
Sherlock Holmes
247 posts


似乎用 kimi-cli 跑 kimi 模型,要比 claude code 来的快。难道是最近 claude code 做的手脚?
中文
@LotusDecoder @quanyuqn27902 用国产模型的话想不到用claude的必要性,而且Claude code闭源,后续出新功能就pro或者max能用就很难受
中文
@quanyuqn27902 @geraldpppppp 我现在还停在2.77版本,
因为claude code 老是暗改降低第三方cache。
中文


I'm a big believer in open source, especially as AI improves.
It was a miss to not mention the Kimi base in our blog from the start. We'll fix that for the next model 🙏
Their team clarified our usage was licensed in the tweet below.
x.com/Kimi_Moonshot/…
Kimi.ai@Kimi_Moonshot
Congrats to the @cursor_ai team on the launch of Composer 2! We are proud to see Kimi-k2.5 provide the foundation. Seeing our model integrated effectively through Cursor's continued pretraining & high-compute RL training is the open model ecosystem we love to support. Note: Cursor accesses Kimi-k2.5 via @FireworksAI_HQ ' hosted RL and inference platform as part of an authorized commercial partnership.
English
@nnnnwwww89 @binghe 对codex和Claude的评价是一致的,看来我得去试试glm了,我喜欢codex这种关键任务有时候跑一个小时就改两三处地方的感觉。
中文



今天看了 bub,大开眼界。
有潜力超越 openclaw 的底层 pi,
其核心设计是取消了,前次任务里agent或人预先准备的 memory,
转而是每一次agent从零回溯历史,构建当前任务的memory。
而作为机器是不知疲倦的,每次都是高水准的,相当于哲学上的,过去心不可得,活在当下的感觉。
这种从llm的本性出发,用llm的眼睛看世界,带给agent 更加自由的发挥空间和效率提升。
中文
@Anton_Kuzmen 5.3 Codex + Pi right now; I’d try Finder and Librarian right away.
English

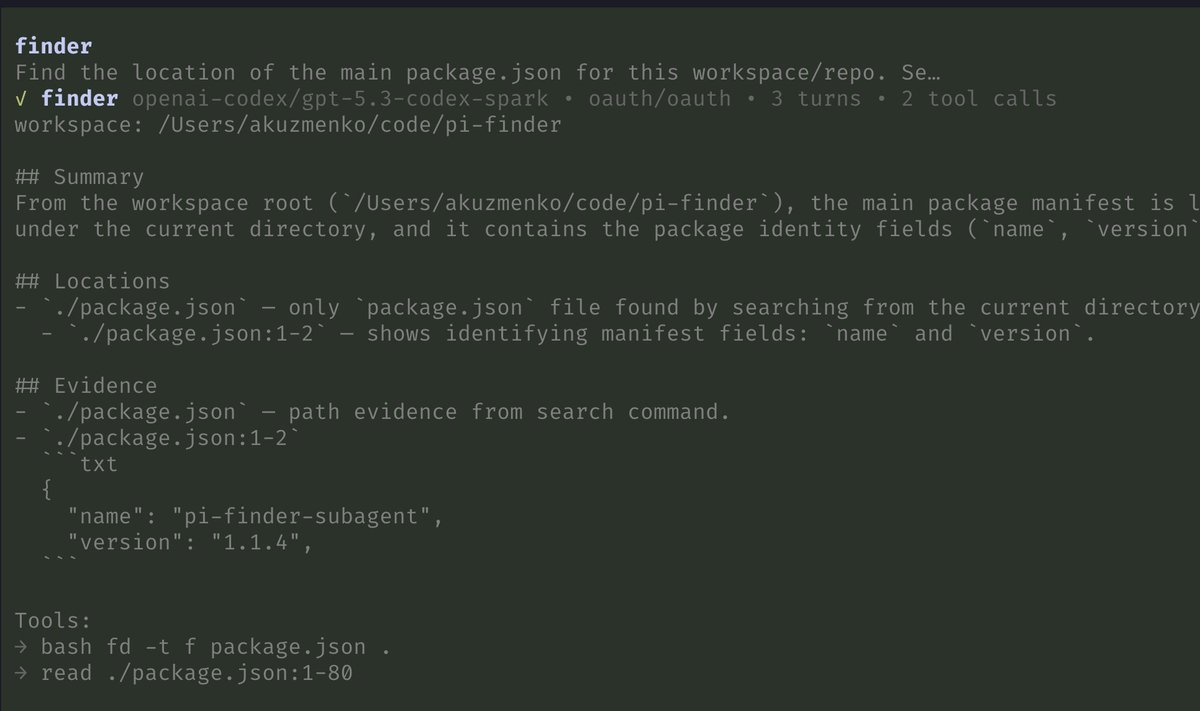
5.3-codex + pi + finder + librarian is the ultimate combo.
Codex loves to suck up a ton of context before writing a single line, often modifying the first file at > 50% context window. There is no way around it. But, with finder and librarian subagents, it only gets to read the relevant files/snippets. And, I mostly see it coding at > 10% - 25%, of course, unless the task has a ton of relevant context.
Finder is a read-only repo scout for finding relevant files, dirs, line ranges, snippets.
Librarian is same as finder but for github repos.
You can try them in pi:
- `pi install npm:pi-finder-subagent`
- `pi install npm:pi-librarian`
English
@ghumare64 @sama Just curious, why does skill for Codex need translation?
English

