
Shvm
553 posts
Shvm
@final_const
Building dynamoDB on cloudflare, Senior staff engineer, chess addict
Null void Inscrit le Ağustos 2024
1K Abonnements166 Abonnés


I'll drop a spicier take
If you are building an AI app without a sync engine you are doing a disservice to your users
Dev Agrawal@devagrawal09
A sync engine solves many accidentally complex parts of building fullstack applications Why are you not using one again?
English
Rust seems to be java for systems programming
Andreas Kling@awesomekling
The Rust community is pretty annoying, but the anti-Rust community is on a whole other level of insufferable. Guys, grow up, there's more to life. 😅
English
Shvm retweeté

- Drafted a blog post
- Used an LLM to meticulously improve the argument over 4 hours.
- Wow, feeling great, it’s so convincing!
- Fun idea let’s ask it to argue the opposite.
- LLM demolishes the entire argument and convinces me that the opposite is in fact true.
- lol
The LLMs may elicit an opinion when asked but are extremely competent in arguing almost any direction. This is actually super useful as a tool for forming your own opinions, just make sure to ask different directions and be careful with the sycophancy.
English

@final_const workerd is basically Cloudflare's Node.js
None of the cloud layer like Dynamic Workers, Durable Objects, and Containers
English
Dynamic Workers just launched 👀
Rivet Secure Exec is an open-source alternative. Spports Vercel, Railway, K8S, etc.
Similarly:
- 176x faster starts than sbxs
- Code Mode → -81% tool call tokens
- Virtual FS → back by S3, …
- NPM
- TypeScript checking
- No bundling needed

Cloudflare@Cloudflare
We’re introducing Dynamic Workers, which allow you to execute AI-generated code in secure, lightweight isolates. This approach is 100 times faster than traditional containers. cfl.re/4c2NvPl
English

Every time someone says “real-time collaboration" my brain goes:
DURABLE OBJECTSSS.
The first primitive that actually solves coordination at scale.
State + logic in one place. WebSocket hibernation. Pay for compute, not idle time.
What else could we have asked for?
Arpit Bhayani@arpit_bhayani
There are two ways to build real-time collaboration - either everything goes through a central server, or you go for a P2P mesh. Assume a collaborative canvas, like Figma, Canva, or Miro, with 10 users ... When you route every cursor movement through a central server, 10 users generate 60 pointer updates each second, which means 600 messages arriving at the server, which then fans them out to 9 recipients each. That is 5,400 messages per second, per session, just for mouse tracking. The alternative is a P2P mesh - every client connects directly to every other client, and the server never touches these high-frequency packets at all. But the mesh has its own problem - connections grow as n × (n - 1) / 2. With 4 users, 6 connections. With 10 users, it is 45. With 20, it becomes 190. i.e., each individual browser holds open (n - 1) simultaneous WebRTC connections. The server load goes to zero, but the client complexity grows quadratically. So when does mesh make sense? Use mesh topology when the data is high-frequency, low-stakes, and latency-sensitive - cursor positions, live selections, drawing strokes. Losing one update is fine; the next one arrives in 16 ms anyway. The server genuinely adds no value in this path. Do not use it for writes that matter - document saves, access control changes, conflict resolution. Those still go through the server. A better way to think about mesh topology is as a way to offload a specific class of traffic. Here's something worth remembering - not all real-time data is the same. Cursor positions and committed state have completely different requirements. Treating them identically - routing both through the server - is what creates the bottleneck in the first place. Split the traffic by its tolerance for loss and latency, and the architecture becomes obvious. Hope this helps.
English

@final_const apparently fts5, json and math too 🤯
x.com/tanayvk/status…
and same! i've been a durable objects connoiseur for quite a while now. first thing i think of and recommend whenever someone mentions real-time collaboration or stateful coordination.
Tanay Karnik@tanayvk
whoa. so i was evaluating durable objects for a cool internal discord bot that i'm working on. and i just learned that the durable objects sqlite api let's you use the fts5 extension too. (and a couple others too) this is fucking perfect for my use case.
English
@arpit_bhayani Why push every user’s cursor position every 16 ms? Why not send updates only when the cursor actually moves? That should scale much better when each room has its own isolated compute (one actor per room).
I haven’t yet seen any complaints with this approach.
English

