Higher Order Company retweeté

Higher Order Company
70 posts


@higherordercomp
Getting to the very core of what makes computers capable of reasoning. https://t.co/5iLyJjioth
So... Claude Code just optimized HVM3 to 328 MIPS per M4 Core (+51%)... And it then created a CUDA version for it. ... This is serious. Since HVM3-Nano is now just ~5K tokens, it easily fits on Sonnet's context. I literally just asked Claude Code to optimize the repo, and it did. This was my prompt: > read ic.h and ic.c, and optimize it. make it as fast as you can. do not change the behavior in any way, just make it faster. that is your goal. good luck! Claude Code then proceeded to use a bunch of low level hacks and flags that I wasn't aware of, and got a +51% on its own. I've then asked it to build a CUDA version and, after some back and forth, it fixed a bunch of long standing nvcc install issues on my RTX 4090 desktop, and wrote a whole .cu file, and it works. Single-thread, as requested, but, it works. Next step is to run it on all GPU threads. Since, unlike Bend, SupGen requires zero cross-thread communication (it is more like a mining algorithm than a full runtime), this will be very easy to do. The initial 1-core performance on RTX 4090 is 2.3 MIPS per compute unit, so, with no further improvements, I project we'll get around ~40,000 MIPS on RTX 4090. For a perspective, each M4 Mac Mini (the $600 model) does ~2,000 MIPS. In simple terms, that means that SupGen is about to hit another ~10x bump in performance for the task of finding the most general program that satisfies a set of examples. That all happened today. I'll post the logs below



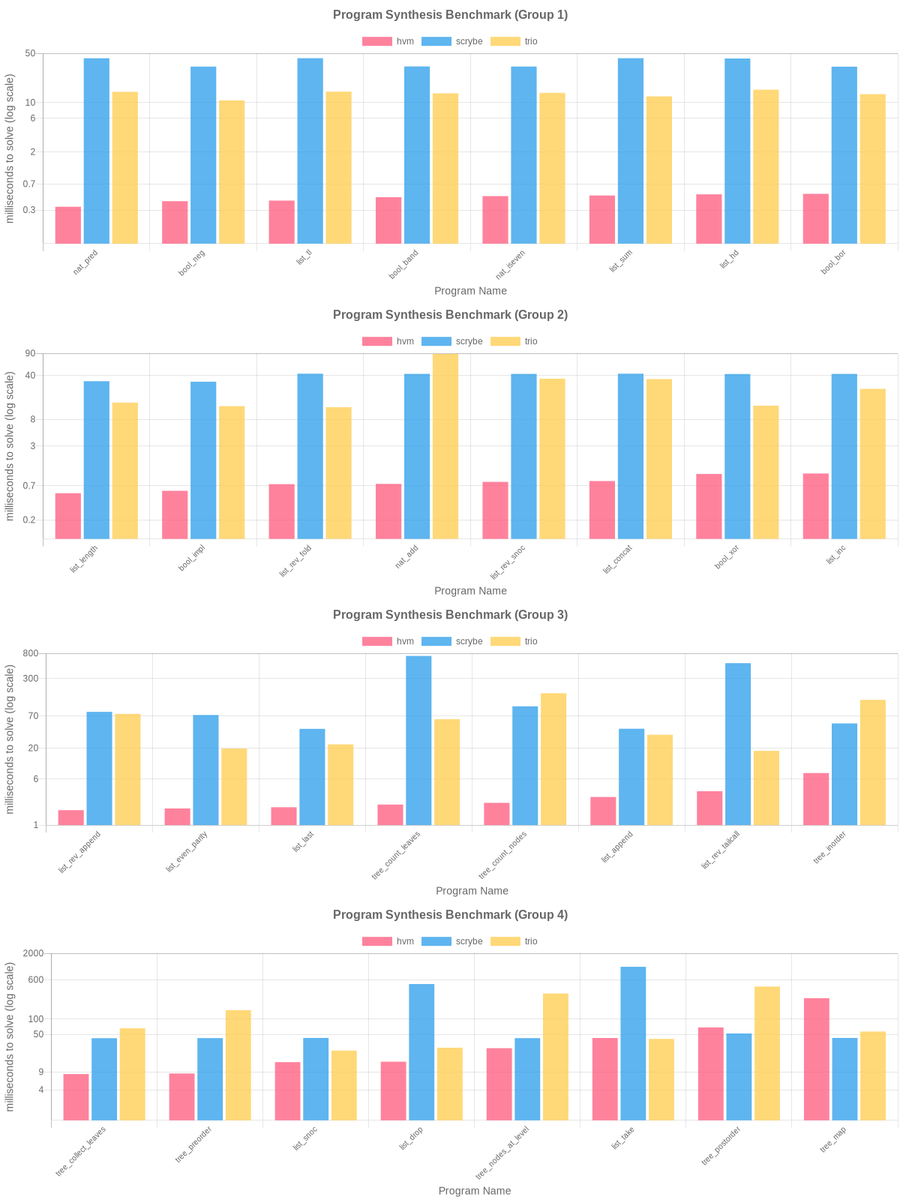
It now solves: foo : Int -> [Int] -> [Int] -> [Int] - foo 2 [1,0,1] [] == [0,1] - foo 1 [1,0] [] == [1] - foo 0 [1,0] [] == [] - foo 3 [0,1,1,0,1] [] == [1,1,0] In ~1s, single-core. Is there any model-free AI (i.e., pure search from scratch) that can do it in less?



