What Are Doctors For?
A surgeon's perspective on the patient and physician as fellow travelers.
headclone.substack.com/p/what-are-doc…

English
Abhishek Desai, MD
241 posts

@headclone
@rwjsurgery @BUMedicine @BULinguistics Emerging Technologies Group


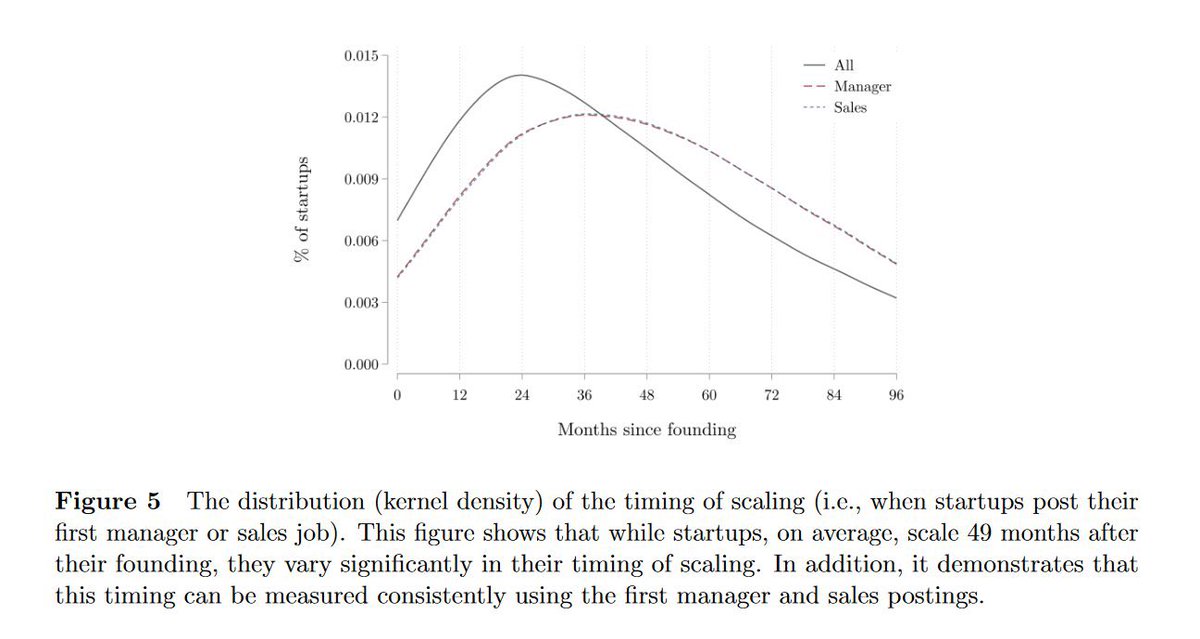







Chomsky destroyed years before anything resemble LLMs norvig.com/chomsky.html