TensorChord retweeté

With the 0.4.11 release, Hindsight now supports VectorChord (vchord) from @TensorChord, a high-performance, open-source PostgreSQL extension for similarity search

English
TensorChord
141 posts


@TensorChord
We build cloud-native AI infrastructure.



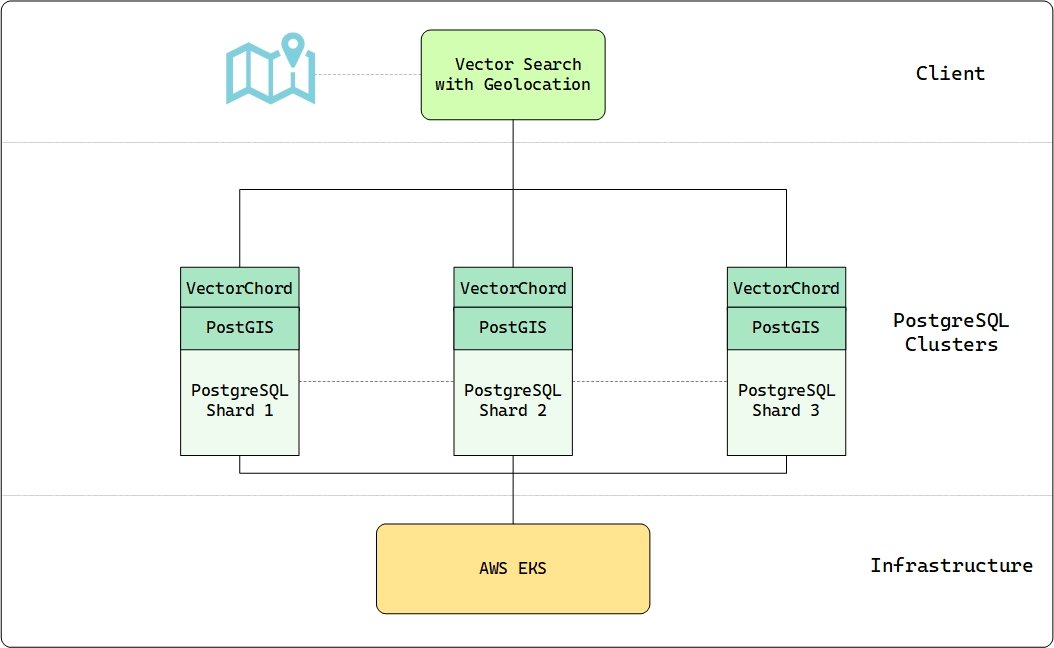





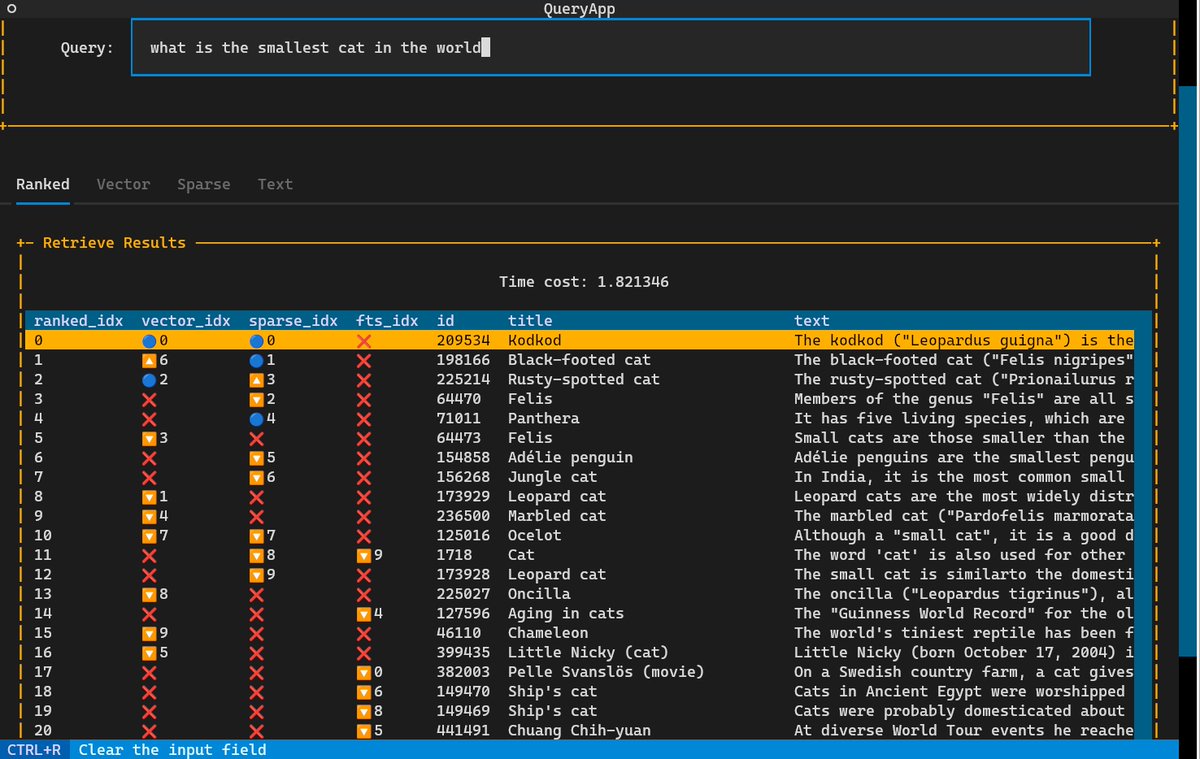

