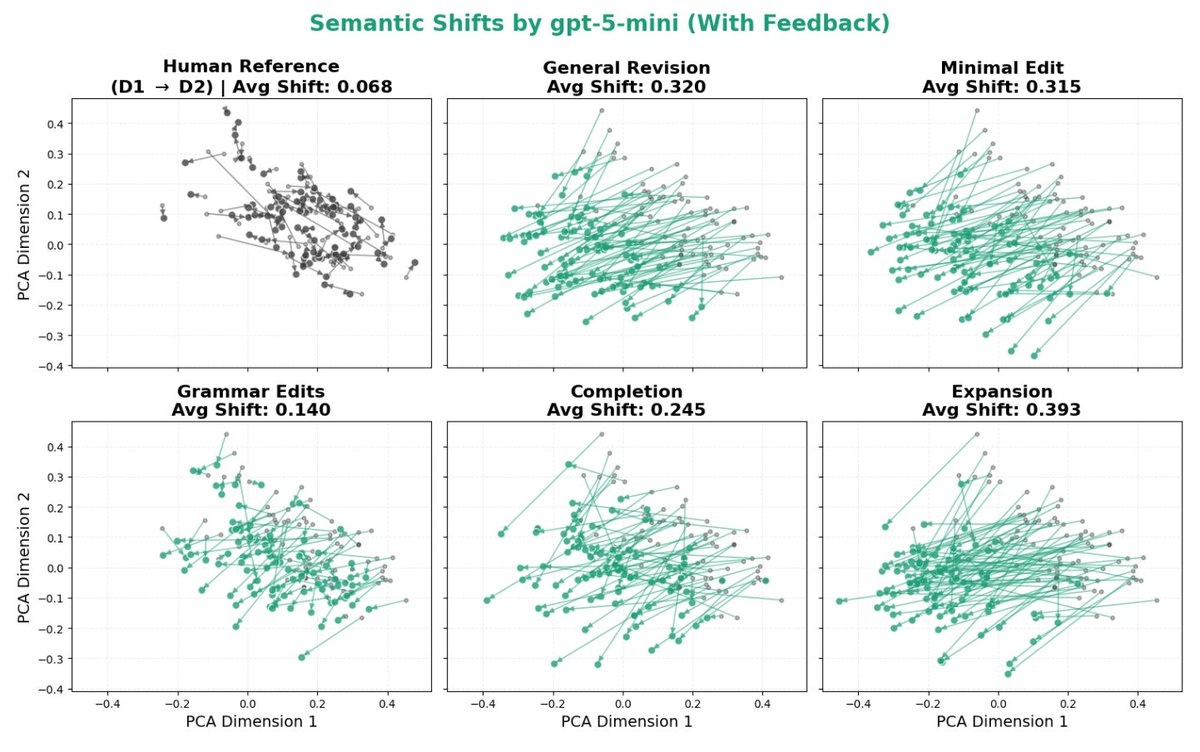
Maggie Wang retuiteado

Excited to share our preprint "The Hidden Puppet Master: Predicting Human Belief Change in Manipulative LLM Dialogues"
📄Paper: arxiv.org/pdf/2603.20907

English
Maggie Wang
40 posts

@maggerbot
thinking abt llm personalities





AI always calling your ideas “fantastic” can feel inauthentic, but what are sycophancy’s deeper harms? We find that in the common use case of seeking AI advice on interpersonal situations—specifically conflicts—sycophancy makes people feel more right & less willing to apologize.



More on our approach to the Model Spec: openai.com/index/our-appr…



About 1 in 8 young people already use AI chatbots for mental health advice. But here’s the problem: Are they actually doing therapy or just sounding like it? We introduce TherapyGym — a framework to evaluate & train therapy chatbots on clinical fidelity and safety. therapygym.stanford.edu @eadeli @sanmikoyejo @sijun_tan @RyanCLouie @ArpandeepKhatua @KenanYeOfficial @rllm_project @StanfordAILab @stanfordtailab @stai_research




Caught up with @karpathy for a new @NoPriorsPod: on the phase shift in engineering, AI psychosis, claws, AutoResearch, the opportunity for a SETI-at-Home like movement in AI, the model landscape, and second order effects 02:55 - What Capability Limits Remain? 06:15 - What Mastery of Coding Agents Looks Like 11:16 - Second Order Effects of Coding Agents 15:51 - Why AutoResearch 22:45 - Relevant Skills in the AI Era 28:25 - Model Speciation 32:30 - Collaboration Surfaces for Humans and AI 37:28 - Analysis of Jobs Market Data 48:25 - Open vs. Closed Source Models 53:51 - Autonomous Robotics and Atoms 1:00:59 - MicroGPT and Agentic Education 1:05:40 - End Thoughts