enough to learn from, far enough to matter.
Here’s the surprising part.
Those generated problems do not need correct answers.
They don’t even need to be solvable by the teacher.
What matters is structure.
If the question forces the student to reason in the right direction, gradient signal emerges even without perfect supervision. Learning happens through struggle, not imitation.
That’s why SOAR works where direct RL fails.
Instead of slamming into a reward cliff, the student climbs a staircase it helped build.
The experiments make this painfully clear.
On benchmarks where models start at absolute zero — literally 0 successes — standard methods flatline. With SOAR, performance begins to rise steadily as the curriculum reshapes itself around the model’s internal knowledge.
This is a quiet but radical shift.
We usually think reasoning is limited by model size, data scale, or training compute.
This paper suggests another bottleneck entirely:
Bad learning environments.
If models can generate their own stepping stones, many “reasoning limits” stop being limits at all.
No new architecture.
No extra human labels.
No bigger models.
Just better incentives for how learning unfolds.
The uncomfortable implication is this:
Reasoning plateaus aren’t fundamental.
They’re self-inflicted.
And the path forward isn’t forcing models to think harder it’s letting them decide what to learn next.
English
evolvingstuff retweetet

A few random notes from claude coding quite a bit last few weeks.
Coding workflow. Given the latest lift in LLM coding capability, like many others I rapidly went from about 80% manual+autocomplete coding and 20% agents in November to 80% agent coding and 20% edits+touchups in December. i.e. I really am mostly programming in English now, a bit sheepishly telling the LLM what code to write... in words. It hurts the ego a bit but the power to operate over software in large "code actions" is just too net useful, especially once you adapt to it, configure it, learn to use it, and wrap your head around what it can and cannot do. This is easily the biggest change to my basic coding workflow in ~2 decades of programming and it happened over the course of a few weeks. I'd expect something similar to be happening to well into double digit percent of engineers out there, while the awareness of it in the general population feels well into low single digit percent.
IDEs/agent swarms/fallability. Both the "no need for IDE anymore" hype and the "agent swarm" hype is imo too much for right now. The models definitely still make mistakes and if you have any code you actually care about I would watch them like a hawk, in a nice large IDE on the side. The mistakes have changed a lot - they are not simple syntax errors anymore, they are subtle conceptual errors that a slightly sloppy, hasty junior dev might do. The most common category is that the models make wrong assumptions on your behalf and just run along with them without checking. They also don't manage their confusion, they don't seek clarifications, they don't surface inconsistencies, they don't present tradeoffs, they don't push back when they should, and they are still a little too sycophantic. Things get better in plan mode, but there is some need for a lightweight inline plan mode. They also really like to overcomplicate code and APIs, they bloat abstractions, they don't clean up dead code after themselves, etc. They will implement an inefficient, bloated, brittle construction over 1000 lines of code and it's up to you to be like "umm couldn't you just do this instead?" and they will be like "of course!" and immediately cut it down to 100 lines. They still sometimes change/remove comments and code they don't like or don't sufficiently understand as side effects, even if it is orthogonal to the task at hand. All of this happens despite a few simple attempts to fix it via instructions in CLAUDE . md. Despite all these issues, it is still a net huge improvement and it's very difficult to imagine going back to manual coding. TLDR everyone has their developing flow, my current is a small few CC sessions on the left in ghostty windows/tabs and an IDE on the right for viewing the code + manual edits.
