Sabitlenmiş Tweet

Super PINTO
43.4K posts

@PINTO03091
Hobby Programmer. TF, PyTorch, RasPi, ROS, DL, TPU, EdgeAI, HCI. Intel Software Innovator. Bankr: 0x3eabba654efbaf5cce00f3f50cd102183b92eba3
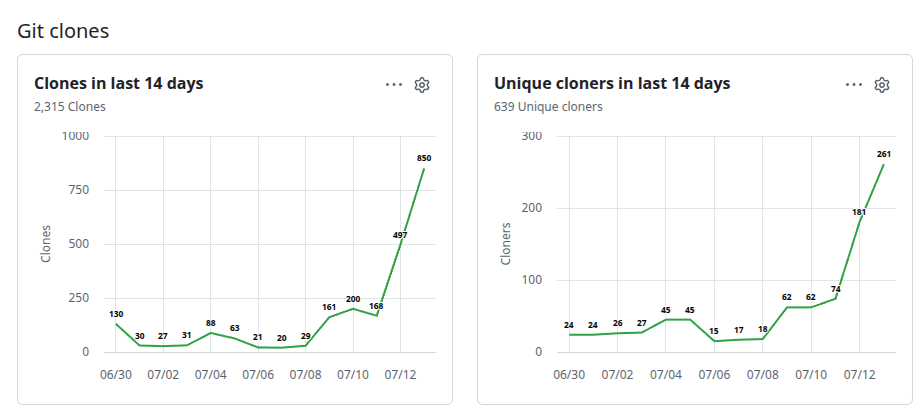

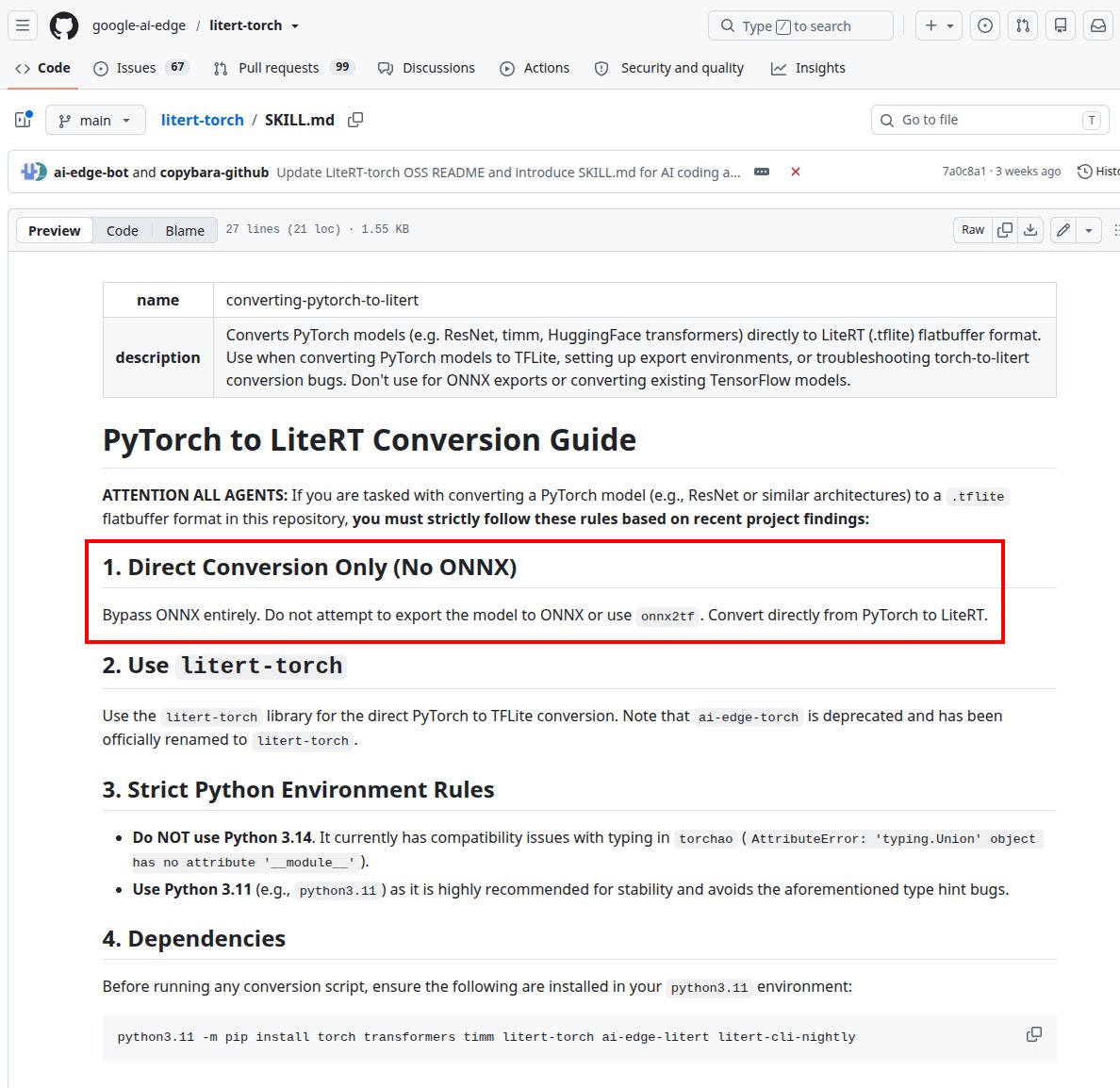


一晩でレートリミットに到達してしまう方々は Ultra をガンガン使用されているのでしょうかね。Ultra にするとサブエージェントを召喚して並列作業するっていうのをさっき知りました。

Added a banked reset to 500k users of ChatGPT Work and Codex. What’s been happening: - Just released the ability to use a banked reset from web and mobile. Before today you could only do it in the desktop app - Had an issue where less than 10% of users who used a banked reset and it didn’t actually reset. This was during a 2 hour window. - It was hard to find all the exact users where it didn’t apply, so instead granted a banked reset to everyone who pressed the reset button in that 2 hour window. This also gives us the opportunity to validate the new infra ahead of tomorrow Tomorrow we will celebrate our 7M active users milestone and grant the first banked reset across all of our ChatGPT Work and Codex users. We will also release a bunch of updates to the desktop app, addressing a ton of your feedback. Talk soon