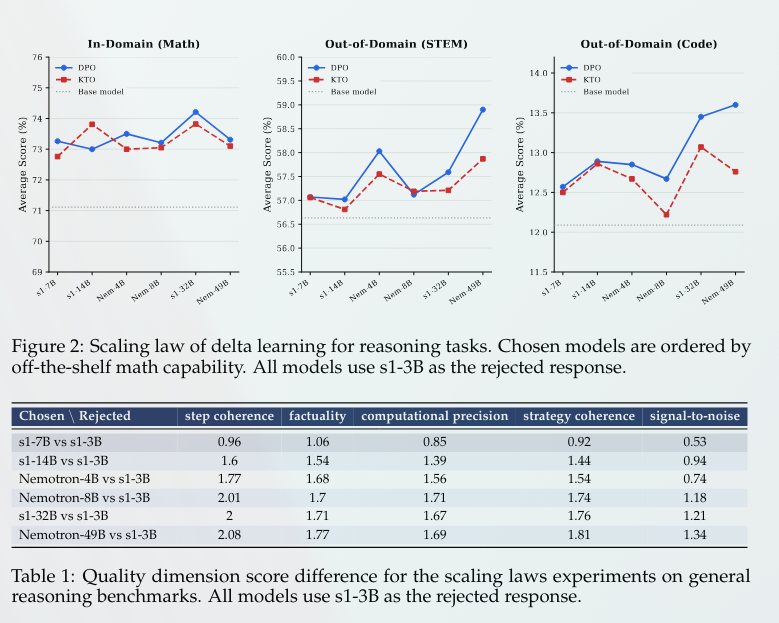
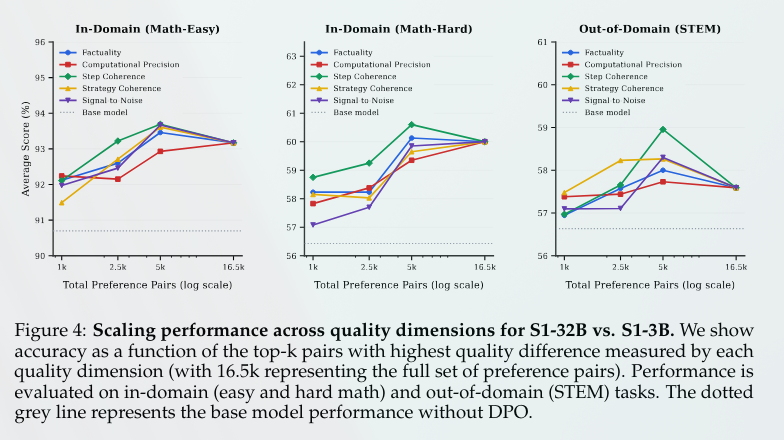
Angehefteter Tweet

Mann Patel
312 posts

@punsbymann
post training @CapitalOne | prev ml @google, GLAMOR LAB @USC | rl, interpretability and all things compute



@teortaxesTex What's your current timeline for china to reach Fable class ? GLM-5.2 certainly shorten the gap.


We raised $250M in Series C funding at a $2.2B valuation, led by a16z. Exa is a search lab organizing the web's data for agents.



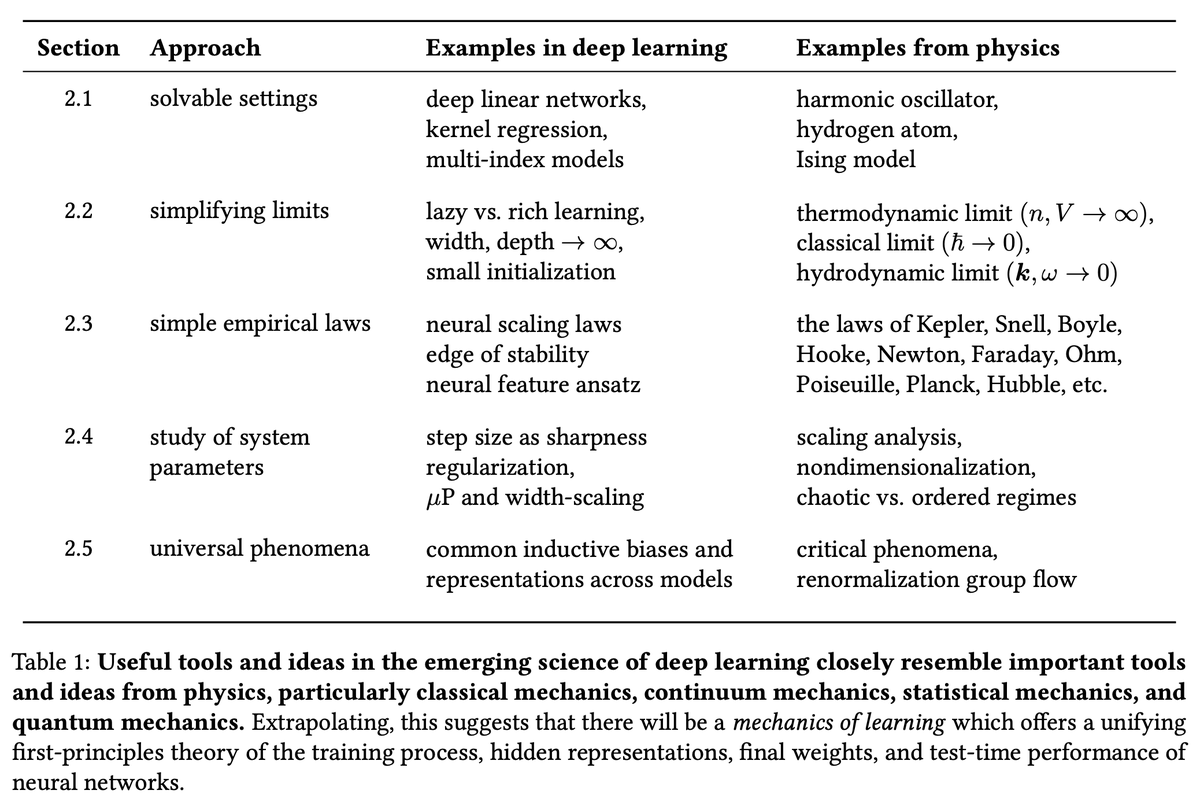





Introducing Claude Opus 4.7, our most capable Opus model yet. It handles long-running tasks with more rigor, follows instructions more precisely, and verifies its own outputs before reporting back. You can hand off your hardest work with less supervision.