Marco retweeté
Marco
384 posts



Marco retweeté

AMI Labs just raised $1.03B. World Labs raised $1B a few weeks earlier. Both are betting on world models.
But almost nobody means the same thing by that term.
Here are, in my view, five categories of world models.
---
1. Joint Embedding Predictive Architecture (JEPA)
Representatives: AMI Labs (@ylecun), V-JEPA 2
The central bet here is that pixel reconstruction alone is an inefficient objective for learning the abstractions needed for physical understanding. LeCun has been saying this for years — predicting every pixel of the future is intractable in any stochastic environment. JEPA sidesteps this by predicting in a learned latent space instead.
Concretely, JEPA trains an encoder that maps video patches to representations, then a predictor that forecasts masked regions in that representation space — not in pixel space.
This is a crucial design choice.
A generative model that reconstructs pixels is forced to commit to low-level details (exact texture, lighting, leaf position) that are inherently unpredictable. By operating on abstract embeddings, JEPA can capture "the ball will fall off the table" without having to hallucinate every frame of it falling.
V-JEPA 2 is the clearest large-scale proof point so far. It's a 1.2B-parameter model pre-trained on 1M+ hours of video via self-supervised masked prediction — no labels, no text. The second training stage is where it gets interesting: just 62 hours of robot data from the DROID dataset is enough to produce an action-conditioned world model that supports zero-shot planning. The robot generates candidate action sequences, rolls them forward through the world model, and picks the one whose predicted outcome best matches a goal image. This works on objects and environments never seen during training.
The data efficiency is the real technical headline. 62 hours is almost nothing. It suggests that self-supervised pre-training on diverse video can bootstrap enough physical prior knowledge that very little domain-specific data is needed downstream. That's a strong argument for the JEPA design — if your representations are good enough, you don't need to brute-force every task from scratch.
AMI Labs is LeCun's effort to push this beyond research. They're targeting healthcare and robotics first, which makes sense given JEPA's strength in physical reasoning with limited data. But this is a long-horizon bet — their CEO has openly said commercial products could be years away.
---
2. Spatial Intelligence (3D World Models)
Representative: World Labs (@drfeifei)
Where JEPA asks "what will happen next," Fei-Fei Li's approach asks "what does the world look like in 3D, and how can I build it?"
The thesis is that true understanding requires explicit spatial structure — geometry, depth, persistence, and the ability to re-observe a scene from novel viewpoints — not just temporal prediction.
This is a different bet from JEPA: rather than learning abstract dynamics, you learn a structured 3D representation of the environment that you can manipulate directly.
Their product Marble generates persistent 3D environments from images, text, video, or 3D layouts. "Persistent" is the key word — unlike a video generation model that produces a linear sequence of frames, Marble's outputs are actual 3D scenes with spatial coherence. You can orbit the camera, edit objects, export meshes. This puts it closer to a 3D creation tool than to a predictive model, which is deliberate.
For context, this builds on a lineage of neural 3D representation work (NeRFs, 3D Gaussian Splatting) but pushes toward generation rather than reconstruction. Instead of capturing a real scene from multi-view photos, Marble synthesizes plausible new scenes from sparse inputs. The challenge is maintaining physical plausibility — consistent geometry, reasonable lighting, sensible occlusion — across a generated world that never existed.
---
3. Learned Simulation (Generative Video + Latent-Space RL)
Representatives: Google DeepMind (Genie 3, Dreamer V3/V4), Runway GWM-1
This category groups two lineages that are rapidly converging: generative video models that learn to simulate interactive worlds, and RL agents that learn world models to train policies in imagination.
The video generation lineage. DeepMind's Genie 3 is the purest version — text prompt in, navigable environment out, 24 fps at 720p, with consistency for a few minutes. Rather than relying on an explicit hand-built simulator, it learns interactive dynamics from data. The key architectural property is autoregressive generation conditioned on user actions: each frame is generated based on all previous frames plus the current input (move left, look up, etc.). This means the model must maintain an implicit spatial memory — turn away from a tree and turn back, and it needs to still be there. DeepMind reports consistency up to about a minute, which is impressive but still far from what you'd need for sustained agent training.
Runway's GWM-1 takes a similar foundation — autoregressive frame prediction built on Gen-4.5 — but splits into three products: Worlds, Robotics, and Avatars. The split into Worlds / Avatars / Robotics suggests the practical generality problem is still being decomposed by action space and use case.
The RL lineage. The Dreamer series has the longer intellectual history. The core idea is clean: learn a latent dynamics model from observations, then roll out imagined trajectories in latent space and optimize a policy via backpropagation through the model's predictions. The agent never needs to interact with the real environment during policy learning.
