
Zipeng Zhou
39 posts





Black woman from South Africa: “Black people have been patient enough for more than 400 years of colonialism. We are coming for you, and we are going to get everything that you own.”
White people are facing racism, hatred, and brutal violence in South Africa. This is not acceptable. More people should know about the horrible things happening in South Africa; almost nobody talks about it.
English


An Israeli source told i24NEWS:
"The elimination and the damage to the Basij force is the stage that will allow the Iranians to take to the streets."
English

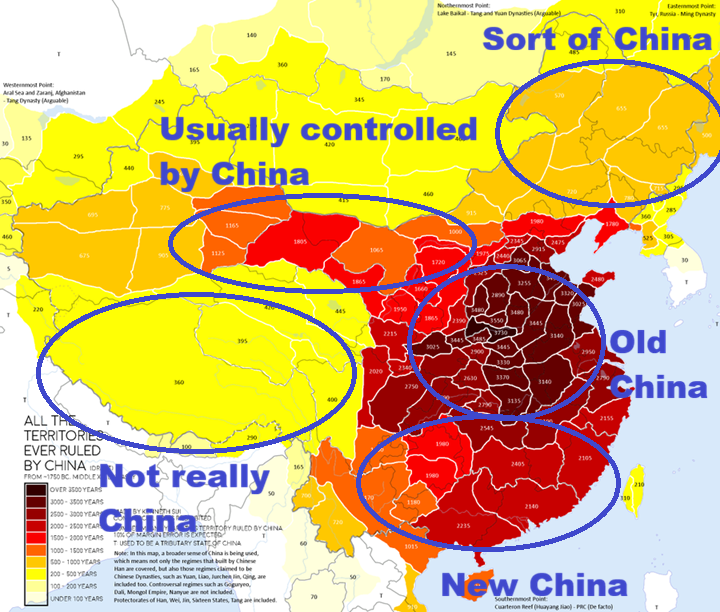
Many people say they don't follow any religion in China.
But that's not true.
They worship Mao Zedong and the Communist Party. 😑🤡
English

@CalltoActivism you missed the point. you should get out of the car listening to the officer
English

Jesus, he really hates his wife and kids
Acyn@Acyn
Vance: In the United States of America, you don't have to apologize for being white anymore.
English

These are literally the kind of LLM interview questions most candidates wish they had seen earlier.
A curated list of LLM interview questions - shared by Hao Hoang
Want this doc?
Follow @techNmak and comment “LLM” - I’ll send it over.

English

Chinese-American woman goes off on Cambodians at an airport because they're Southeast Asian. You're not Asian if you don't hate each other 🤷♂️
English

“Can someone explain how I have 4 DEGREES and still can’t get a job?”
BA in Communication.
BA in Spanish.
BFA in Dance.
Master’s in Journalism.
Years of school. Massive debt. Zero payoff.
She didn’t fail the system — the system sold her a scam.
English
@SaraForTexLege @greyfortune2 how many of them are performed on men?
English

@greyfortune2 No. I’ve had a hysterectomy.
English
According to Elon Musk, I am not a woman.
Elon Musk@elonmusk
If you have a womb, you are a woman. Otherwise, you are not.
English
@Vilna_Gaonn @yesknow @TheInsiderPaper that means you really don't konw the situation there. In china, there is a saying " 蜀道难难于上青天". It is almost impossible to build roads there becuase of the geoloibcal instability in that whole area.
English

@yesknow @TheInsiderPaper Sorry but that still counts as a failure! You gotta do your geotechnical assessment too! FAILED
English

BREAKING: 758-metre-long Hongqi bridge collapses in southwest China, months after opening
English


@IlirAliu_ it is not new. the problem is how to decrease the training cost the training time
English

Robots are getting smarter, but most still fail the same way. They don’t learn from their own mistakes.
A new paper proposes something different: a way for robots to self-improve directly from their failures in the real world.
It’s called PLD (Probe, Learn, Distill).
The idea: instead of collecting endless human demos, let the robot figure out where it fails, learn how to recover, and then distill that knowledge back into its main model.
Key takeaways from the research:
✅ Uses residual reinforcement learning to recover from policy failures
✅ Achieves 99% success on LIBERO and 100% on real Franka and YAM arms
✅ Runs hour-long manipulation tasks without human resets
✅ Builds a feedback loop between real-world data and model adaptation
Unlike supervised fine-tuning, which relies on humans, PLD learns from the robot’s own experience.
By training on its own failure distribution, the model becomes both more efficient and more aligned with the real world.
It’s not just a technical shift, it’s a step toward robots that improve themselves through real-world practice.
Thanks for sharing, @_wenlixiao !!
Paper and demos: wenlixiao.com/self-improve-V…
—-
Weekly robotics and AI insights.
Subscribe free: scalingdeep.tech
English

I have been charged in a federal indictment sought by the Department of Justice.
This political prosecution is an attack on all of our First Amendment rights. I’m not backing down, and we’re going to win.
English

Here it is, the all new Model Y Performance featuring… 🏁
- More aggressive front bumper ✍️
- New 21“ wheel design 🛞
- More aggressive diffusor 💨
- Enhanced Rear bumper ✍️
- Carbon fiber spoiler lip 👄
- New Performance Powertrain 🐎
- Adaptive suspension 🤭
- 16“ touchscreen 🖥️
- New sport seats including the ludicrous badge. (Similar to Model 3, but not identical) 💺
Starting at 61.990€ in Germany with deliveries happening in September 📆



English


Jeanine Pirro: "We need to go after the D.C. Council and their absurd laws."
English