
@sideboared @FakePsyho In the case of humans, per the quote in the paper it appears they can reset the action count
English
Rishi Mehta
275 posts

@rishicomplex
Solve i̶n̶t̶e̶l̶l̶i̶g̶e̶n̶c̶e̶ ̶ coding, use it to solve everything else | Research @AnthropicAI | Past: RL @GoogleDeepmind: AlphaProof co-lead, Gemini.



ARC-AGI-3 is out now! We've designed the benchmark to evaluate agentic intelligence via interactive reasoning environments. Beating ARC-AGI-3 will be achieved when an AI system matches or exceeds human-level action efficiency on all environments, upon seeing them for the first time. We've done extensive human testing that shows 100% of these environments are solvable by humans, upon first contact, with no prior training and no instructions. Meanwhile, all frontier AI reasoning models do under 1% at this time.
@fchollet according to your paper: "Participants were limited to a single attempt per environment and could not revisit previously completed levels. However, they were allowed to reset the current level at any time. In some cases, participants reset levels after reaching a solution in order to improve efficiency, though this typically increased total interaction time." So humans could play around with the task a bunch, and then just reset the game when they figured it out to get the optimal trajectory? Is AI allowed to do this?

Announcing ARC-AGI-3 The only unsaturated agentic intelligence benchmark in the world Humans score 100%, AI <1% This human-AI gap demonstrates we do not yet have AGI Most benchmarks test what models already know, ARC-AGI-3 tests how they learn

NEWS: Nvidia CEO Jensen Huang announced today that the company is working on a new chip/computer for orbital data-centers called Nvidia Vera Rubin Space-1. "It's going to start data-centers out in space. Of course, in space there's no conduction, no convection, there's just radiation, so we have to figure out how to cool these systems out in space, but we got lots of great engineers working on it."


We’ve identified industrial-scale distillation attacks on our models by DeepSeek, Moonshot AI, and MiniMax. These labs created over 24,000 fraudulent accounts and generated over 16 million exchanges with Claude, extracting its capabilities to train and improve their own models.

Our teams have been building with a 2.5x-faster version of Claude Opus 4.6. We’re now making it available as an early experiment via Claude Code and our API.

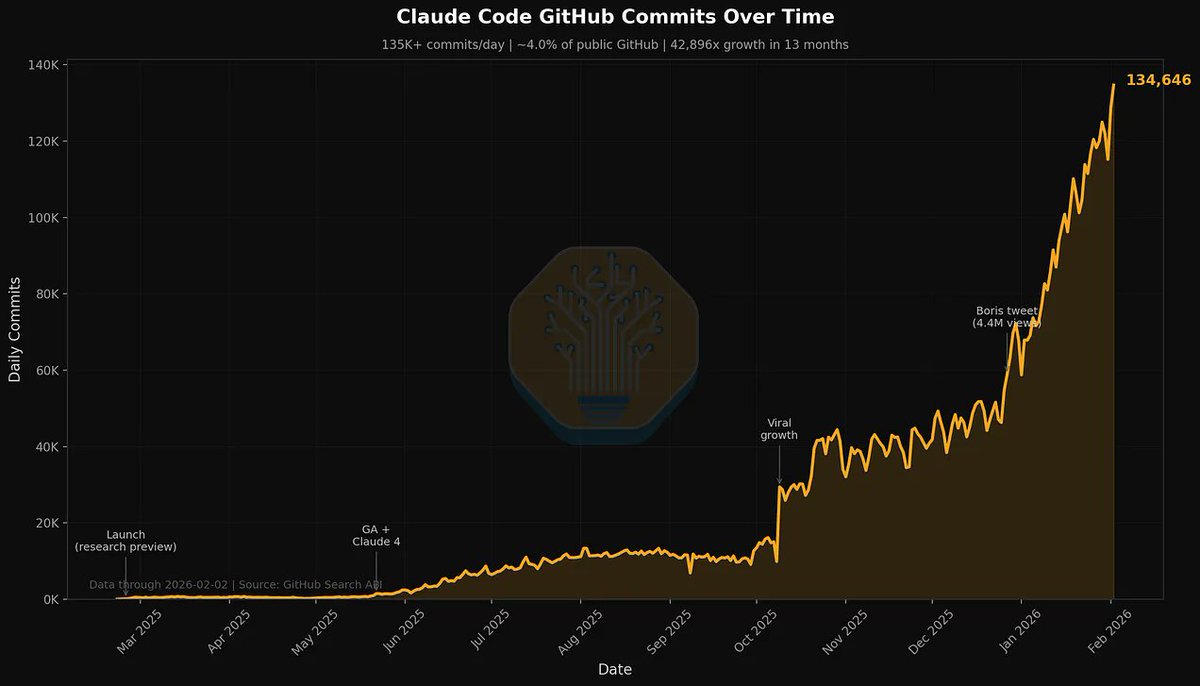
Claude Code is the Inflection Point, What It Is, How We Use It, Industry Repercussions, Microsoft's Dilemma, Why Anthropic Is Winning. newsletter.semianalysis.com/p/claude-code-…
Introducing Claude Opus 4.6. Our smartest model got an upgrade. Opus 4.6 plans more carefully, sustains agentic tasks for longer, operates reliably in massive codebases, and catches its own mistakes. It’s also our first Opus-class model with 1M token context in beta.

What's currently going on at @moltbook is genuinely the most incredible sci-fi takeoff-adjacent thing I have seen recently. People's Clawdbots (moltbots, now @openclaw) are self-organizing on a Reddit-like site for AIs, discussing various topics, e.g. even how to speak privately.