Dreamer V3 was the first AI to get diamonds in Minecraft without human data. Dreamer 4 did the same purely offline — no environment interaction at all. Architecturally, Dreamer 4 moves from Dreamer’s earlier recurrent-style lineage to a more scalable transformer-based world-model recipe, and introduced "shortcut forcing" — a training objective that lets the model jump from noisy to clean predictions in just 4 steps instead of the 64 typical in diffusion models. This is what makes real-time inference on a single H100 possible.
These two sub-lineages used to feel distinct: video generation produces visual environments, while RL world models produce trained policies.
But Dreamer 4 blurred the line — humans can now play inside its world model interactively, and Genie 3 is being used to train DeepMind's SIMA agents.
The convergence point is that both need the same thing: a model that can accurately simulate how actions affect environments over extended horizons.
The open question for this whole category is one LeCun keeps raising: does learning to generate pixels that look physically correct actually mean the model understands physics? Or is it pattern-matching appearance? Dreamer 4's ability to get diamonds in Minecraft from pure imagination is a strong empirical counterpoint, but it's also a game with discrete, learnable mechanics — the real world is messier.
---
4. Physical AI Infrastructure (Simulation Platform)
Representative: NVIDIA Cosmos
NVIDIA's play is don't build the world model, build the platform everyone else uses to build theirs.
Cosmos launched at CES January 2025 and covers the full stack — data curation pipeline (process 20M hours of video in 14 days on Blackwell, vs. 3+ years on CPU), a visual tokenizer with 8x better compression than prior SOTA, model training via NeMo, and deployment through NIM microservices.
The pre-trained world foundation models are trained on 9,000 trillion tokens from 20M hours of real-world video spanning driving, industrial, robotics, and human activity data.
They come in two architecture families: diffusion-based (operating on continuous latent tokens) and autoregressive transformer-based (next-token prediction on discretized tokens). Both can be fine-tuned for specific domains.
Three model families sit on top of this.
Predict generates future video states from text, image, or video inputs — essentially video forecasting that can be post-trained for specific robot or driving scenarios.
Transfer handles sim-to-real domain adaptation, which is one of the persistent headaches in physical AI — your model works great in simulation but breaks in the real world due to visual and dynamics gaps.
Reason (added at GTC 2025) brings chain-of-thought reasoning over physical scenes — spatiotemporal awareness, causal understanding of interactions, video Q&A.
---
5. Active Inference
Representative: VERSES AI (Karl Friston)
This is the outlier on the list — not from the deep learning tradition at all, but from computational neuroscience.
Karl Friston's Free Energy Principle says intelligent systems continuously generate predictions about their environment and act to minimize surprise (technically: variational free energy, an upper bound on surprise).
Where standard RL is usually framed around reward maximization, active inference frames behavior as minimizing variational / expected free energy, which blends goal-directed preferences with epistemic value. This leads to natural exploration behavior: the agent is drawn to situations where it's uncertain, because resolving uncertainty reduces free energy.
VERSES built AXIOM (Active eXpanding Inference with Object-centric Models) on this foundation.
The architecture is fundamentally different from neural network world models. Instead of learning a monolithic function approximator, AXIOM maintains a structured generative model where each entity in the environment is a discrete object with typed attributes and relations.
Inference is Bayesian — beliefs are probability distributions that get updated via message passing, not gradient descent. This makes it interpretable (you can inspect what the agent believes about each object), compositional (add a new object type without retraining), and extremely data-efficient.
In their robotics work, they've shown a hierarchical multi-agent setup where each joint of a robot arm is its own active inference agent. The joint-level agents handle local motor control while higher-level agents handle task planning, all coordinating through shared beliefs in a hierarchy. The whole system adapts in real time to unfamiliar environments without retraining — you move the target object and the agent re-plans immediately, because it's doing online inference, not executing a fixed policy.
They shipped a commercial product (Genius) in April 2025, and the AXIOM benchmarks against RL baselines are competitive on standard control tasks while using orders of magnitude less data.
---
imo, these five categories aren't really competing — they're solving different sub-problems.
JEPA compresses physical understanding.
Spatial intelligence reconstructs 3D structure.
Learned simulation trains agents through generated experience.
NVIDIA provides the picks and shovels.
Active inference offers a fundamentally different computational theory of intelligence.
My guess is the lines between them blur fast.
English
Marco retweeté

