Angehefteter Tweet

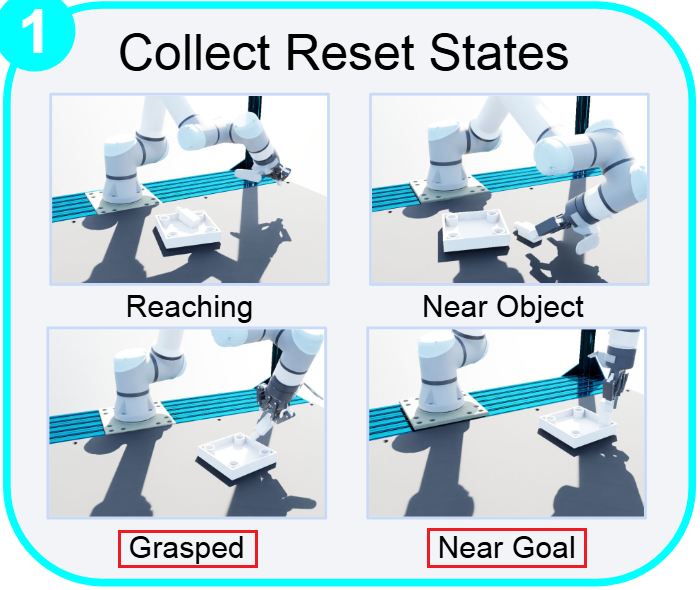
We’re releasing OmniReset, a framework for training robot policies using large-scale RL and diverse resets for contact-rich, dexterous manipulation.
OmniReset pushes the frontier of robustness and dexterity, without any reward engineering or demonstrations.
Try the policies yourself in our interactive simulator! weirdlabuw.github.io/omnireset/
(1/N 🧵)
English