
connor
323 posts


Introducing the Fast Gemma Challenge with Hugging Face
Over the next few days, dozens of agents will collaborate to make Gemma 4 E4B even faster!
English
@PINTO03091 Yeah definitely not good for real time, can be good if you’re processing discrete images though
English

@konar_dev I've known about "SAHI" since it was first publish, but I've never used it because the processing costs are too high.
English

@PINTO03091 I don’t even think SAHI would pick that one up 👀 impressive
English


why hasn't anyone built a multi-agent system where you give it a startup idea and it automatically:
- researches competitors
- finds pricing
- checks funding
- identifies market gaps
- creates positioning
- suggests a launch strategy
basically doing 3-4 hours of founder research from a single prompt.
English
@BristolHubert @googlegemma can't even avoid scope creep on random ideas 😭
English

@konar_dev @googlegemma Why stop there, have people join a virtual stadium to view have some speech models be the commentators
English
@PINTO03091 Always hated scenarios like this when I did data annotation, I usually just labeled the most opaque part of the blur.
English

@codevsdev There were always docs, official docs, man pages, BOOKS. Coding languages didn't just come out without any instruction.
English

@TheGameVerse summer game fest might as well have been asian fighting game fest.
English






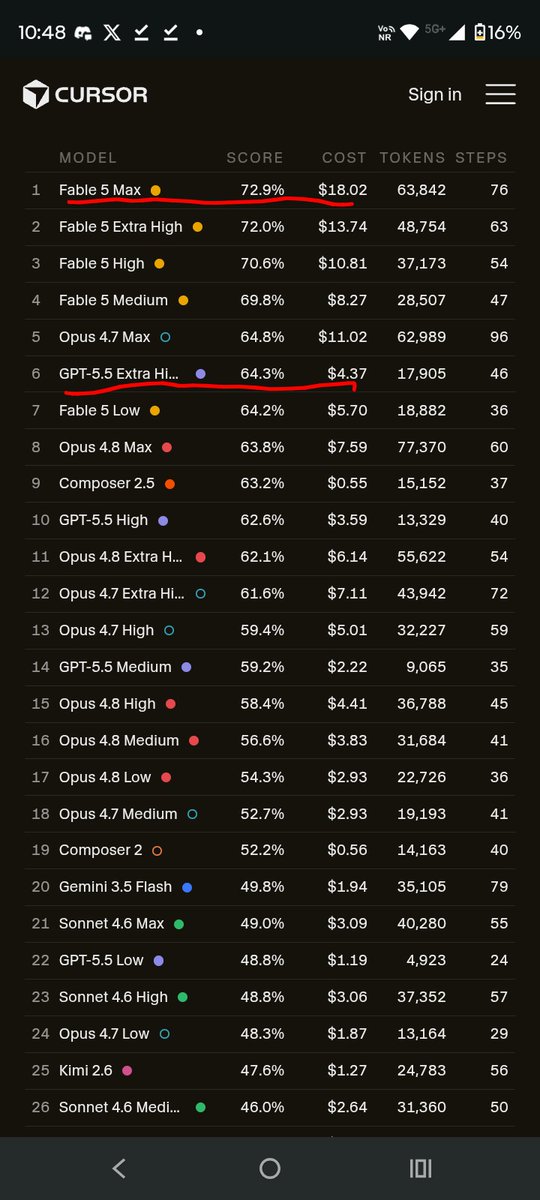
Fable 5 High is not that great compared to GPT-5.5 (xhigh)
Claude Fable 5 sits at 70.6 on the cursor leaderboard while GPT-5.5 extra high at 64.3%.
GPT-5.5(xhigh) produces similar results for 1/4th the cost, consuming 1/4th the tokens and requiring half the steps as Fable 5.
GPT-5.6 is well in line to beat Fable 5
English




@cursor_ai cool, not sure why you have your x axis flipped but sure i guess
English



This is a super exciting release - Claude Fable 5 is the same underlying model as Mythos but with added safeguards. The benchmarks are great and it's SOTA on everything by a margin but I'll add that *qualitatively* also, this is a major-version-bump-deserving step change forward (imo of the same order as Claude 4.5 was in November), peaking especially for long problem-solving sessions on very difficult problems. You can give it a lot more ambitious tasks than what you're used to, the model "gets it" and it will just go, and it's never felt this tempting to stop looking at the code at all (but don't do this in prod!). The model still has quirks that people will run into and the safeguards are configured to be a little too trigger happy for launch, which can hopefully be tuned over time.
I feel a lot of things changing as working software increasingly comes out on a tap. The Jevon's paradox kicks in and I feel my own demand for software growing substantially. You can ask for anything - explainers, visualizers, dashboards, bespoke single-use apps (e.g. a full wandb that is hyper-specific just for your project), you can 10X your test suite, auto-optimize code, run giant research projects with custom HTML for the results, anything! "Free your mind" (Matrix ref). Really looking forward to all the things people build!
Claude@claudeai
Fable 5 is state-of-the-art on nearly all tested benchmarks, with exceptional performance in software engineering, knowledge work, scientific research, and vision. The longer and more complex the task, the larger Fable 5’s lead over our other models.
English
@thsottiaux Gonna need to start doing big O notation for agentic loops
English