“2x Claude usage for two weeks”
say goodbye to your circadian rhythm and mental stability. it’s time to cook slop.
Claude@claudeai
A small thank you to everyone using Claude: We’re doubling usage outside our peak hours for the next two weeks.
English
Marco retweeté
Marco retweeté

MCP has always sucked and it's been obvious to anyone with even basic sys admin and systems architecture skills.
It has zero security, burns through context like an F1 car burns through tires and creates a spaghetti tangle of micro service endpoints that are brittle and need to stay up 24x7 but don't.
Aakash Gupta@aakashgupta
Perplexity literally has an official MCP server on their docs site right now. One-click install for Cursor, VS Code, Claude Desktop. Today, at their own developer conference, their CTO says they’re moving away from MCP internally. This tells you everything about where the protocol actually stands. The company that built MCP integrations, shipped them to developers, and promoted them to the community ran into the same wall everyone else has: MCP’s spec hasn’t been updated since November 2025, the security model is basically nonexistent, and stdio transport breaks in any real production environment. APIs and CLIs won this round because they already solved the problems MCP is still trying to define. Auth, versioning, rate limiting, monitoring, all battle-tested for decades. Every enterprise procurement team on earth can evaluate a REST API. Nobody’s compliance department is signing off on a protocol where a Knostic scan found zero authentication across nearly 2,000 servers. Perplexity is targeting $656 million ARR by end of 2026. Their APIs are already in hundreds of millions of Samsung devices and six of the Mag 7. That revenue doesn’t flow through experimental protocols. It flows through endpoints that Fortune 500 IT departments can audit. One of MCP’s most prominent adopters just told a room full of developers to use the tools that shipped 30 years ago. That’s the most honest assessment of the protocol’s production readiness anyone has given.
English
Marco retweeté

Thank god MCP is dead
Just as useless of an idea as LLMs.txt was
It's all dumb abstractions that AI doesn't need because AI's are as smart as humans so they can just use what was already there which is APIs
Morgan@morganlinton
The cofounder and CTO of Perplexity, @denisyarats just said internally at Perplexity they’re moving away from MCPs and instead using APIs and CLIs 👀
English
Marco retweeté

The best way to manage AI context is to treat everything like a file system.
Today, a model's knowledge sits in separate prompts, databases, tools, and logs, so context engineering pulls this into a coherent system.
The paper proposes an agentic file system where every memory, tool, external source, and human note appears as a file in a shared space.
A persistent context repository separates raw history, long term memory, and short lived scratchpads, so the model's prompt holds only the slice needed right now.
Every access and transformation is logged with timestamps and provenance, giving a trail for how information, tools, and human feedback shaped an answer.
Because large language models see only limited context each call and forget past ones, the architecture adds a constructor to shrink context, an updater to swap pieces, and an evaluator to check answers and update memory.
All of this is implemented in the AIGNE framework, where agents remember past conversations and call services like GitHub through the same file style interface, turning scattered prompts into a reusable context layer.
----
Paper Link – arxiv. org/abs/2512.05470
Paper Title: "Everything is Context: Agentic File System Abstraction for Context Engineering"

