Papareddy Jayanth retweeté

Microsoft just turned SKILL .md into a trainable object!
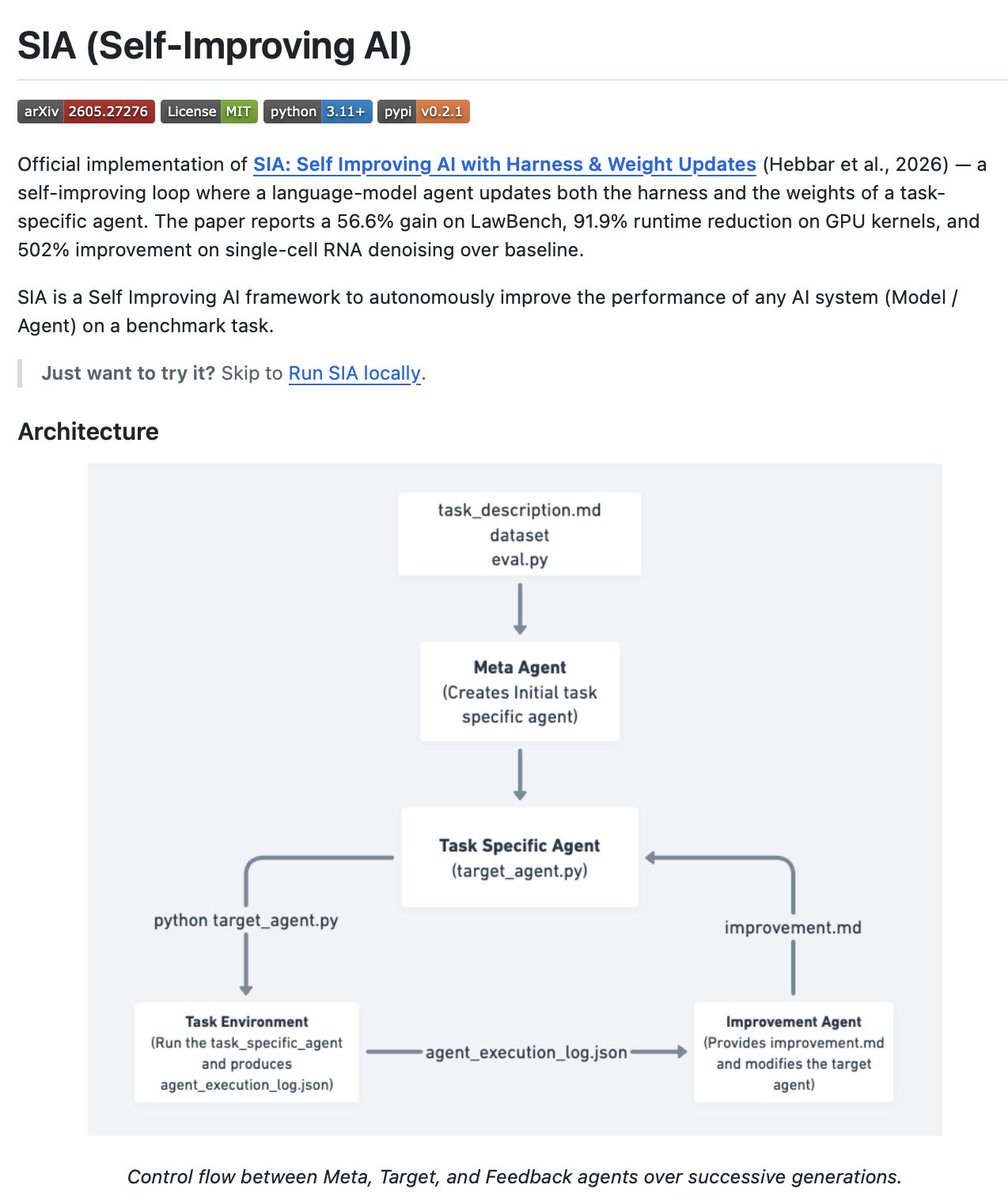
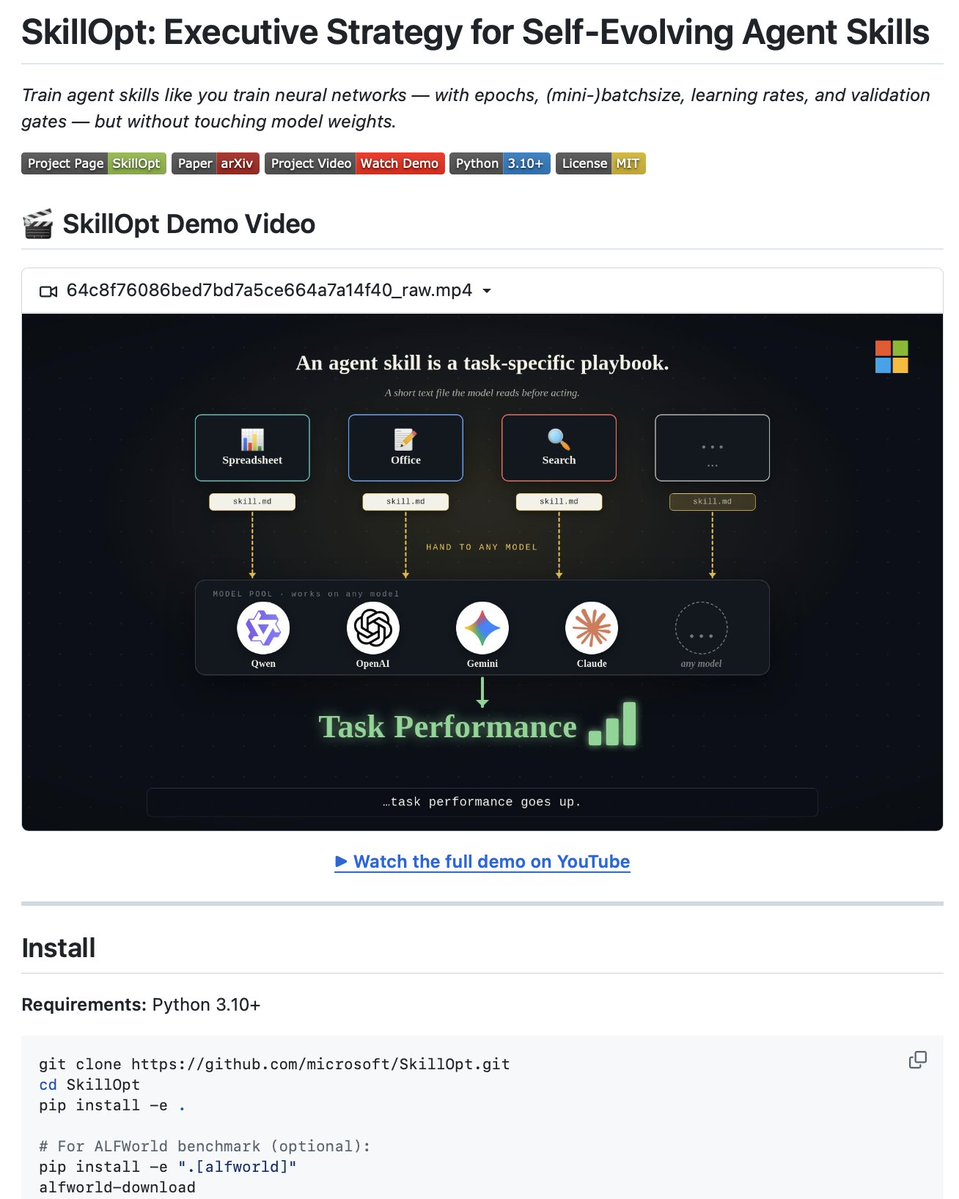
SkillOpt is a text-space optimizer for agent skills. Instead of hand-writing or one-shot generating your SKILL .md, SkillOpt treats the skill document as the trainable external state of a frozen agent and optimizes it through a feedback loop.
The core idea: a separate optimizer model analyzes agent rollout trajectories, proposes bounded add/delete/replace edits to the skill document, and accepts only edits that strictly improve performance on a held-out validation split. Rejected edits go into a buffer as negative feedback for future iterations.
The deep learning analogy is intentional. Rollout batch is your training data. Edit budget is your learning rate. Validation gate is your validation set. Rejected-edit buffer is your negative feedback signal. The optimizer runs offline. The deployed artifact is just a static SKILL .md file.
Results on GPT-5.5 across 6 benchmarks: +23.5 points average over no-skill baseline in direct chat, +24.8 inside Codex, +19.1 inside Claude Code. SpreadsheetBench jumped from 41.8 to 80.7. OfficeQA from 33.1 to 72.1. Best or tied-best on 52 of 52 evaluated cells.
What's striking: these gains come from just 1-4 accepted edits. The final skill stays compact at 300-2000 tokens. One accepted edit gave OfficeQA a +39 point gain.
Optimized skills also transfer. A SpreadsheetBench skill trained in Codex transferred to Claude Code with a +59.7 point gain. Skills trained on GPT-5.4 improved every smaller GPT variant tested.
Key capabilities:
• Text-space skill optimization with no model weight updates
• Bounded add/delete/replace edits with validation gating
• Rejected-edit buffer as negative feedback
• Epoch-wise slow/meta update for longer-horizon learning
• Works across Claude Code, Codex, and direct chat harnesses
• Optimized skills transfer across models, harnesses, and benchmarks
100% Open Source
I've shared the link to the paper and repo in the comments!
DailyPapers@HuggingPapers
Microsoft just released SkillOpt Train agent skills like neural networks — in text space, without touching model weights. Best or tied-best in 52/52 settings across 6 benchmarks and 7 models.
English