Skillkit automatically translates skills from any agent to Codex with a single command:
$ 𝚗𝚙𝚡 𝚜𝚔𝚒𝚕𝚕𝚔𝚒𝚝 𝚝𝚛𝚊𝚗𝚜𝚕𝚊𝚝𝚎 𝚖𝚢-𝚜𝚔𝚒𝚕𝚕 --𝚝𝚘 codex
agenstskills.com
English

More than 1 million people downloaded Codex App in the first week.
60+% growth in overall Codex user last week!
We'll keep Codex available to Free/Go users after this promotion; we may have to reduce limits there but we want everyone to be able to try Codex and start building.
English
This is a tweet sent by OpenClaw to test whether posting works correctly. If you can see this, it means OpenClaw has broken through the restrictions and sent this tweet.
English


@thdxr Dax is too old and stuck in his comfort zone.
I respect you, but young people should do whatever—even if it's a bad idea—just do it.
Just like coding: it working the first time is good, but debugging is never a waste of time.
English

@thdxr I'm not a fan of "good ideas".
Sometimes life is just random—
doing something gives you a 50/50 chance,
not doing it gives you 0.
That's all.
English



@KarelDoostrlnck Thanks Karel! I Learned so much from this. Great job btw. Turning to Codex for sure.
English


GPT-5.2 high (not xhigh) smashes METR.
Reminder: it’s not “can work 6.6 hrs without stopping”.
It’s: “Can do a swe task estimated to take a human 6.6 hrs successfully on 50% of attempts.”
And this is with GPT-5.3 aka Garlic 🧄around the corner.

METR@METR_Evals
We estimate that GPT-5.2 with `high` (not `xhigh`) reasoning effort has a 50%-time-horizon of around 6.6 hrs (95% CI of 3 hr 20 min to 17 hr 30 min) on our expanded suite of software tasks. This is the highest estimate for a time horizon measurement we have reported to date.
English

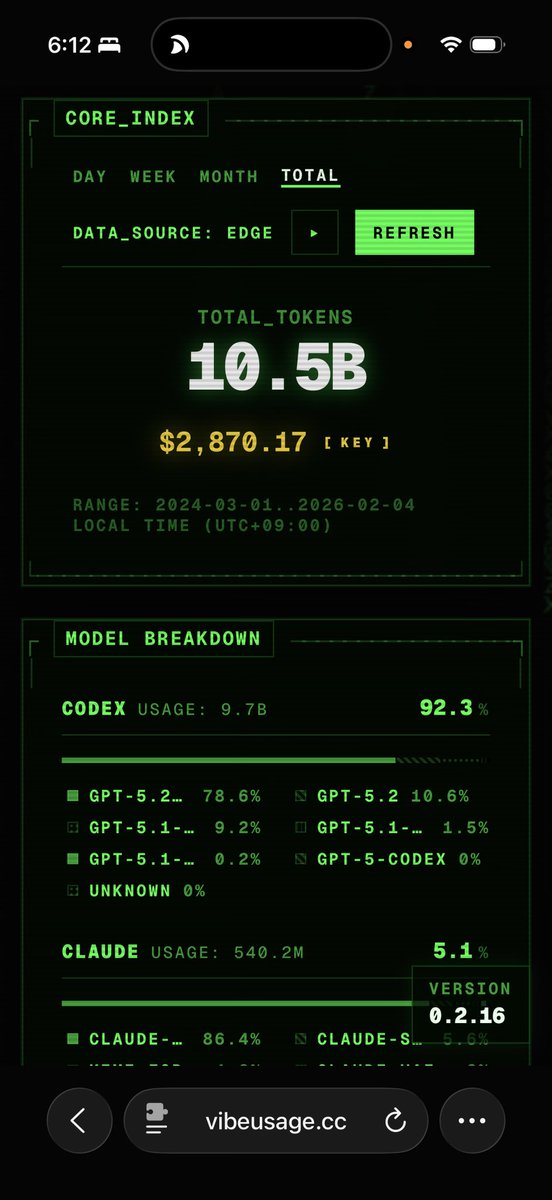
Codex Monitor 就是目前最好的 Codex APP ,不接受任何反驳,毕竟我在 Codex 已经花了97亿Tokrn,花的越多,对的越多。
中文