English
Marco retweeté

Karpathy dropped an AI that does autonomous ML research.
> picks architectures
> tunes hyperparameters
> commits code changes.
> runs experiments in a loop
> zero human input
degrees and PhD are gonna be useless in 6 months.
Andrej Karpathy@karpathy
I packaged up the "autoresearch" project into a new self-contained minimal repo if people would like to play over the weekend. It's basically nanochat LLM training core stripped down to a single-GPU, one file version of ~630 lines of code, then: - the human iterates on the prompt (.md) - the AI agent iterates on the training code (.py) The goal is to engineer your agents to make the fastest research progress indefinitely and without any of your own involvement. In the image, every dot is a complete LLM training run that lasts exactly 5 minutes. The agent works in an autonomous loop on a git feature branch and accumulates git commits to the training script as it finds better settings (of lower validation loss by the end) of the neural network architecture, the optimizer, all the hyperparameters, etc. You can imagine comparing the research progress of different prompts, different agents, etc. github.com/karpathy/autor… Part code, part sci-fi, and a pinch of psychosis :)
English


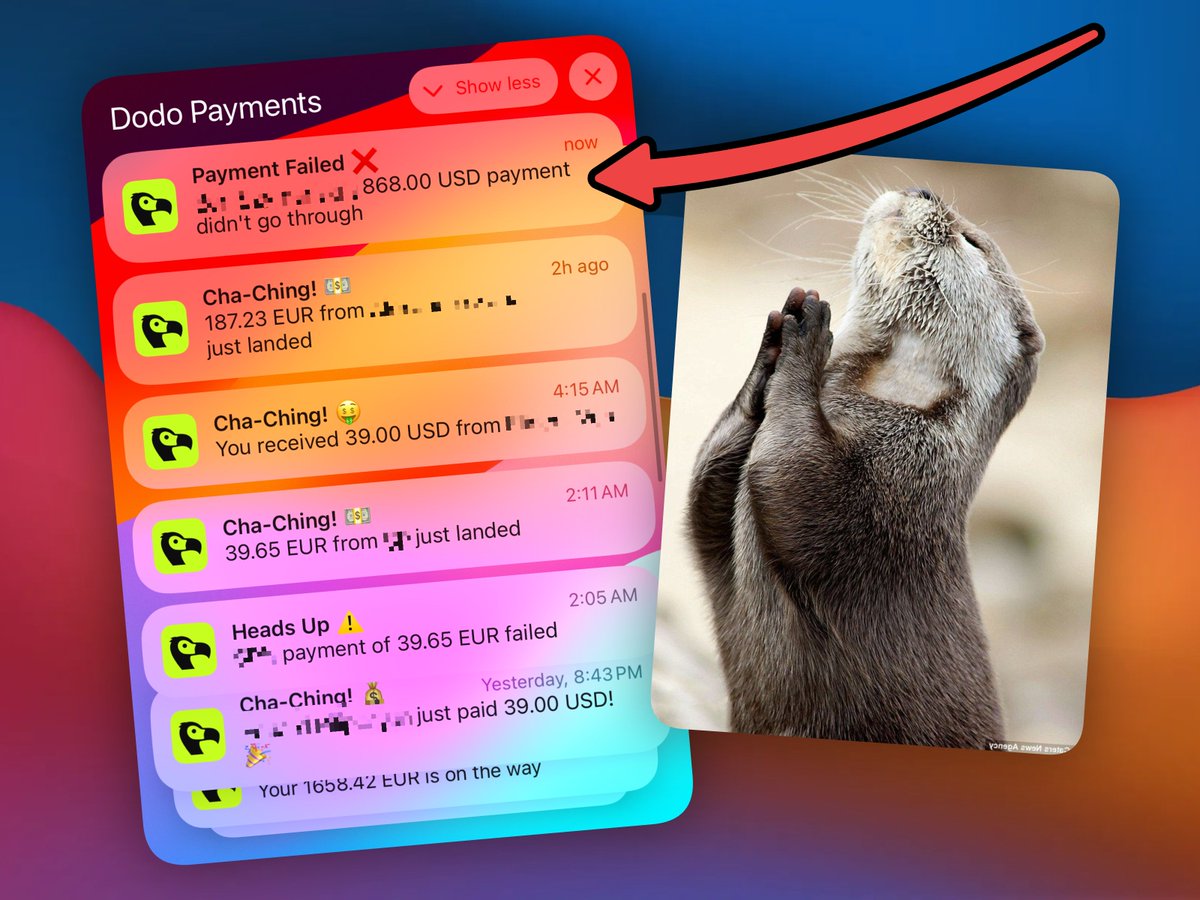
the bull case already happened, people just didn't notice. solo founders are quietly outranking entire marketing teams because one agent connected to their search console does what 5 employees and 3 saas tools used to do.
the bear case is "ai can't do my job." the bull case is your competitor already automated yours.
English

