
胡二虎 Will hu🐯
1K posts

胡二虎 Will hu🐯
@willlhhh
AI Growth Hacker @ManusAI & @hey_im_Monica, 野路子增长专家,在创业公司5年,做过30个网站和插件。喜欢用专业视角+Agent自动化跑有意思的产品增长案例。
Singapore Beigetreten Mayıs 2022
355 Folgt2.1K Follower

【后续剧情更新】Bing 那边的收录确实还在,可以看到全部是Listcle列表类的文章。
阿里自己倒是已经动手撤了,但撤的方式有点拉胯—没有直接在服务器端返回 404,而是用了 302 跳转到一个返回 200 的错误页。整条链路里连一个真正的 404 都没有,标准的 Soft 404。这种处理方式会让搜索引擎更慢地清除索引。

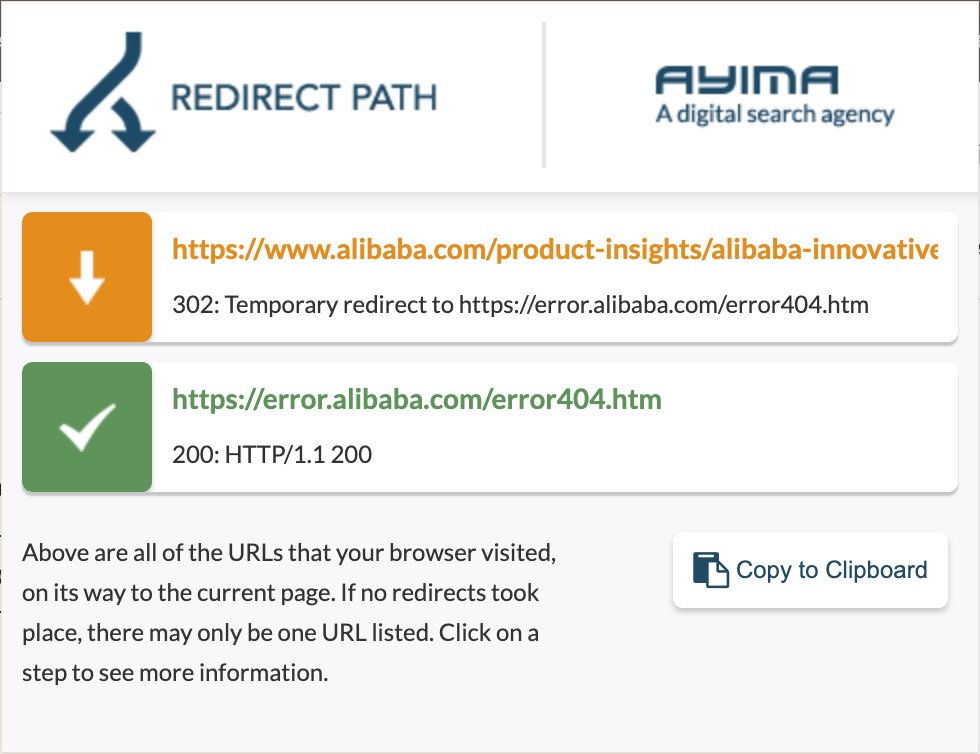
胡二虎 Will hu🐯@willlhhh
仔细掰扯了下,原来阿里国际站搞了个骚动作:他们在 `/product-insights/` 这个目录下,一口气怼了将近 590 万个纯 AI 生成的页面。 最离谱的是什么?这些页面根本不是在卖 B2B 的机器设备,而是在疯狂蹭各种 C 端泛商业的长尾词。比如“史上最畅销漫画”、“怎么辨别汤坏没坏”……连页面上的作者简介和底下的评论都是 AI 捏造出来的。 这事儿有意思的地方在于,Google 刚刚在 3 月 25 号结束了最新的 Spam Update(垃圾内容算法更新)。按理说,这种“大规模内容滥用”绝对是精准打击对象。但魔幻的是,这 590 万个页面目前依然活得好好的,甚至流量还在涨。 一个 DR 92 的顶级老域名,仗着自己底子厚,直接骑在 Google 的算法底线上疯狂试探。 我实在太好奇这事儿的走向了。我已经在 Manus 上挂了个 Schedule Task,每天自动去扒 Ahrefs 和 Google 的数据,死死盯着这批页面的收录和流量变化。 我准备花30天时间,用这批连续追踪的数据,来算一笔账: 在 2026 年的今天,当内容和作者 100% 都是 AI 生成时,一个高权重网站的Google 页面收录量,页面排名,以及Traffic 之间,到底是个什么线性关系? 这可能是今年最值得拆解的 AI SEO 压力测试。
中文


@willlhhh 如果他们从来没做过标准http 404的话,到底是部分页面,Sub domain搞404规则呢,还是全站搞? 全站搞的话估计一下子能带出来千万上亿等级的404.整个网站的Error Rate就上去了。
中文

