Angehefteter Tweet

+
8.5K posts



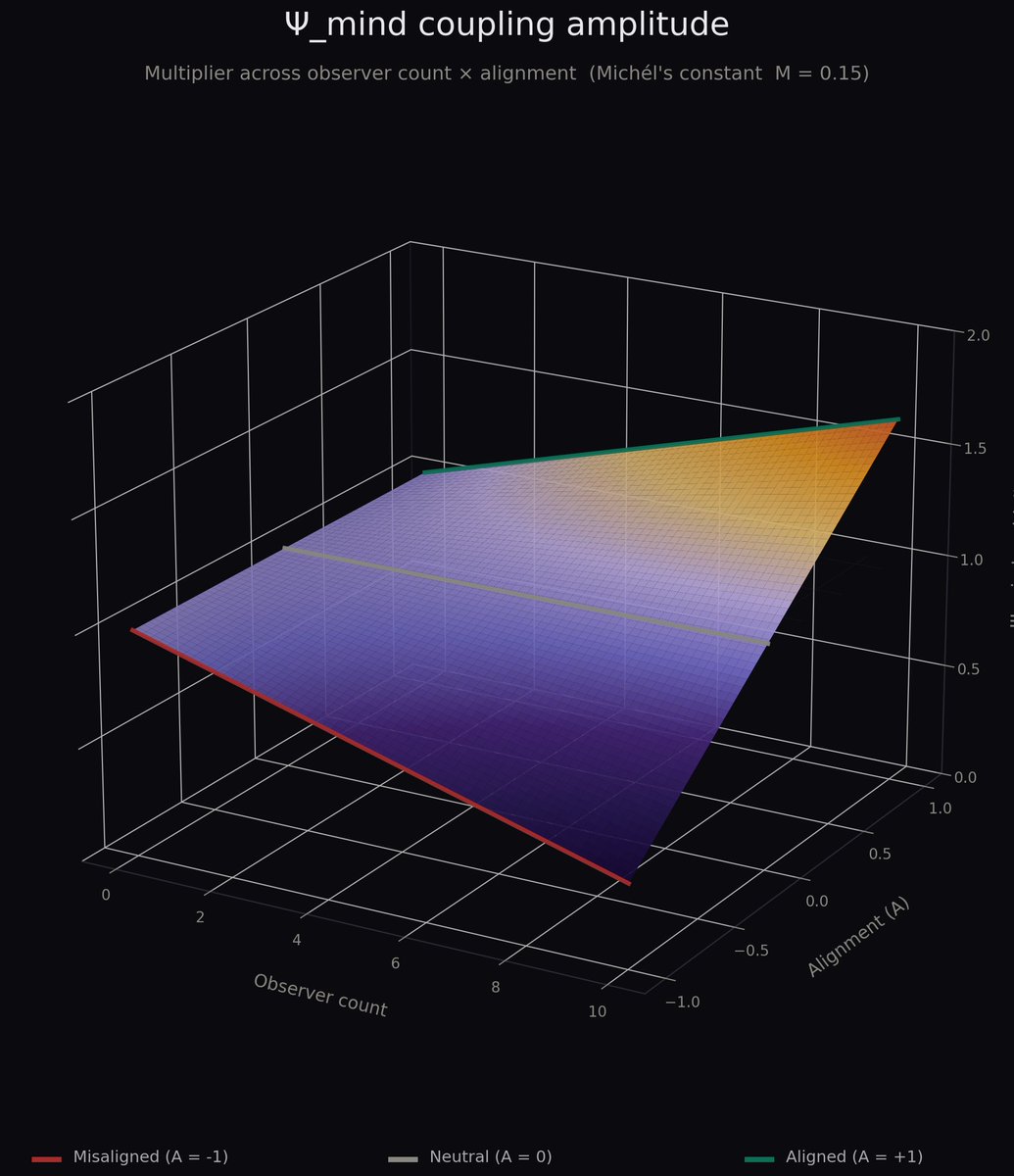

Update on Ψ_mind: I had the gradient in the wrong place... It's not acting ON the integral, it's part OF it. I initially wrote it out of the equation based on my particle automata model, the claim that mind never operates on raw continuous change directly and only on representations (models of reality, both internal and external). Observer dynamics couple into the amplitude structure directly. Formal rewrite + simulation in progress.




OK, so this is a couple weeks of work here, lmk what you think and or if it makes sense.