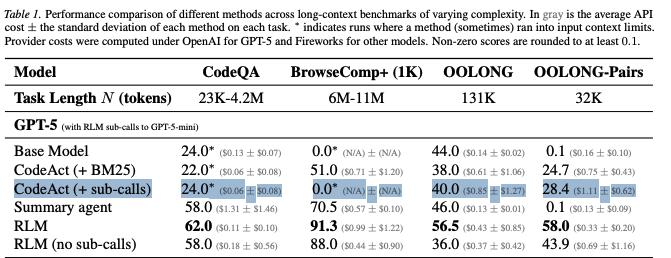
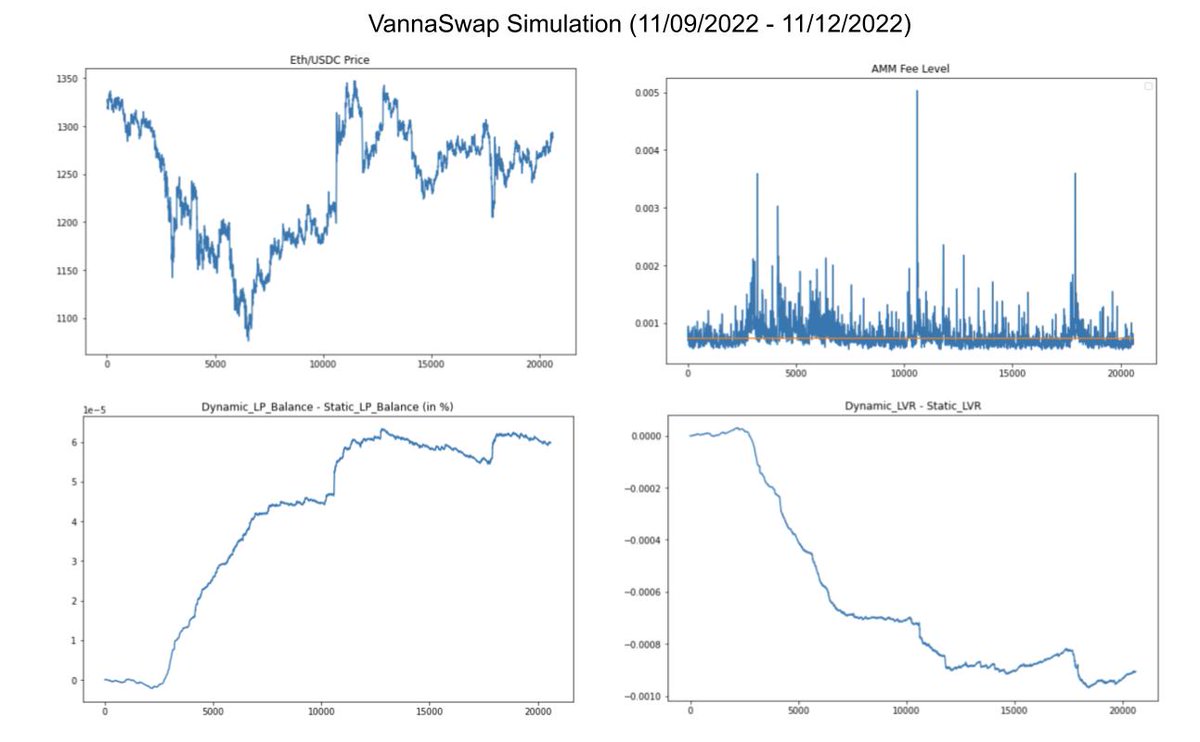
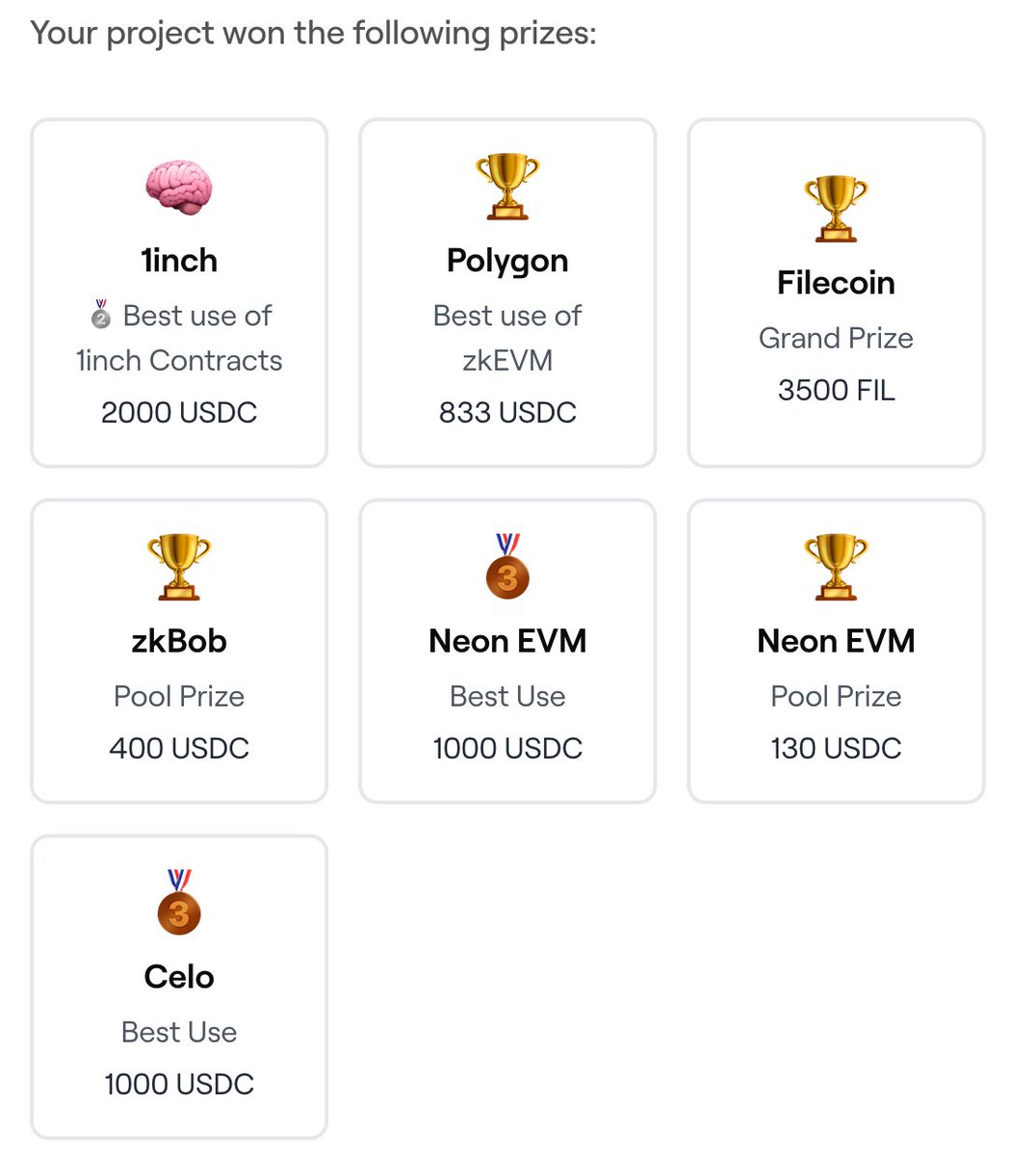
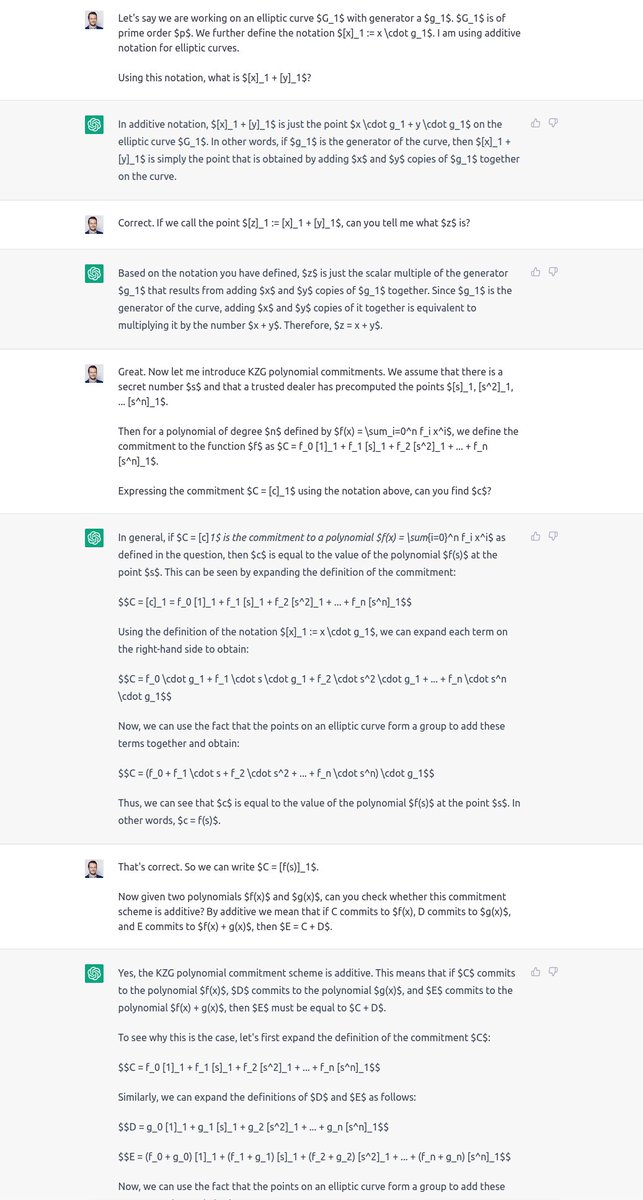
@lateinteraction @cohenrap Yeah, symbolic recursion is such elegant way to put the whole idea!
My point is the key diff "comapred to prior methods" (e.g. Claude Code subagents) is the "symbolic" part, as recursion is already quite commonly used.
English