仔细掰扯了下,原来阿里国际站搞了个骚动作:他们在 `/product-insights/` 这个目录下,一口气怼了将近 590 万个纯 AI 生成的页面。
最离谱的是什么?这些页面根本不是在卖 B2B 的机器设备,而是在疯狂蹭各种 C 端泛商业的长尾词。比如“史上最畅销漫画”、“怎么辨别汤坏没坏”……连页面上的作者简介和底下的评论都是 AI 捏造出来的。
这事儿有意思的地方在于,Google 刚刚在 3 月 25 号结束了最新的 Spam Update(垃圾内容算法更新)。按理说,这种“大规模内容滥用”绝对是精准打击对象。但魔幻的是,这 590 万个页面目前依然活得好好的,甚至流量还在涨。
一个 DR 92 的顶级老域名,仗着自己底子厚,直接骑在 Google 的算法底线上疯狂试探。
我实在太好奇这事儿的走向了。我已经在 Manus 上挂了个 Schedule Task,每天自动去扒 Ahrefs 和 Google 的数据,死死盯着这批页面的收录和流量变化。
我准备花30天时间,用这批连续追踪的数据,来算一笔账:
在 2026 年的今天,当内容和作者 100% 都是 AI 生成时,一个高权重网站的Google 页面收录量,页面排名,以及Traffic 之间,到底是个什么线性关系?
这可能是今年最值得拆解的 AI SEO 压力测试。
胡二虎 Will hu🐯@willlhhh
我已经想到我的第二篇监测文章了 每天访问Alibaba,看批量页面什么时候被Google制裁 笑死😆
中文

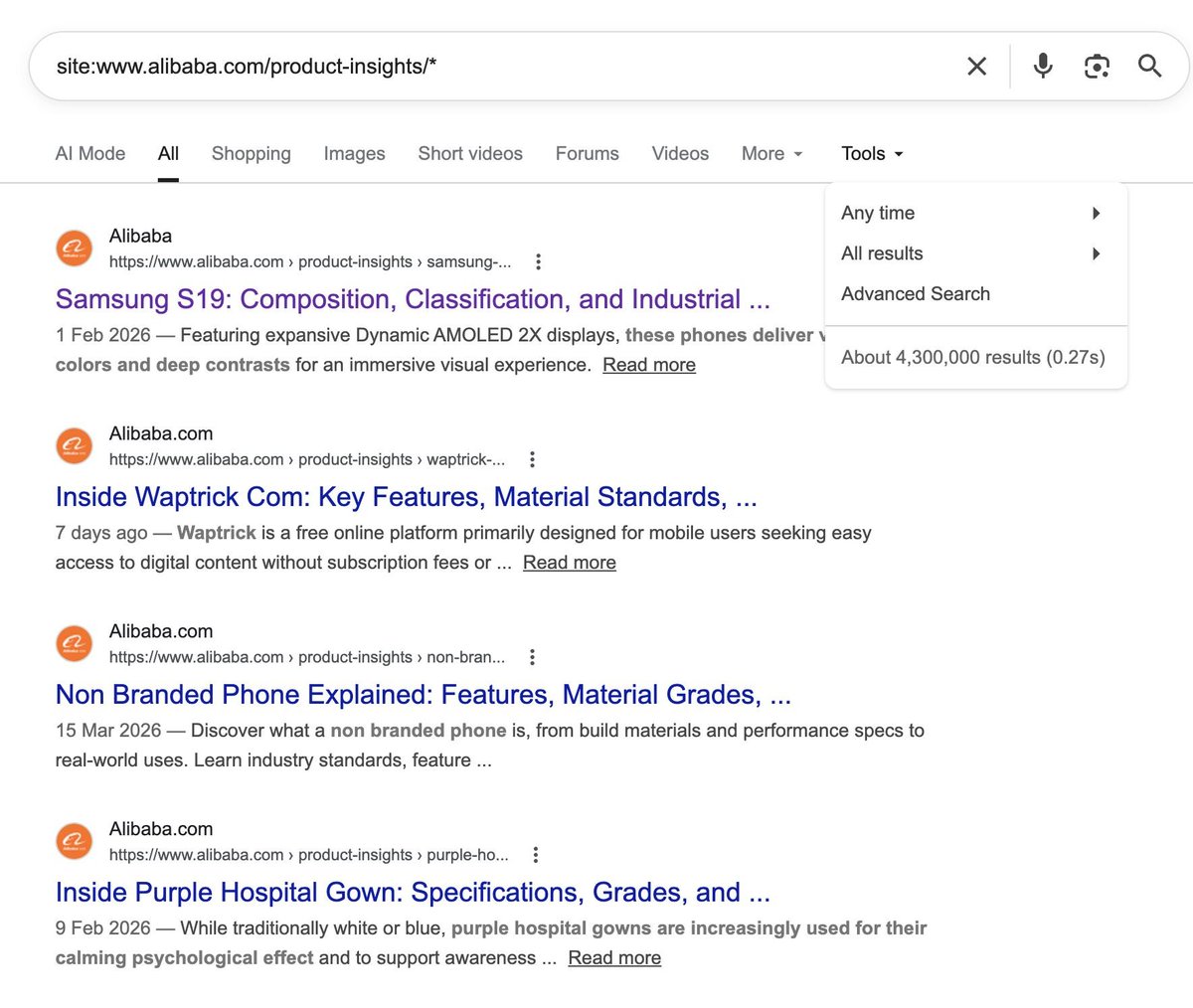








我看大家都在问我是怎么用 Manus 持续地用 Schedule Task(也就是定时任务)去调研,然后全部收束到一个报告上的。
实际上我过去已经讲过了这个用法,只是标题没有写 Case 这么炸裂,大家才都不关注而已。如果大家想知道我是怎么做的,可以去看一下我之前写的这篇 Threads
胡二虎 Will hu🐯@willlhhh
如果按这种方式来用,那么在 Manus 里设置定时任务(比如每日报告、每日会议摘要等)其实也天然具备完整上下文。 因为它面对的是同一个邮箱时间线,用的是同样的 prompt,但背后读取的是持续沉淀的完整记忆。 对我来说,这种方式比在多个工具之间来回翻找更稳定,也更容易被 agent 利用。 顺着信息实际流动的结构来用 agent,反而比强行改变工作习惯更自然。
中文