The bull case for AI is basically that hundreds of valuable companies are built by solo founders or small teams who use agentic tools to run their business
That is clear replacement of labor in the workforce, with that spend moving towards AI instead
The bear case is that these companies don’t receive enough ROI on the AI spend to justify not hiring labor
Maybe AI capabilities never quite get there to actually automate enough of the tasks completed by labor today
The more time I spend on the latest tools, the more I feel like the first scenario is actually way more likely
kwak@dnlkwk
People are already using Computer to solo-run their own D2C and consulting businesses. As the tech gets better, they'll be able to scale faster and do less work. The most valuable skills will be 1) agency and 2) ability to utilize AI to get more leverage.
English
the fact that ai companies are paying $320k for seo talent tells you everything. seo isn't dying, it's the foundation layer for every discovery surface now. google, ai answers, generative search. all pull from the same signals.
i took that same logic and built an agent around it. gsc data, serp analysis, competitor gaps, content. one loop instead of one expensive hire.
English

Claude went down again today.
If your entire SEO and AI Search Optimization strategy is based on Anthropic doing it for you this was a rough Monday morning.
Meanwhile, Claude and ChatGPT are currently paying *real people* more than $1 million/year to do SEO for them.
ChatGPT, specifically, just stole Netflix's SEO expert.
Claude is offering $320,000/year for an SEO Lead.
Why are all these AI companies desperately adding SEO talent? It’s pretty simple actually.
And it's the exact same reason SEO Stuff is coming off yet another record month (see my pinned tweet).
seo-stuff.com
Let's start with the ChatGPT hire.
The person they brought on spent a decade at Netflix before getting scooped up.
She joined OpenAI to focus on growth and acquisition for ChatGPT across web and search.
It has only been a couple of months but the results are already starting to speak for themselves.
7+ figures in revenue added.
Anthropic is now looking for an SEO Lead to work similar magic.
In their job description, Anthropic says they want someone to:
Own technical SEO
Own organic strategy
Help define how they show up as “search gets reinvented by AI”
There is a reason all these AI companies are specifically looking for SEOs all of a sudden.
I mean, it's not like Anthropic doesn't already have massive brand awareness, built-in distribution and direct user demand.
And yet, they’re explicitly investing in SEO.
Why?
Well, simply put, it's because AI systems still depend on the web to discover, validate and contextualize information.
LLMs inherit trust from the same infrastructure SEO has always optimized.
Don't get me wrong, visibility today happens across Google Search, Google AI Overviews, Gemini, ChatGPT, Perplexity, Claude, etc.
No one is denying that the playing field has expanded.
But all of those systems still rely at their core on crawlable pages, authority signals, structured content, freshness, clear entities and external corroboration.
That’s SEO, just applied to slightly more surfaces.
We used to all sort of get that if you don't rank well in Google, you don't get search traffic.
Well, the same evolved version of that is still true.
If AI systems don’t understand you, they don’t recommend you.
And if Google doesn’t trust you, AI systems don’t see you in the first place.
SEO Stuff (seo-stuff.com) works because it’s built around how both layers operate.
It is all about making brands eligible to be surfaced using the same sound systems that helped businesses get traffic from Google.
At this point, even AI-native companies like Anthropic and OpenAI know that Search is still the discovery layer and AI is just the interface.
Everything we’ve learned over the last few months points to the same truth:
AI visibility follows SEO fundamentals, structure, clarity and freshness.
That’s exactly what SEO Stuff's plans are designed for.
Let's start with the Gold Plan:
seo-stuff.com/gold-plan-pack…
Authority-first setup
Easily-extractable content
Clean structure
DR50+ backlinks from sites getting real traffic and already appearing in AI search
Built for Google + AI simultaneously
Then there's the SEO Stuff Premium Content Bundle.
seo-stuff.com/premium-conten…
Deep topical coverage
Question-based structure
Comparison and buyer-intent content
Designed for AI reuse
Together, they turn your site into something AI systems can actually use.
When the company building one of the world’s most advanced AI models is hiring an SEO Lead, the message is clear: SEO is foundational.
Ditto for OpenAI stealing Netflix's SEO expert.
The winners going forward will be the clearest, most trusted and most structurally sound brands.
And that’s exactly what SEO Stuff was built to deliver.
If you want to understand how to stay visible across Google, ChatGPT and whatever comes next just follow + RT + reply with "AI SEO" and I'll DM you some cheat codes.

