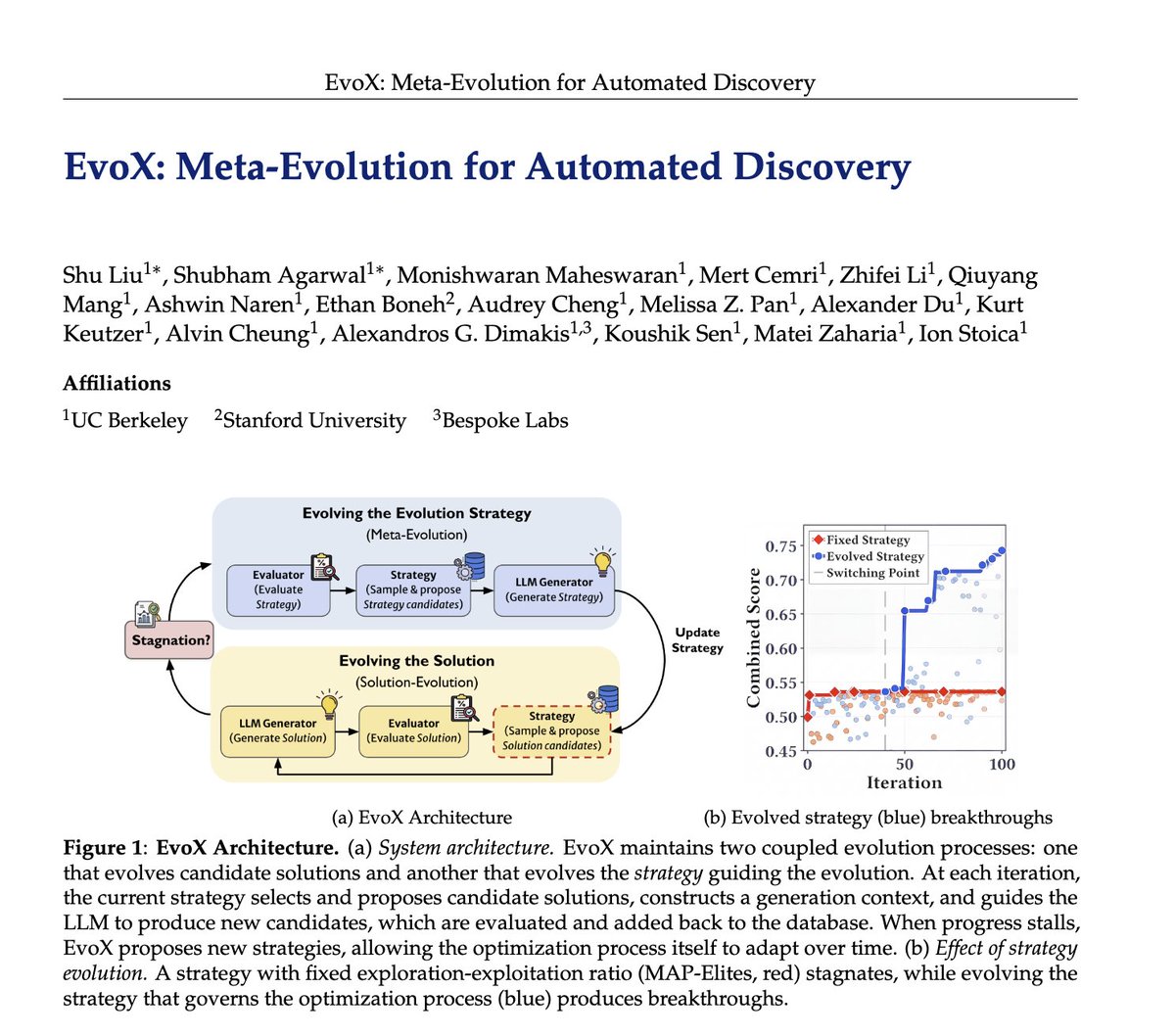
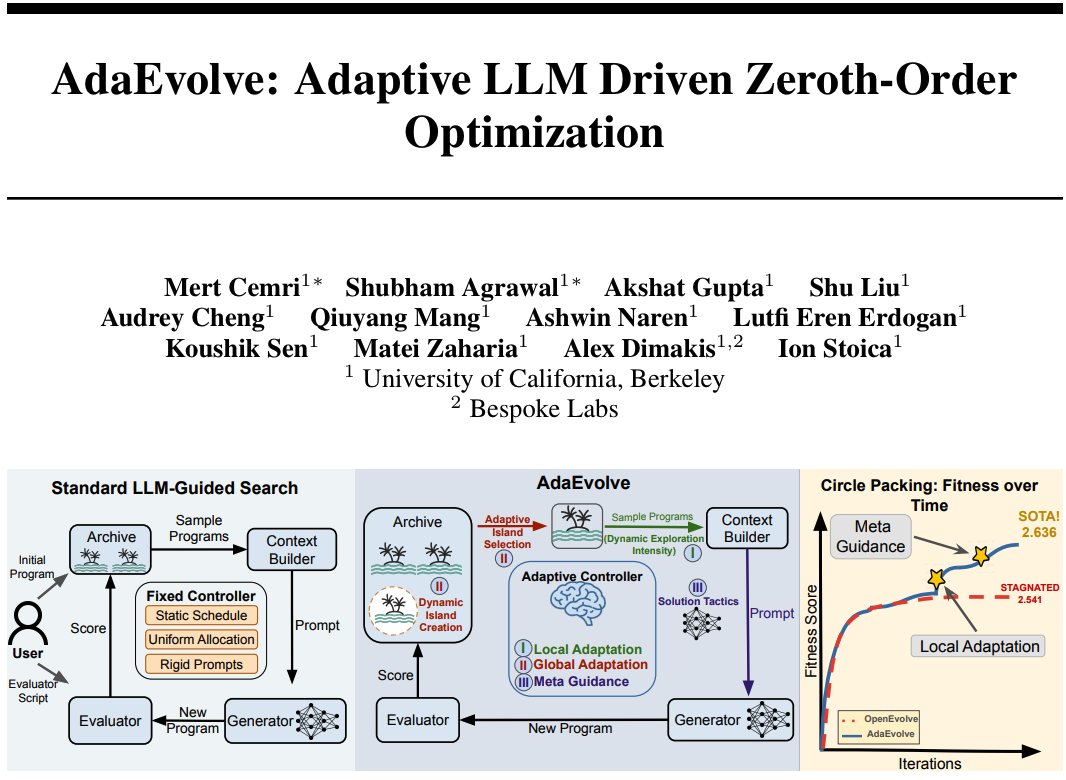
Berkeley AI Research retuiteado

Excited to share our latest work: M²RNN!
We’ve revisited non-linear RNNs and found that expanding the hidden state to a matrix (Matrix-to-Matrix) significantly improves language modeling while the non-linear recurrence enables expressivity beyond TC⁰.
Key highlights:
- Efficient Scaling: Our expansion mechanism leverages. Tensor Cores for high-throughput training.
- Better Long-Context Performance: Beats SOTA hybrid linear attention models by 8 points on LongBench.
- Hybrid Models: Replacing just ONE layer in a hybrid stack gives massive gains with minimal overhead.
This establishes non-linear RNNs as a primary building block for the next generation of LLMs.
Mayank Mishra@MayankMish98
Introducing M²RNN: Non-Linear RNNs with Matrix-Valued States for Scalable Language Modeling We bring back non-linear recurrence to language modeling and show it's been held back by small state sizes, not by non-linearity itself. 📄 Paper: arxiv.org/abs/2603.14360 💻 Code: github.com/open-lm-engine… 🤗 Models: huggingface.co/collections/op…
English