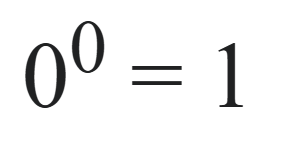morph
965 posts


morph
@hal9kcyon
Wasserstein geometer | Optimally transporting fokker planck into my veins
Heidelberg, Germany Beigetreten Eylül 2016
521 Folgt63 Follower
morph retweetet


@ProfNoahGian Because the authors are explaining all the parts that they can
English

Why is so much pop math writing like “the formula involves addition—an operation where the values of numbers are combined, as in 5+3=8—and an operation called semi Hodge-theoretic polydiaginonal neo-Riemannian integration. Surprisingly, the authors proved that this formula is quasi-invertible when the Sasquatch locus is sufficiently homogeneous.”
Who is your intended audience?!
So much of pop math writing assumes we don’t know the basics yet somehow care about the unintelligible minutiae of super advanced obscure topics…
English
@kenneth0stanley It seems backprop is a very limited way to integrate new representations with old ones. Are there evolutionary methods that are more promising?
English

The more you learn the easier it should be to learn more. The key word is easier. What could be more natural?
That’s the real puzzle of continual learning. Merely avoiding brain damage from accumulating additional knowledge is barely scratching the surface.
English


@junior_rojas_d @zzznah Neo-hookean? This looks more like poststructuralist to me
English

coordinating 102 muscle actuators to move 126 neo-Hookean tetrahedra
English

I love when a picture makes me feel something I can’t explain
📍@gottaclipit
Found this picture taken 8 years ago in a google maps review
English
@star_stufff Φ: lanky, awkward, like a cut through an onion, makes me wanna cry
φ: elegant, distinguished, in harmony with the dao
English

@hexesandspell Completely untrue ime, I pulled baddies when I was insecure as shit, when I got secure I remained single for years
English


Training losses don't always go to zero, because many decompose into loss = model bias + data uncertainty.
Eg,
LLMs: uncertainty = (unknown) data entropy.
Diffusion models: uncertainty = variance of the average denoising target.
Training reduces model bias, but data uncertainty can often dominate the loss (and gradient).


English

@LeviHallo Der Exponent sagt dir, wie häufig du die Basis an eins ranmultiplizierst. Eins mal (null mal die null) bleibt eins
Deutsch