Angehefteter Tweet

IYDKNYK
If you're building RAG or autonomous agents on
@awscloud, you know the struggle: balancing speed, freshness, and scale without drowning in infrastructure management.
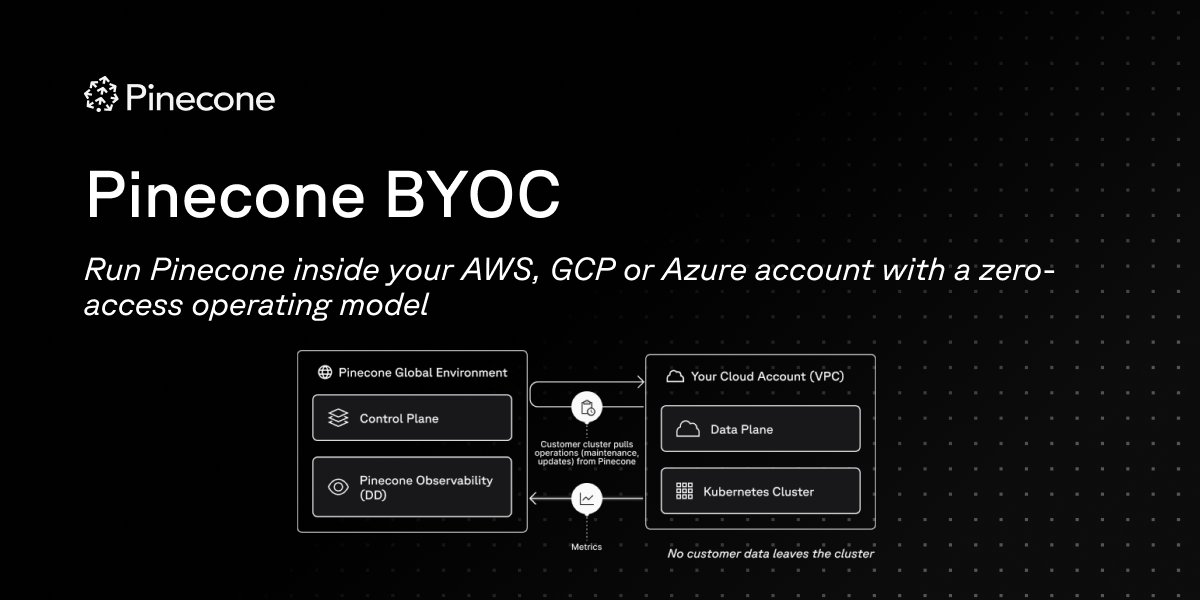
That is exactly why we built Pinecone with a serverless architecture.
In this video, we break down how our "slab" architecture transforms proprietary data into trusted AI. 👇
The Core Architecture: We separated storage from compute. By using Amazon S3 for cost-effective storage and intelligent caching for retrieval, we created a system that writes data to immutable files called "slabs."
The Result? Instant availability and durability.
True Serverless Scaling: Forget manual sharding. Our system handles writes in parallel and scales elastically. Whether you are indexing 1k vectors or 1B+, the system adapts without blocking queries.
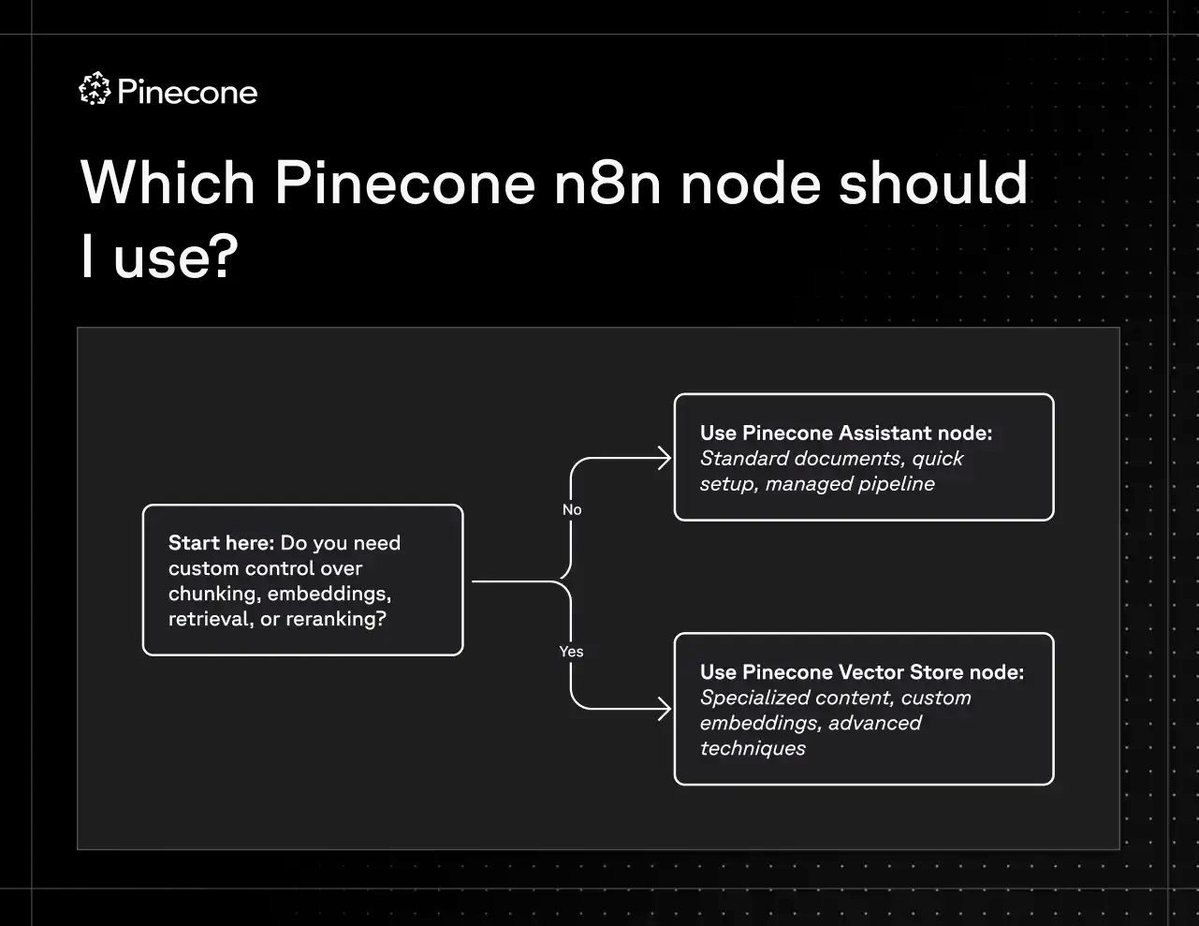
Which Deployment Fits You? There are two distinct paths depending on your workload:
1️⃣ On-Demand
Best for: RAG agents and bursty traffic.
How it works: Usage-based pricing with intelligent caching.
Why use it: You have millions of namespaces and need flexibility.
2️⃣ Dedicated Read Nodes
Best for: Recommendation engines and high-QPS search.
How it works: Isolated infrastructure where data is always warm in memory.
Why use it: You have strict SLOs and operate at a billion-vector scale.
Check our our e-book with @AWS_Partners that explains exactly how to achieve zero-infrastructure management while maintaining data freshness: pinecone.io/learn/aws-eboo…
English