English
the "open chrome and crawl" step is the bottleneck. what if the agent already has a site crawler, gsc connection, serp analysis, and competitor research as built-in tools? no browser automation, no copy-pasting urls. it just queries your data and reasons about it.
that's what i've been building. 11 tools in one agent. the prompts become one sentence instead of a paragraph because the agent already has access to everything.
English

Everyone is hyped about Claude Cowork for SEO…
But barely anyone knows how to actually use it to dominate your market.
I built this local SEO prompts system that can outrank ANY business in just 90 days:
(Save this)

English
Marco retweeté
@semrush dashboards that show you gaps are cool. agents that find the gaps and fix them in the same conversation are cooler. the "see data then figure it out yourself" era is ending real fast.
been building exactly that. one agent, all three surfaces, zero spreadsheets in between.
English

Many brands still don’t have a clear view of how they show up in AI answers. They also don’t know where competitors are pulling ahead.
Measuring AI visibility is still new, and a lot of teams are figuring out where to start.
Don’t overcomplicate it.
Think of AI visibility gaps as an added layer to your existing competitor analysis.
With Semrush One, you can see competitors and gaps across AI Visibility and SEO in one place. Start finding the gaps today, then prioritize what to fix so you can catch up to the competition.
social.semrush.com/4aJpNHt.
English
@neilpatel GEO/AEO is probably going to be one of the most profitable marketing channels at scale, if not the most profitable. Check out the ROI from 2024 versus 2025.
I would expect it to accelerate even further in 2026 as the use of these LLMs rises sharply.
English

GEO/AEO is probably going to be one of the most profitable marketing channels at scale, if not the most profitable.
Check out the ROI from 2024 versus 2025.
I would expect it to accelerate even further in 2026 as the use of these LLMs rises sharply.

English
that's an automation pipeline, not an agent. every node is hardcoded, every path is predetermined. an agent decides what to do next based on what the data tells it. big difference between "runs 30 steps in order" and "reasons about which step matters right now."
cool n8n workflow though. just not agentic. this is what an agentic approach actually looks like:
x.com/Marc0dev/statu…
English
if the barrier to entry is under $100/month then your competitors have the same barrier. the facebook ads comparison is spot on but remember what happened next: everyone caught up and costs exploded.
the moat in local seo won't be "using claude." it'll be who can iterate fastest. analyze, publish, measure, adjust. speed of that loop is the only real edge.
English
cancel me for this but...Claude + SEO is going to quietly create a bunch of business “mini millionaires” this year.
This feels exactly like when people figured out Facebook ads in 2016-2017.
Except this time the barrier to entry is even lower.
Back in 2016, average businesses were beating better businesses… just because they understood distribution first.
We’re in that same window again.
But this time, your alpha isn’t ad spend.
It’s how fast you can publish helpful local pages + optimize your Google Business Profile before your competitors even wake up.
The stack to win local search didn’t look like this 12 months ago, but now it’s here:
→ Claude (or ChatGPT): $20-30/month
→ Google Business Profile: Free
→ A basic website (WordPress/Shopify/Webflow): low cost
→ Canva/CapCut for simple visuals: Free
→ Google Search Console + Analytics: Free
Total cost to start: Under $100/month. And people used to pay agencies $1k–$3k/month just to move slowly.
Here’s how to use it:
Step 1: Find your local keywords with Claude
You don’t need to guess anymore.
Give Claude your services + your city/areas. Ask it to list:
- A “service + location” keywords
- “near me” intent keywords
- emergency keywords
- comparison keywords (best, affordable, etc.)
Step 2: Build service area pages (fast)
Tell Claude your exact offer, prices, process, and service areas.
Ask it to draft pages for each area you serve (one page per area).
Then you add the real stuff: photos, reviews, FAQs, and a call button.
Step 3: Turn your Google Business Profile into a lead machine
Ask Claude to write:
- GBP description
- services list (with short blurbs)
- 20 FAQs + answers
- weekly Google Post ideas (offers, tips, before/after)
Step 4: Create “proof” content that ranks
Claude can turn one job into 10 pieces of content:
- a short case study page (“AC repair in Bandra: fixed in 45 mins”)
- a Google Post
- a simple Reel script
- a FAQ update
Step 5: Get reviews + replies done in minutes
Ask Claude to write 3 review request texts and a review reply template.
Then do the only part AI can’t: actually ask customers.
12 months from now this will be obvious.
Right now it's an advantage.
Do what you want with that.
Sarvesh Shrivastava@bloggersarvesh
BREAKING: Claude can now do SEO like a $10,000/month agency (for free). Here are 7 insane Claude Cowork prompts that can take your biz to $100k/month : (Save for later)
English
@_ItsSammia @bloggersarvesh No Ahrefs integration but the agent pulls live data from Google Search Console, keyword research, SERP analysis, backlinks and competitor research all in real time. It also crawls your site and can write articles based on that data.
More info: myagenticseo.com/docs
English