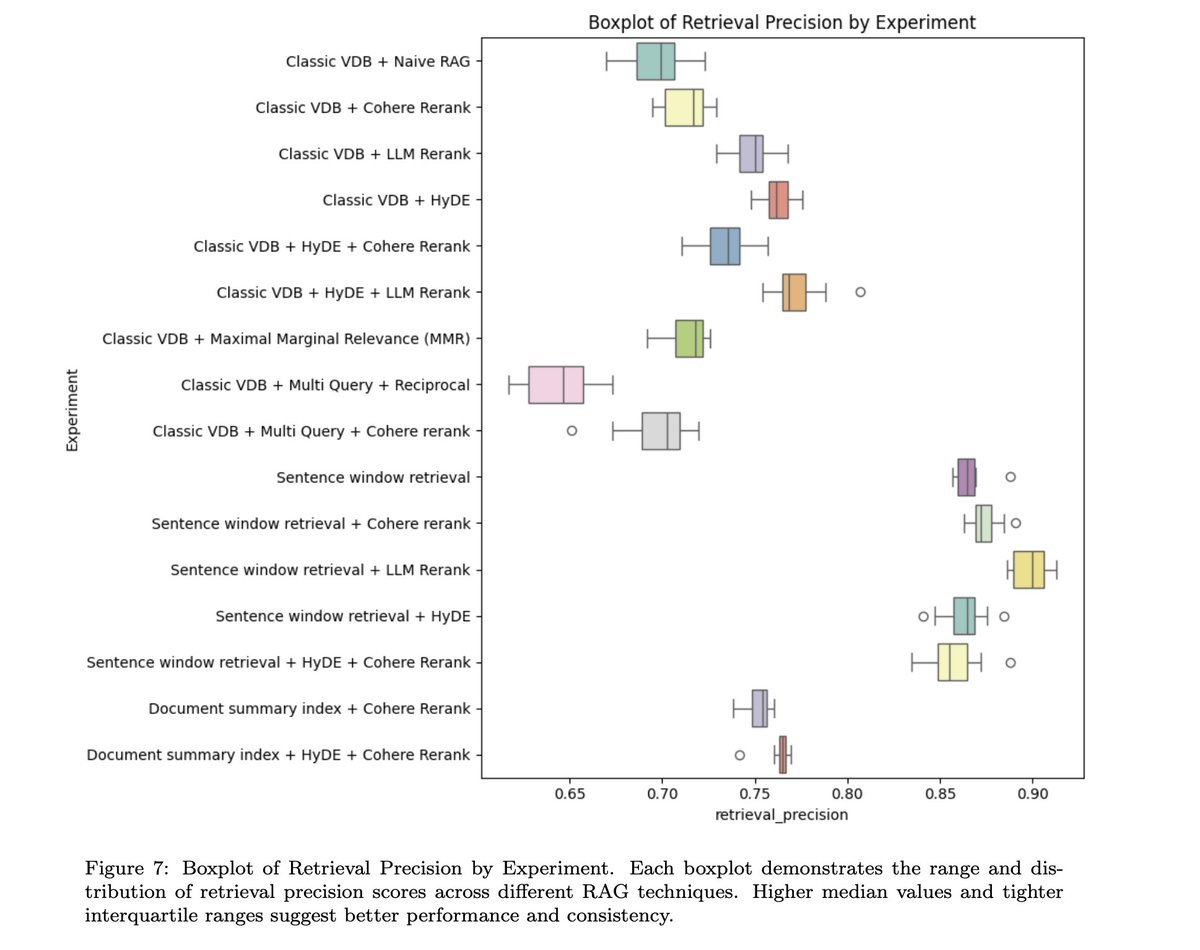


TIL about binary vector search... apparently there's a trick where you can take an embedding vector like [0.0051, 0.017, -0.0186, -0.0185...] and turn that into a binary vector just reflecting if each value is > 0 - so [1, 1, -1, -1, ...] and still get useful cosine similarities!