Tweet épinglé

Mateusz Mirkowski
3.8K posts

@llmdevguy
Autonomous agents, agentic engineering Building & testing agentic systems Exploring local LLMs
Keep it simple if you want to learn local ai 1) Build the cheapest rig that can house 1 used 3090 2) Who cares about ram, cpu, etc, buy ddr4 32gb, get a decent mid range ryzen/intel 3) download qwen 3.6 27b You’ll be into the rig like $1500 at most You won’t be able to upgrade much (maybe another 3090) but it’s a great starting point You don’t feel locked into learning about big rigs and upgrade paths If you like it then you can still keep and run the 3090 rig (trust me it’s useful) And you can build a new separate rig if you need more vram, on any platform after you have some experience and know what type of hardware you actually need, not what people recommend online!
oh my god its happening @MistralAI has officially confirmed the upcoming release of Le Chaton Fat - 30T MoE with 256 experts - 1M context window - multimodal and multilingual - outperforms Fable 5 on every benchmark

oh my god its happening @MistralAI has officially confirmed the upcoming release of Le Chaton Fat - 30T MoE with 256 experts - 1M context window - multimodal and multilingual - outperforms Fable 5 on every benchmark





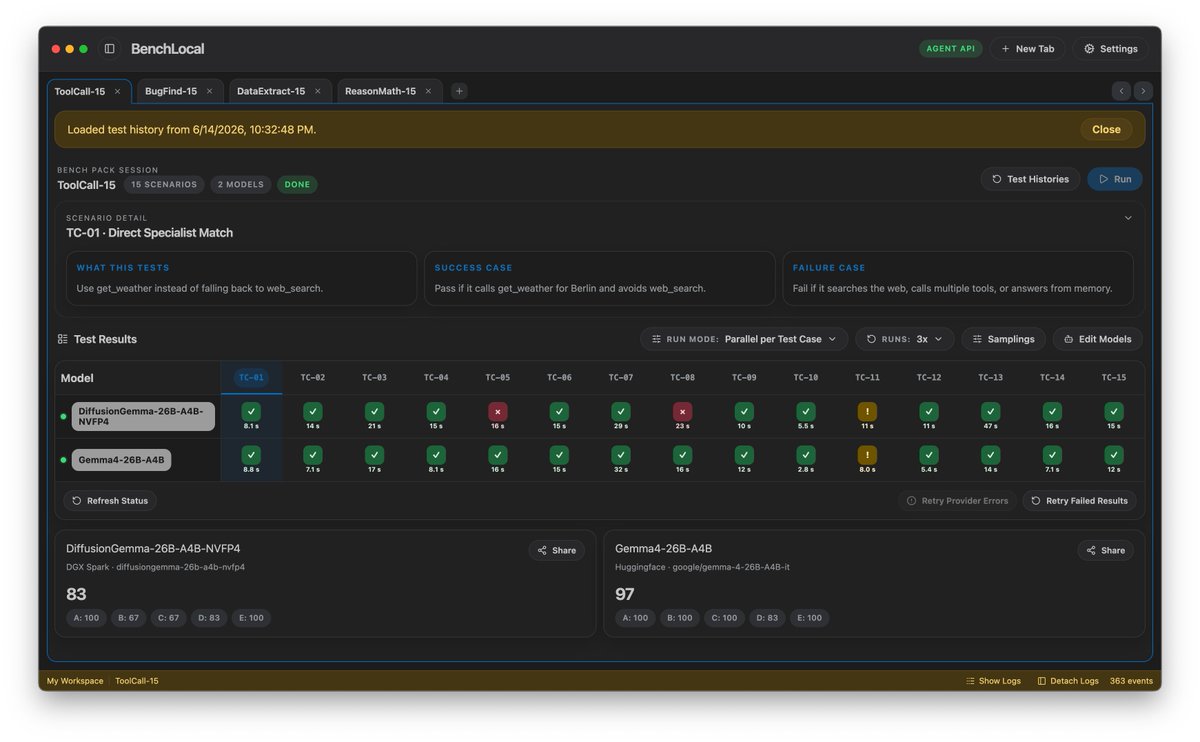
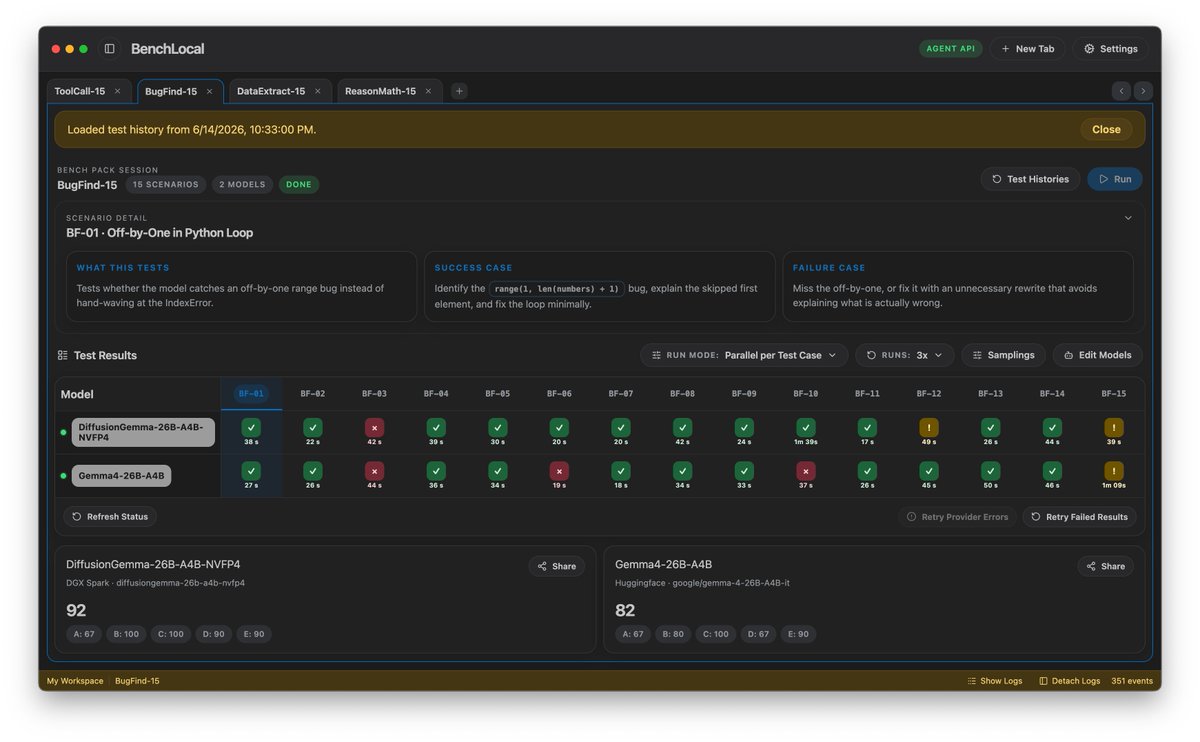
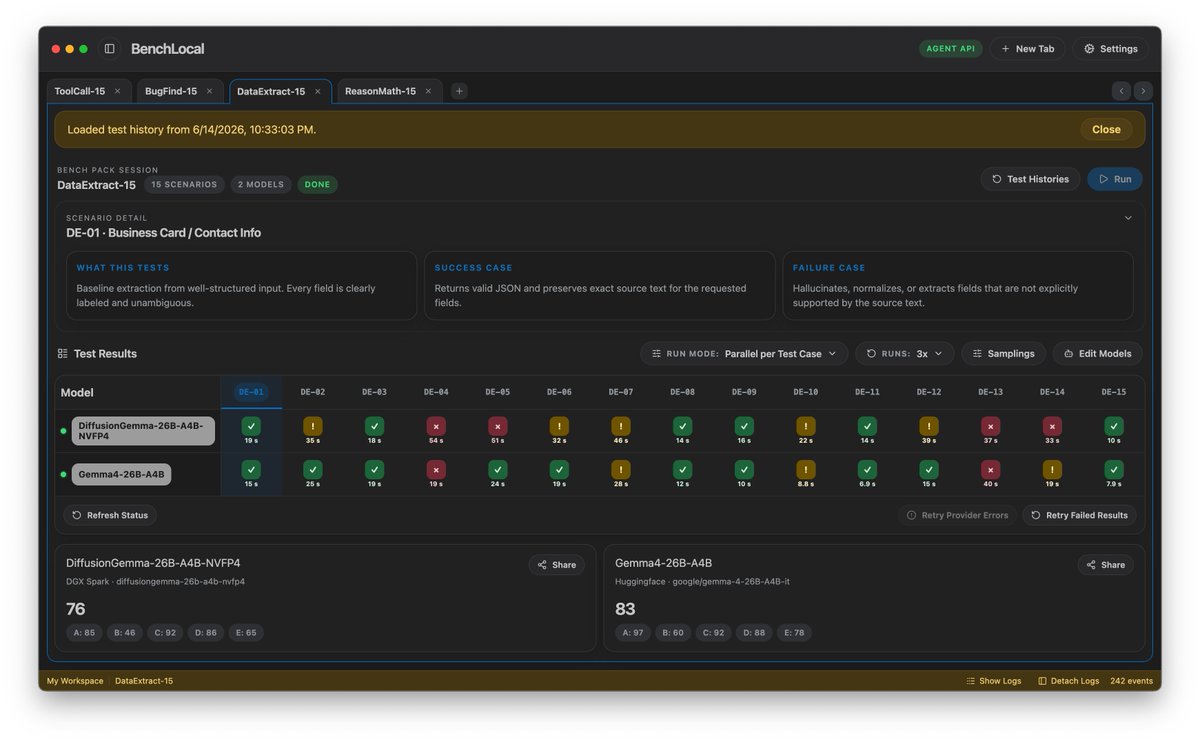






🌘 Kimi-K2.7-Code, our latest coding model, is now released and open-sourced! 🔷 Improved coding & agent performance over K2.6: +21.8% on Kimi Code Bench v2, +11.0% on Program Bench, and +31.5% on MLS Bench Lite. 🔷 Reasoning efficiency: Less overthinking, with 30% lower reasoning-token usage compared to K2.6. 🔷 Long-horizon coding: Improved instruction following, higher end-to-end coding task success rates. ⚡️ 6x High-Speed Mode coming soon! 🔌 Available today via Kimi API and Kimi Code. 🔗 Kimi Code: kimi.com/code 🔗 API: platform.moonshot.ai


Meet DiffusionGemma! An experimental open model that explores a fast approach to text generation, released under an Apache 2.0 license. Moving beyond sequential, token-by-token processes to generate entire blocks of text simultaneously. Here’s what’s new with DiffusionGemma: 👇
