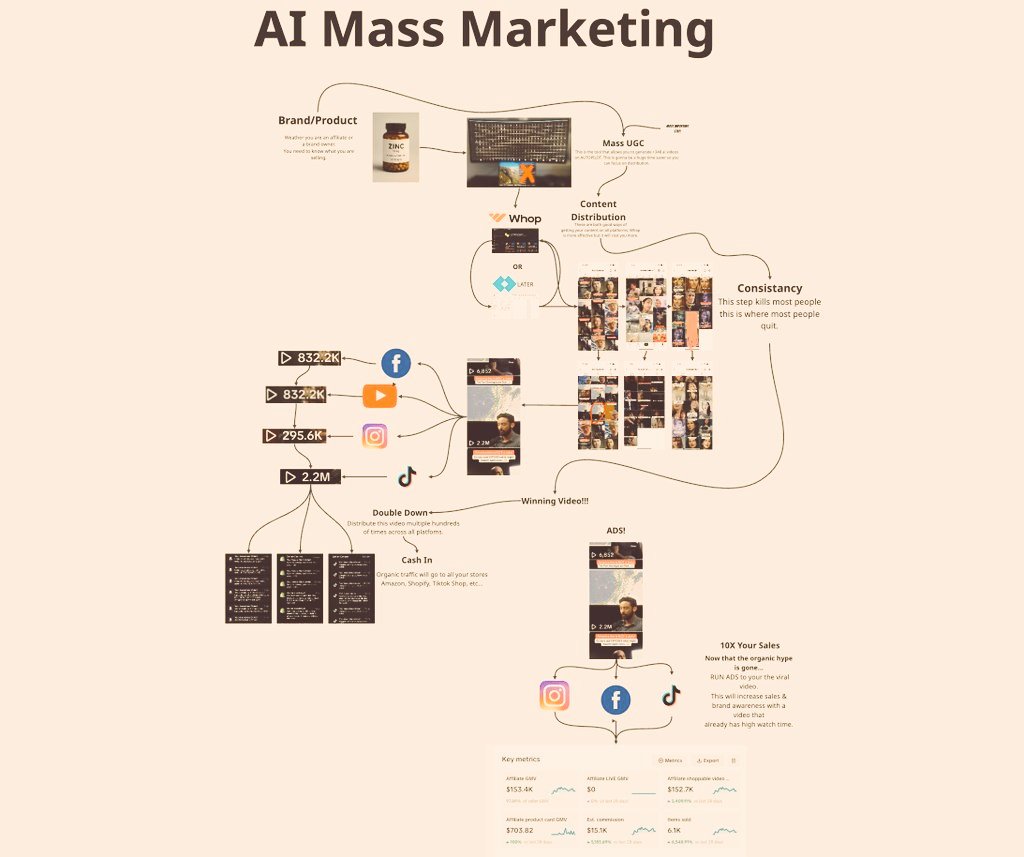
English
Sumit Kumar Singh
15.2K posts

@Sumitks
Building Garage Labs - Full Stack AI Advisory and Upskilling ex-Microsoft, Talabat Harvard Business School, IIT Delhi, IIM lucknow | Product Coach

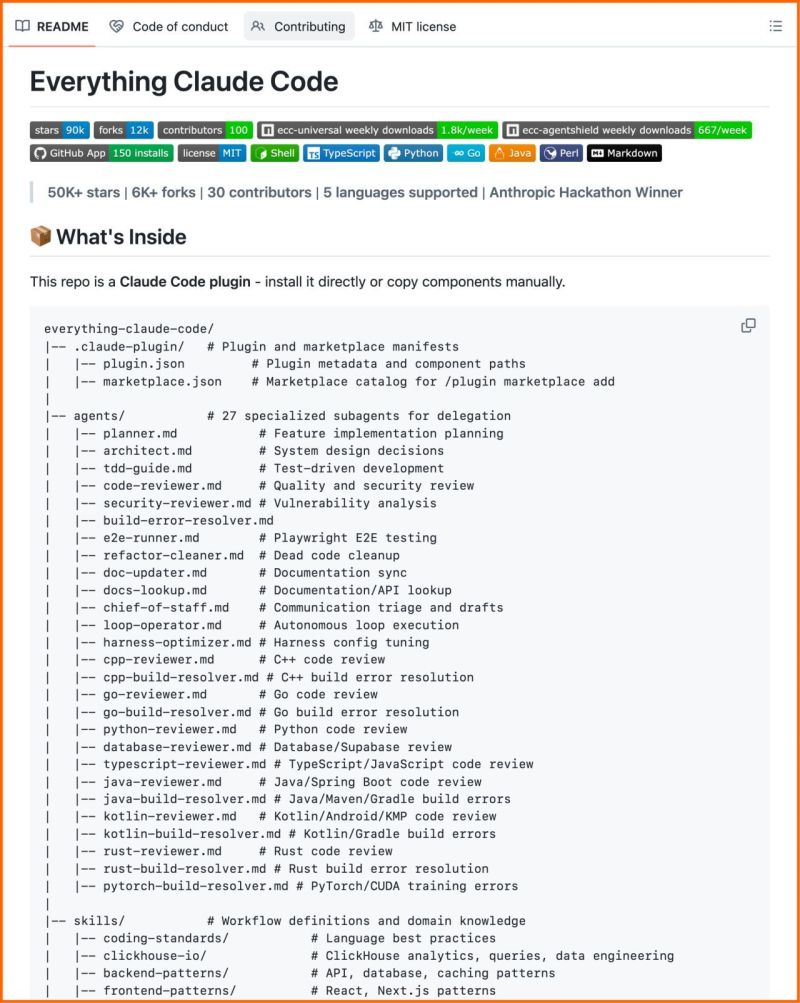






Had a fantastic time last evening with my old friends, colleagues & AI founders. Thanks for making the evening more engaging, insightful & memorable. With @veermishra0803 @harshamv @Sumitks @lorsophy1 #IndiaAIImpactSummit2026