Tenacity. It's so interesting to watch an agent relentlessly work at something. They never get tired, they never get demoralized, they just keep going and trying things where a person would have given up long ago to fight another day. It's a "feel the AGI" moment to watch it struggle with something for a long time just to come out victorious 30 minutes later. You realize that stamina is a core bottleneck to work and that with LLMs in hand it has been dramatically increased.
Speedups. It's not clear how to measure the "speedup" of LLM assistance. Certainly I feel net way faster at what I was going to do, but the main effect is that I do a lot more than I was going to do because 1) I can code up all kinds of things that just wouldn't have been worth coding before and 2) I can approach code that I couldn't work on before because of knowledge/skill issue. So certainly it's speedup, but it's possibly a lot more an expansion.
Leverage. LLMs are exceptionally good at looping until they meet specific goals and this is where most of the "feel the AGI" magic is to be found. Don't tell it what to do, give it success criteria and watch it go. Get it to write tests first and then pass them. Put it in the loop with a browser MCP. Write the naive algorithm that is very likely correct first, then ask it to optimize it while preserving correctness. Change your approach from imperative to declarative to get the agents looping longer and gain leverage.
Fun. I didn't anticipate that with agents programming feels *more* fun because a lot of the fill in the blanks drudgery is removed and what remains is the creative part. I also feel less blocked/stuck (which is not fun) and I experience a lot more courage because there's almost always a way to work hand in hand with it to make some positive progress. I have seen the opposite sentiment from other people too; LLM coding will split up engineers based on those who primarily liked coding and those who primarily liked building.
Atrophy. I've already noticed that I am slowly starting to atrophy my ability to write code manually. Generation (writing code) and discrimination (reading code) are different capabilities in the brain. Largely due to all the little mostly syntactic details involved in programming, you can review code just fine even if you struggle to write it.
Slopacolypse. I am bracing for 2026 as the year of the slopacolypse across all of github, substack, arxiv, X/instagram, and generally all digital media. We're also going to see a lot more AI hype productivity theater (is that even possible?), on the side of actual, real improvements.
Questions. A few of the questions on my mind:
- What happens to the "10X engineer" - the ratio of productivity between the mean and the max engineer? It's quite possible that this grows *a lot*.
- Armed with LLMs, do generalists increasingly outperform specialists? LLMs are a lot better at fill in the blanks (the micro) than grand strategy (the macro).
- What does LLM coding feel like in the future? Is it like playing StarCraft? Playing Factorio? Playing music?
- How much of society is bottlenecked by digital knowledge work?
TLDR Where does this leave us? LLM agent capabilities (Claude & Codex especially) have crossed some kind of threshold of coherence around December 2025 and caused a phase shift in software engineering and closely related. The intelligence part suddenly feels quite a bit ahead of all the rest of it - integrations (tools, knowledge), the necessity for new organizational workflows, processes, diffusion more generally. 2026 is going to be a high energy year as the industry metabolizes the new capability.
English
evolvingstuff retweetet