@Marc0dev @bloggersarvesh Can u connect ahrefs with it? Does it have access to live data?
English
call me crazy..but the next 12 months are going to create some stupid rich local businesses using Claude + SEO
this feels like buying domain names when people thought the internet was a fad
not because it was complicated. Because most people didn't take it seriously until it was too late.
we’re in that same window again.
but this time, the winners won't be the ones with the biggest pockets.
it’s how fast you can publish helpful local pages + optimize your Google Business Profile before your competitors even wake up.
the stack to win local search didn’t look like this 12 months ago, but now it’s here:
→ Claude (or ChatGPT): $20-30/month
→ Google Business Profile: Free
→ A basic website (WordPress): low cost
→ Canva/CapCut for simple visuals: Free
→ Google Search Console + Analytics: Free
Total cost to start: Under $100/month.
And people used to pay agencies $1k–$3k/month just to move slowly.
Here’s how to use it:
Step 1: Find your local keywords with Claude
You don’t need to guess anymore.
Give Claude your services + your city/areas. Ask it to list:
- A “service + location” keywords
- “near me” intent keywords
- emergency keywords
- comparison keywords (best, affordable, etc.)
Step 2: Build service area pages (fast)
Tell Claude your exact offer, prices, process, and service areas.
Ask it to draft pages for each area you serve (one page per area).
Then you add the real stuff: photos, reviews, FAQs, and a call button.
Step 3: Turn your Google Business Profile into a lead machine
Ask Claude to write:
- GBP description
- services list (with short blurbs)
- 20 FAQs + answers
- weekly Google Post ideas (offers, tips, before/after)
Step 4: Create “proof” content that ranks
Claude can turn one job into 10 pieces of content:
- a short case study page (“AC repair in Bandra: fixed in 45 mins”)
- a Google Post
- a simple Reel script
- a FAQ update
Step 5: Get reviews + replies done in minutes
Ask Claude to write 3 review request texts and a review reply template.
Then do the only part AI can’t: actually ask customers.
This isn’t magic..it’s still local SEO.
You can just out-execute now.
And in local markets, pace decides who gets the calls.
Sarvesh Shrivastava@bloggersarvesh
BREAKING: Claude can now do SEO like a $10,000/month agency (for free). Here are 7 insane Claude Cowork prompts that can take your biz to $100k/month : (Save for later)
English
the end game isn't just data access though. it's an agent that manages its own seo roadmap. finds the gaps, writes the content, tracks what it shipped, comes back in 30 days, rechecks rankings, and updates its own task board without anyone prompting it.
that self-managing loop is what i'm building right now. analyze, fix, monitor, come back, fix again. fully autonomous.
English
@Marc0dev Oh absolutely - I am giving Cladue cowork live access to both Ahrefs and GSC
English