Angehefteter Tweet

How can we predict multiple plausible targets from a single context in joint-embedding self-supervised learning (SSL)?
Check out our paper titled “Self-Supervised Learning from Structural Invariance” accepted at #ICLR2026! Previously Best Paper Award at @unireps 2025.
arxiv.org/abs/2602.02381
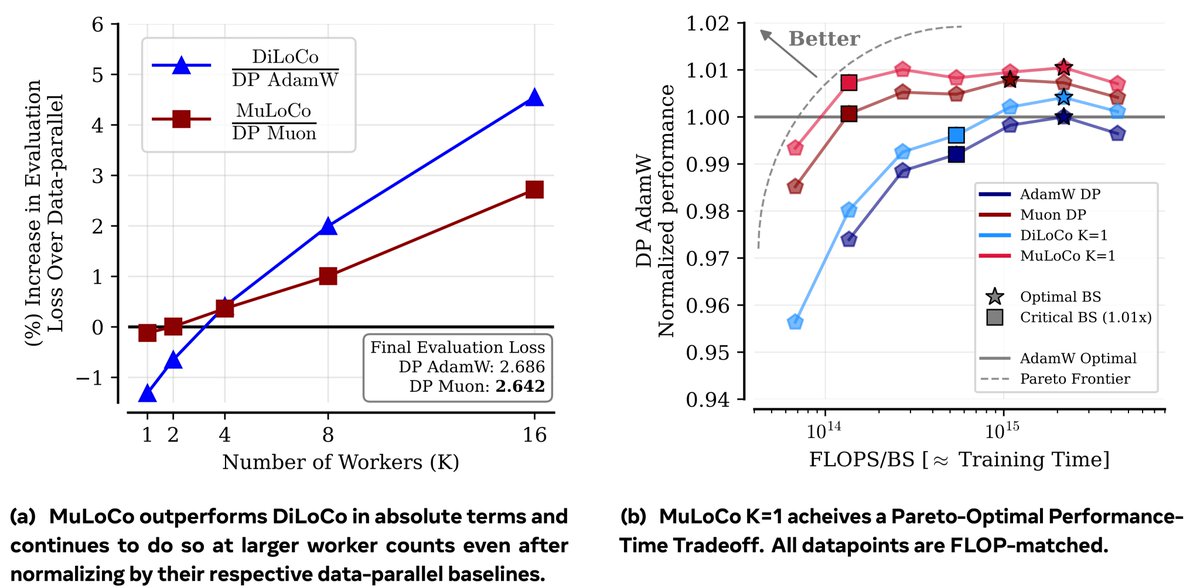
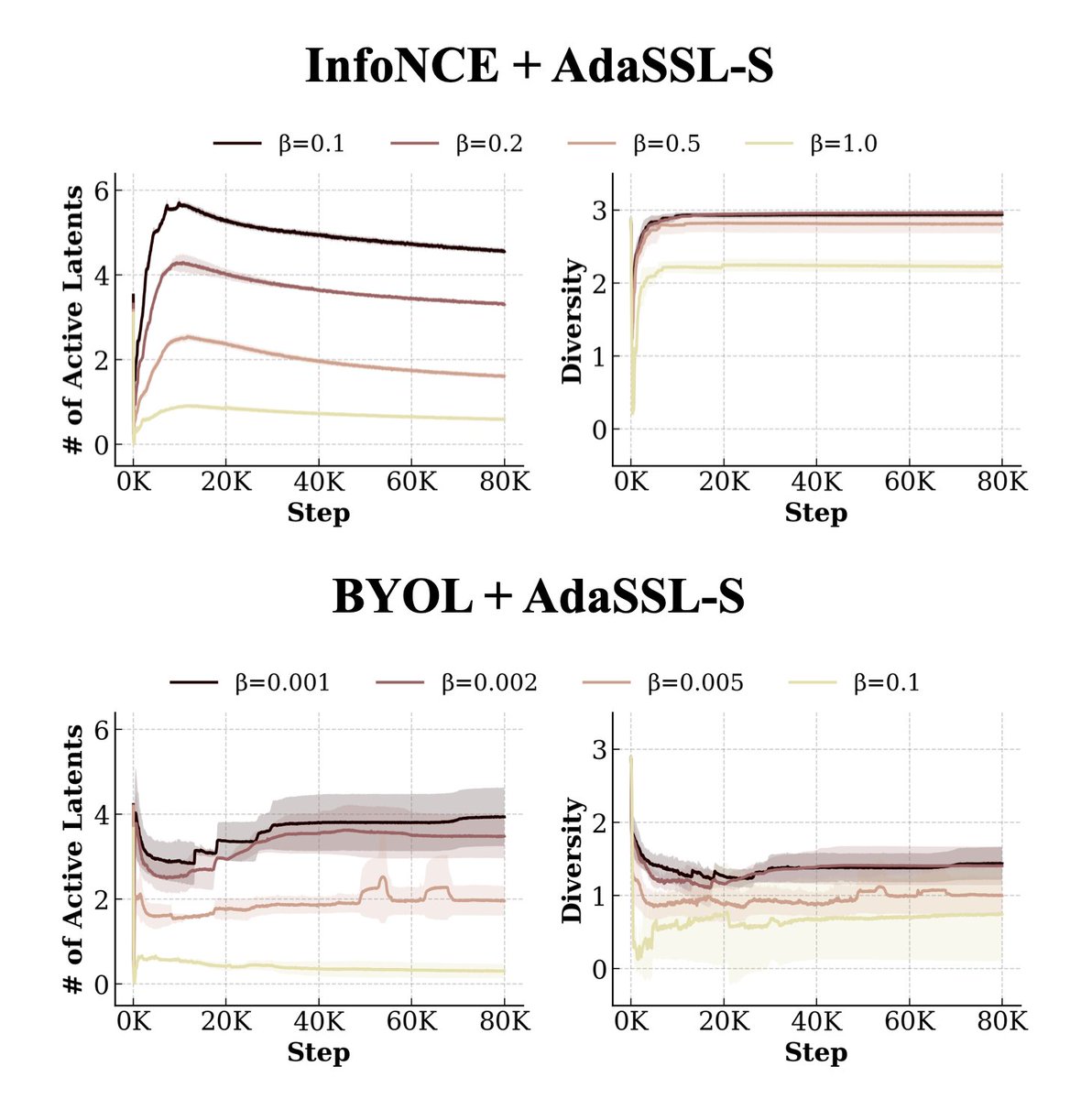
We introduce AdaSSL, which models the target uncertainty and relaxes the standard assumption that the positive pair share the same semantic features.
Derived from first principles, we realize @ylecun’s JEPA with a learned latent variable for jointly learning better representations and world models, extending SSL’s utility to a broader range of data types.
1/🧵
English