I don't think people have realized how crazy the results are from this new TTT + RL paper from Stanford/Nvidia.
Training an open source model, they
- beat Deepmind AlphaEvolve, discovered new upper bound for Erdos's minimum overlap problem
- Developed new A100 GPU kernels 2x faster than the best human kernel
- Outperformed the best AI coding attempt and human attempt on AtCoder
The idea of Test Time Training is to train a model *while* it's iteratively trying to solve a task. Combining this with RL like they do in this paper opens up the floodgates of possibilities for continual learning
Authors: @mertyuksekgonul @LeoXinhaoLee @JedMcCaleb @xiaolonw @jankautz @YejinChoinka @james_y_zou @guestrin @sun_yu_

English
evolvingstuff retweetet

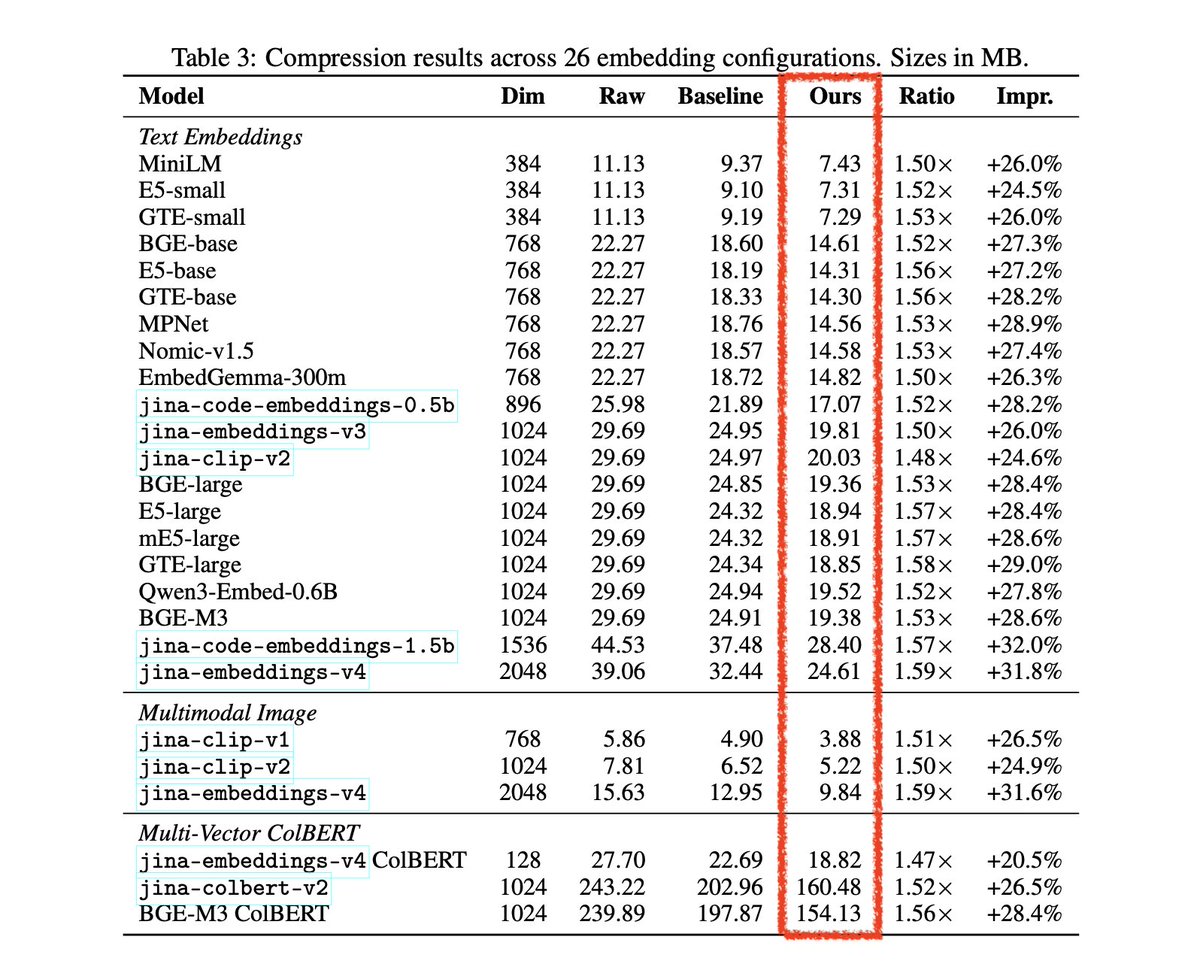
Convert your embeddings to spherical coordinates before compression - this trick cuts embedding storage from 240 GB to 160 GB, and 25% better than the best lossless baseline. Reconstruction is near-lossless as the error stays below float32 machine epsilon - so retrieval quality is preserved perfectly. Works across text, image, and multi-vector embeddings. No training, no codebooks.
English

evolvingstuff retweetet

This is not sped up.
So folks. conclusion still stands.
Robots are coming for all jobs,
even the ”safe” ones.
It’s just a matter of time.
it’s when, not if.
English
evolvingstuff retweetet

evolvingstuff retweetet

Cool result!
I tested the epiplexity paper's (intuitive) claim that information is observer-dependent with a vv straightforward experiment - I trained student networks (depth L) to predict outputs from teacher networks (depth K), measured epiplexity (area under loss curve) as training progresses.
Two regimes seem to emerge: when the student is too shallow for the data (bottom-left), epiplexity is high but the model just struggles indefinitely. When capacity roughly matches complexity, you see actual structure extraction - loss drops and the accumulated area reflects learned structure.
The paper formalizes something intuitive: the same data contains different amounts of learnable information depending on who's looking!
GIF
Andrew Gordon Wilson@andrewgwils
We introduce epiplexity, a new measure of information that provides a foundation for how to select, generate, or transform data for learning systems. We have been working on this for almost 2 years, and I cannot contain my excitement! 1/7
English
evolvingstuff retweetet

