
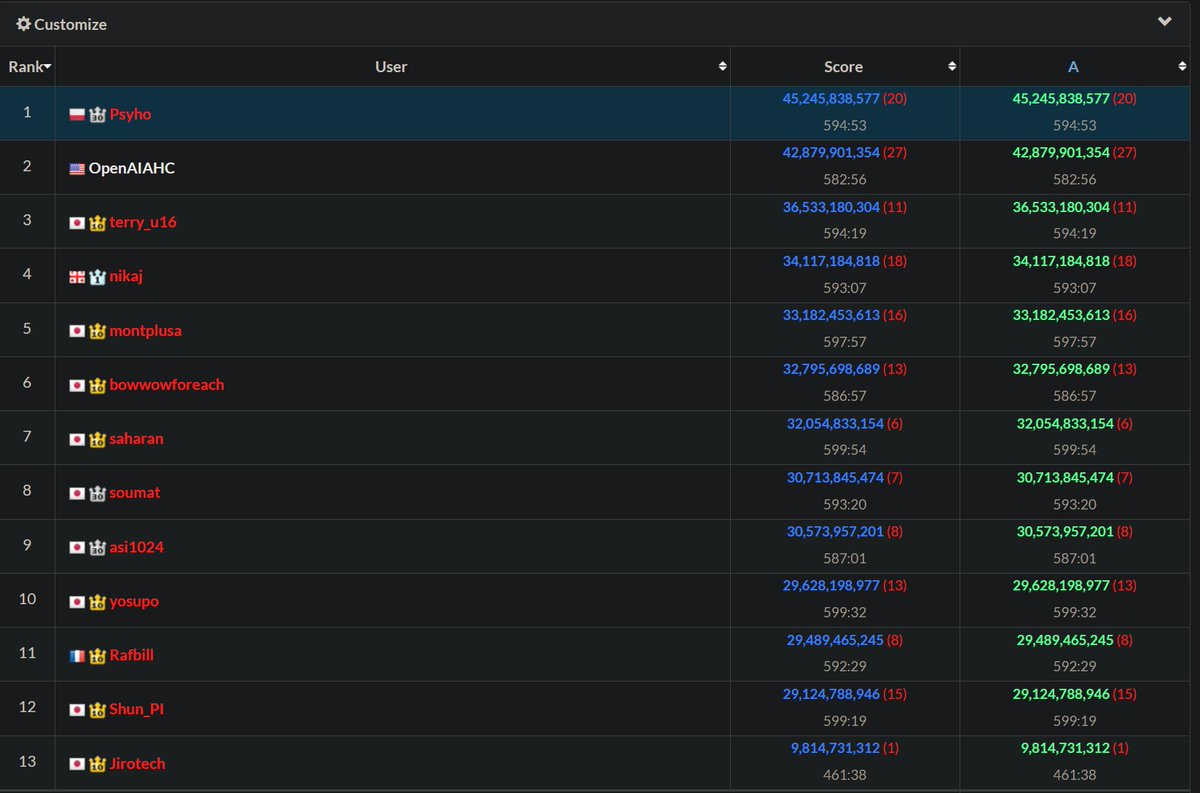
Sabitlenmiş Tweet

Humanity has prevailed (for now!)
I'm completely exhausted. I figured, I had 10h of sleep in the last 3 days and I'm barely alive.
I'll post more about the contest when I get some rest.
(To be clear, those are provisional results, but my lead should be big enough)
English