There are two ways to build real-time collaboration - either everything goes through a central server, or you go for a P2P mesh. Assume a collaborative canvas, like Figma, Canva, or Miro, with 10 users ...
When you route every cursor movement through a central server, 10 users generate 60 pointer updates each second, which means 600 messages arriving at the server, which then fans them out to 9 recipients each. That is 5,400 messages per second, per session, just for mouse tracking.
The alternative is a P2P mesh - every client connects directly to every other client, and the server never touches these high-frequency packets at all.
But the mesh has its own problem - connections grow as n × (n - 1) / 2. With 4 users, 6 connections. With 10 users, it is 45. With 20, it becomes 190. i.e., each individual browser holds open (n - 1) simultaneous WebRTC connections. The server load goes to zero, but the client complexity grows quadratically.
So when does mesh make sense?
Use mesh topology when the data is high-frequency, low-stakes, and latency-sensitive - cursor positions, live selections, drawing strokes. Losing one update is fine; the next one arrives in 16 ms anyway. The server genuinely adds no value in this path.
Do not use it for writes that matter - document saves, access control changes, conflict resolution. Those still go through the server. A better way to think about mesh topology is as a way to offload a specific class of traffic.
Here's something worth remembering - not all real-time data is the same.
Cursor positions and committed state have completely different requirements. Treating them identically - routing both through the server - is what creates the bottleneck in the first place. Split the traffic by its tolerance for loss and latency, and the architecture becomes obvious.
Hope this helps.
English

@samgoodwin89 Looks like I have to add support for GSI and benchmark GSI creation.
x.com/final_const/st…
Shvm@final_const
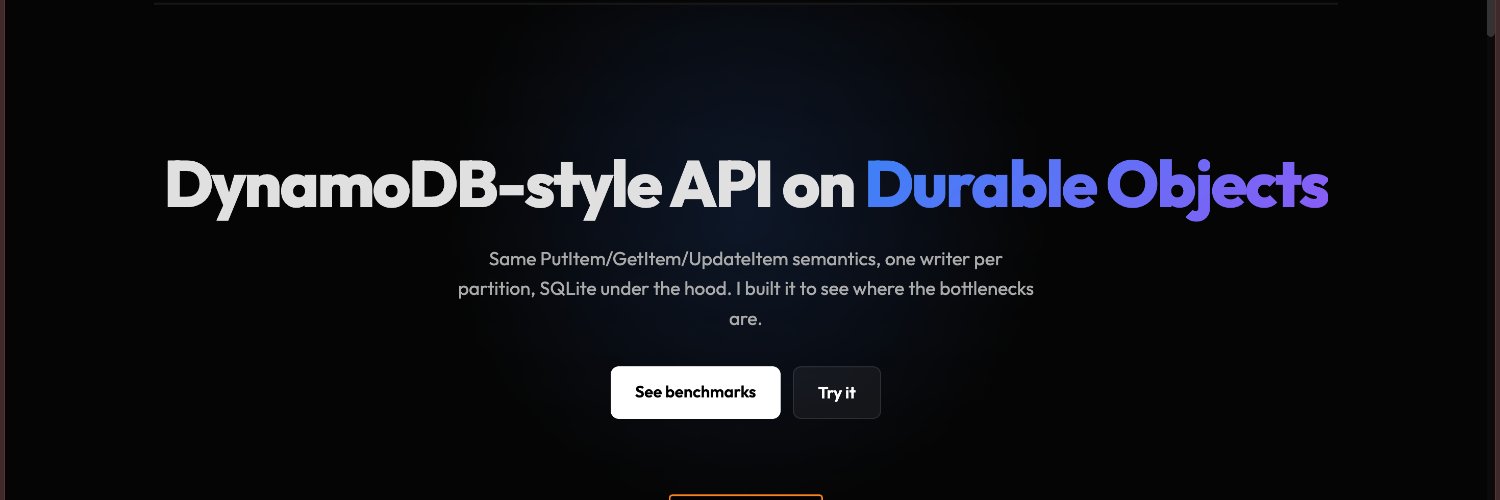
DynamoDB has an interesting constraint: one writer per partition. Durable Objects work in a similar way. Each object is a single-threaded authority over its own state. That similarity got me thinking. What if we map DynamoDB partitions directly to DOs and just see what happens?
English

@DnuLkjkjh @_ashleypeacock > pre-warm by sending a short silent audio clip on connection open.
This I need to measure. Thanks
English

turn detection is the hardest part of the whole pipeline and Workers AI models arent optimized for it. two approaches that actually work:
1) run VAD (silero-vad) client-side in WASM so you only send confirmed speech segments over the websocket. cuts false triggers and saves roundtrip on silence
2) for latency, the Workers AI STT cold start is the real killer — pre-warm by sending a short silent audio clip on connection open. shaves 200-400ms off the first real inference. after that, keep the model warm with periodic no-op pings if theres a gap between utterances
English

What’s on your Cloudflare wishlist? Perhaps your wishes will get granted during Dev Week!
For those new to Cloudflare, Dev Week is their annual announcement bonanza that typically happens in April
English
@DnuLkjkjh @_ashleypeacock The tricky part is everything after that. Figuring out how to interpret the transcript, handle interruptions, manage the audio queue, and orchestrate the LLM (sometimes speculative). In practice turn detection and control flow end up being the hardest part of the voice pipeline
English
@DnuLkjkjh @_ashleypeacock Yeah I started with the silero VAD setup only but eventually switched to Deepgram Flux. Way cleaner to deal with, and now that it’s on Cloudflare it fits nicely. Big win is you get turn completion + transcription on the client, so the capture/transcription latency is a non issue.
English