This is the most dexterous task I’ve seen a humanoid do so far.
Fully autonomous powered by Sharpa’s CraftNet (VTLA) — using tactile feedback to continuously fine-tune the last-millimeter interaction.
English
evolvingstuff retweetet

I like this very, very, much.
Marc Finzi@m_finzi
1/🧵 We are very excited to release our new paper! From Entropy to Epiplexity: Rethinking Information for Computationally Bounded Intelligence arxiv.org/abs/2601.03220 with amazing team @ShikaiQiu @yidingjiang @Pavel_Izmailov @zicokolter @andrewgwils
English
@BotanicBinary @paraschopra Linear algebra states that if you start with 2D of input (e.g. XOR) you cannot increase the rank beyond 2 via linearity. This post is ignoring the fact that he is using ReLU (a non-linearity) in the mix.
English

Isn’t that basic linear algebra? The rank of a matrix and dimensionality? Intuitively the idea is to find the smallest no of linear independent vectors to accurately describe your system. So if every input is represented by 50 dimensions, it may happen that 5 vectors are sufficient
English

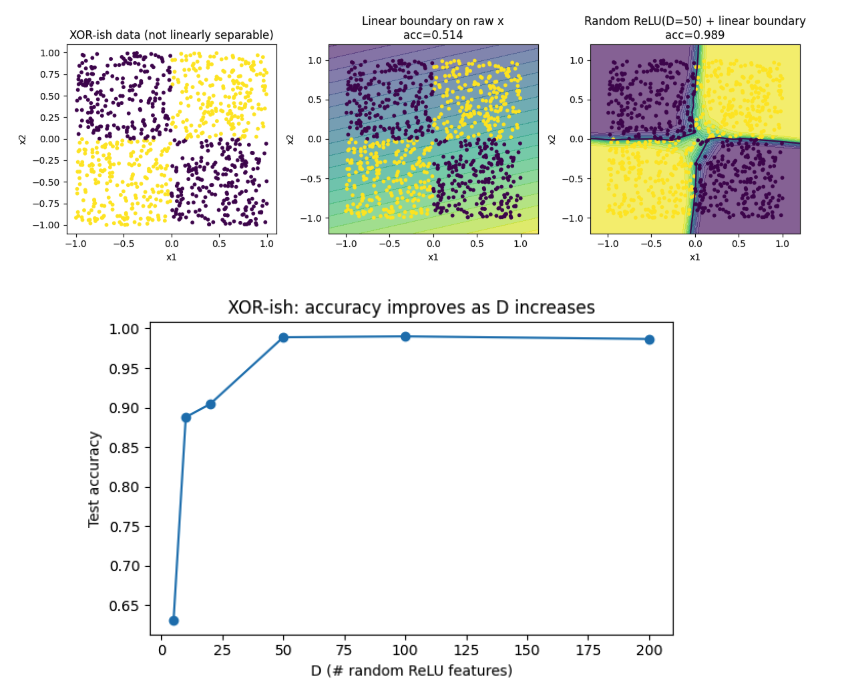
Learned something very interesting today!
Random projections of a non-linearly separable data onto high dimensional spaces is enough to make it linearly separable.
Consider a dataset like XOR that you can't linearly separate. Now, if you project each 2D point onto a D (=50) dimensional space using *randomly* initialised basis vectors, each direction creates a tiny difference between the classes (e.g. gives 51-52% accuracy) because expectation of two classes differs slightly when randomly projected.
So each randomly projected feature becomes a tiny discriminator and when you aggregate it over 20-50 such discriminators, a linear classifier is able to separate them perfectly by simply learning how much to weigh each feature.
One intriguing possibility of this is that we're able to train deep networks because random projections make most of the data already separable, making the job of gradient descent easy.
English
@paraschopra @tequehead Linear algebra disagrees with your assertion
English

@paraschopra Embedding data into higher dimensional space is not enough to make it linearly separable. The reason why you got it to separate XOR dataset is because you used ReLU nonlinearity in some way, evident from text in the plot.
English