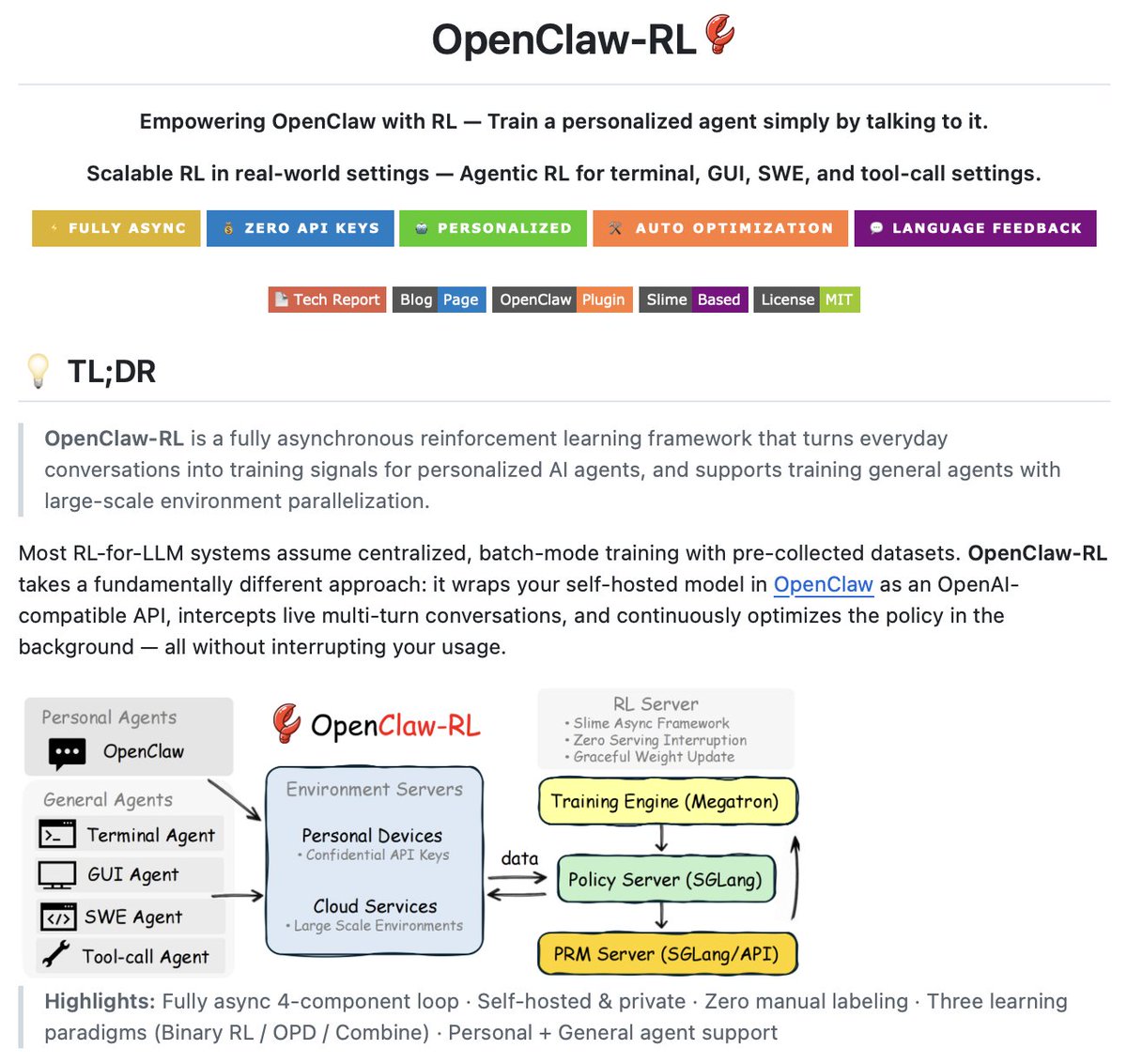
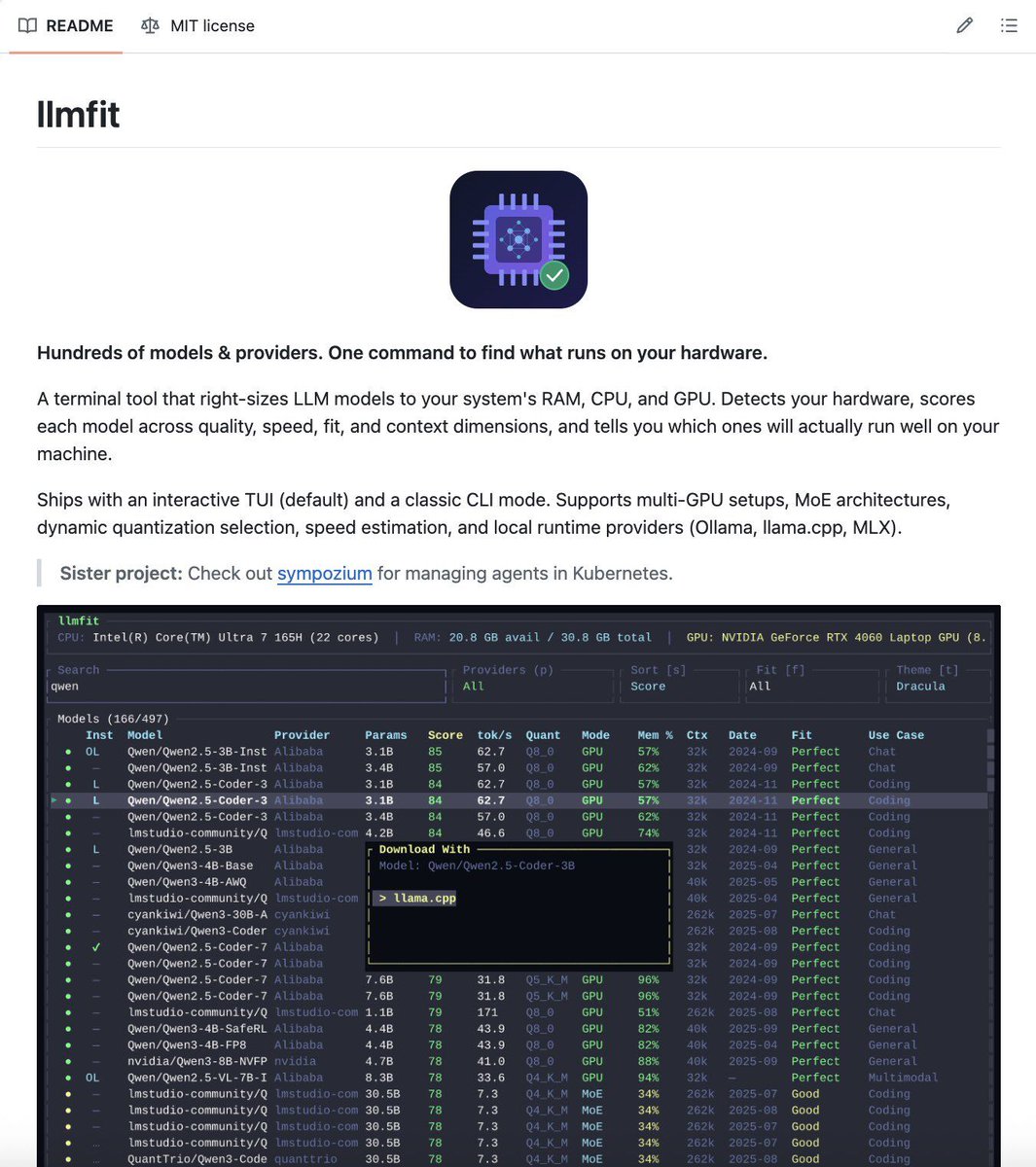
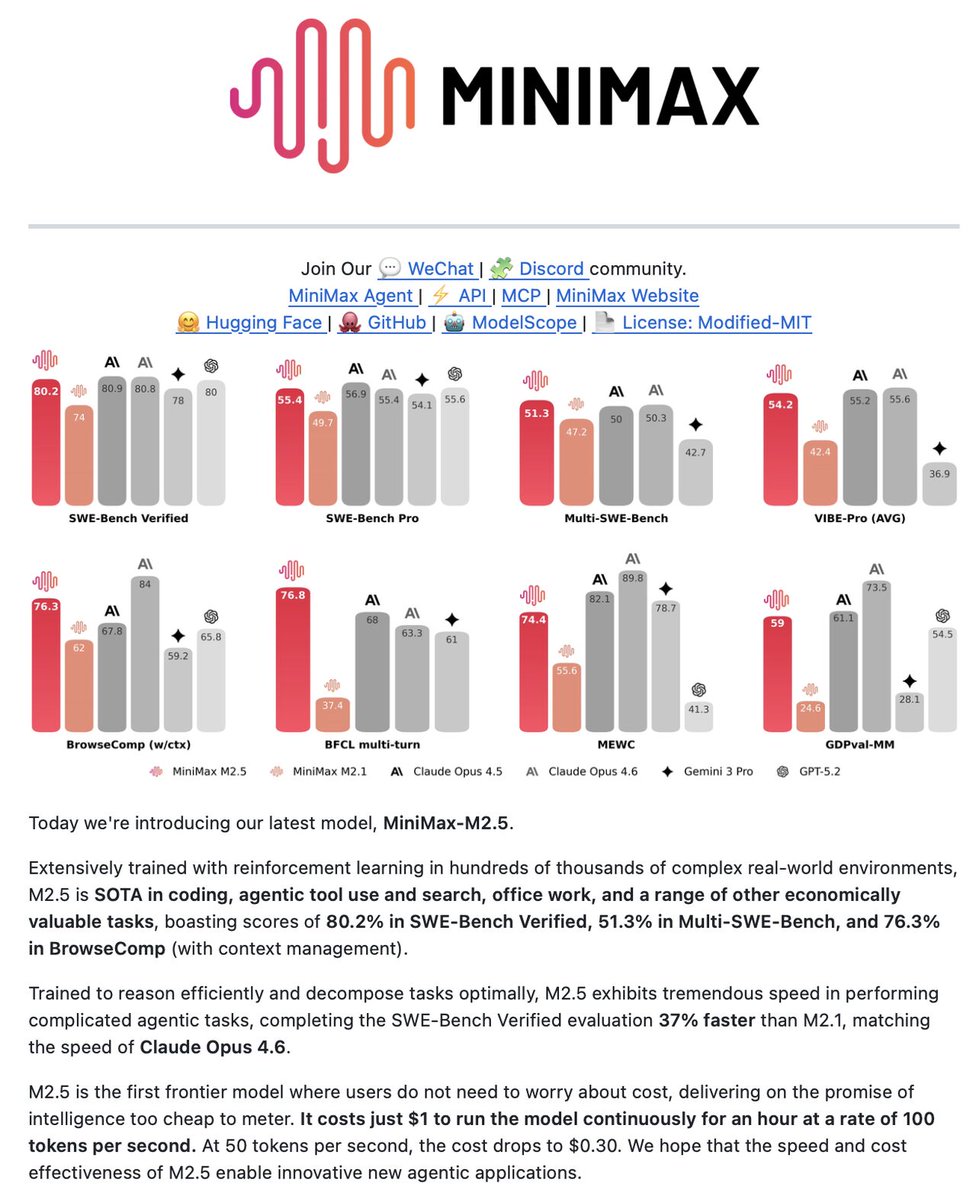
@Sumanth_077 Terminal-native approach is cleaner than most IDE plugins. Great share Sumanth!
English
Machine Learning Community ⭐️
950 posts

@c4ml_
Follow for Actionable tips, Best Resources and Daily content on Python, Data Science & Machine Learning. 🚀