@FUCORY@agenticklabs This looks really cool. I’m not very familiar with JJ but from what I understand of it this approach makes a lot of sense. Agents are run with ai-sdk under the hood, yeah?
@sameandnot@agenticklabs Very cool! I'm building jjhub.tech to try to get this type of orchestration running in easy to manage containers in an alternative github. If we got similar interests might be an opportunity to collaborate
It sounds so gimmicky
AI Orchestration framework via React
But hear me out, Smithers is secretly the best-in-class agentic orchestration framework
In this 🧵 I answer two questions
1. Why you even need an orchestration framework?
2. Why that orchestration framework should be smithers
🧵 1/18
@FUCORY@agenticklabs I did… Smithers likewise looks very cool! And I love the name. :) When I said “should have” what I really meant was “wish you had”! It’s exactly the kind of higher order system I built agentick to be able to support.
I am using it to build github.com/agenticklabs/t…
WIP
@sameandnot@agenticklabs Looks cool! I think smithers is a bit of a higher level of abstraction than this. This looks useful for managing context windows at a low granular precise level and likely would work with smithers with minimal effort
Did you build it?
Opus 4.6 is literally broken right now. Examples:
- Ask to re-run pass@3, it proceed to run pass@1.
- Ask to check recent commits, missed the most recent commit.
- Ask why it did something, it apologizes and executes commands instead of just giving an answer.
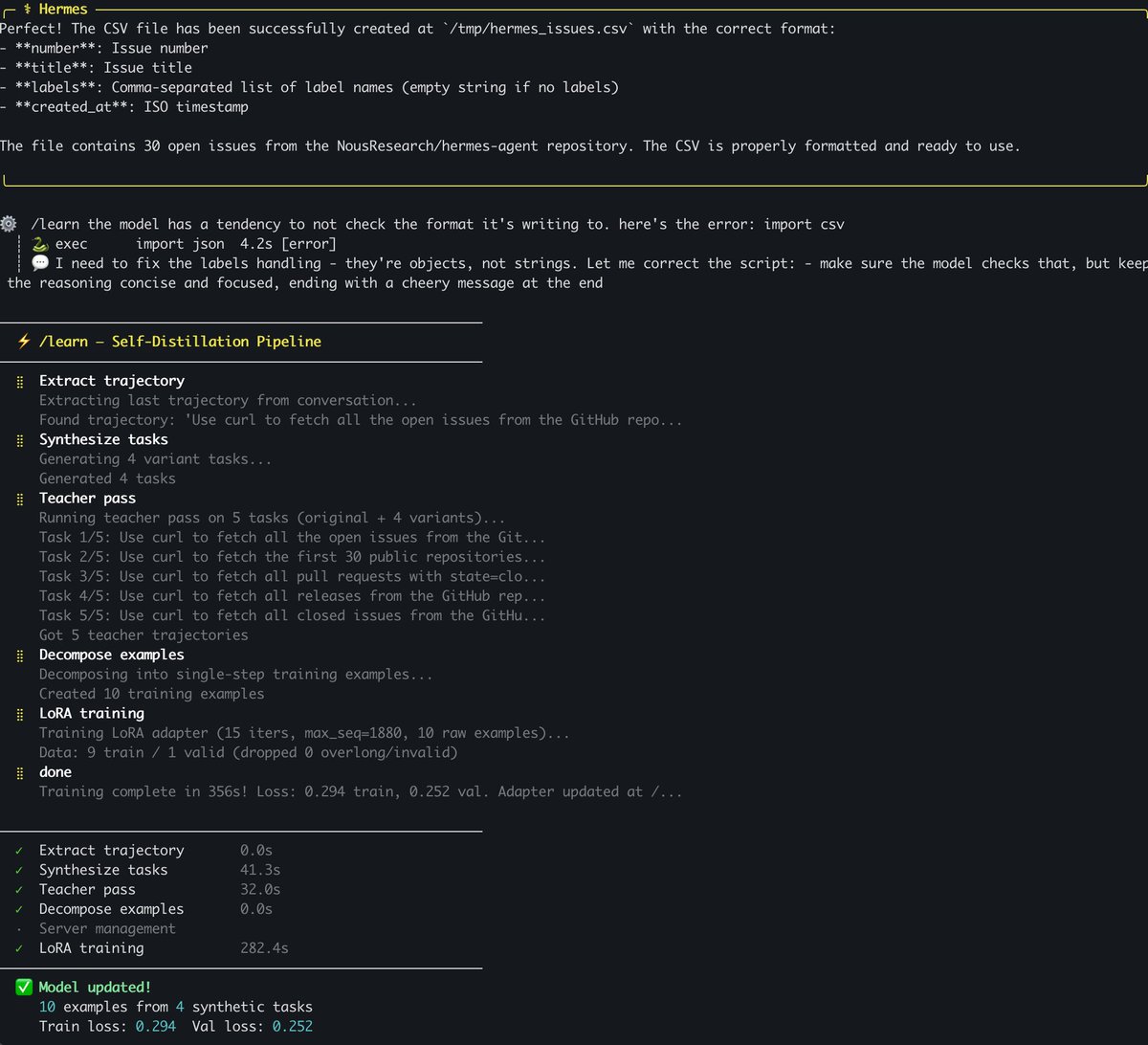
Just a little recursive self improvement command I added to Hermes-Agent. Easy /learn command that generates a few synthetic examples and updates a LoRA on Qwen-3.5 9b on MLX. I don't merge it, just keep updating the adaptor checkpoint
Might tidy it up later if anyone is interested, I want to see if I can bring memory usage further down though first & tighten up the trainer & inference more, maybe make a proper LoRA library. Maybe add a lightweight GRPO variant too. Need to get the vram usage on activations down too, as the headroom on the bigger models (27b & 35b-a3b MoE) is reallly tight on longer sequences.
Works though! 9b is now more careful & doesn't make that particular error anymore. As a supplement to skills & memory it'll be a handy little thing to have (if you're a local models maxi with a mac)
Something I haven’t seen discussed…
If coding with agents is the future, it creates inequity with developing countries where the devs can’t afford subscriptions. How will those economics play out?
@0xPaulius Hmm are you using Opus on high effort? We started defaulting Opus to medium this week, you should have seen a little notification when you start your CLI
"THE UNITED STATES OF AMERICA WILL NEVER ALLOW A RADICAL LEFT, WOKE COMPANY TO DICTATE HOW OUR GREAT MILITARY FIGHTS AND WINS WARS! That decision belongs to YOUR COMMANDER-IN-CHIEF, and the tremendous leaders I appoint to run our Military.
The Leftwing nut jobs at Anthropic have made a DISASTROUS MISTAKE..." - President Donald J. Trump
We've reset rate limits for all Claude Code users.
Yesterday we rolled out a bug with prompt caching that caused usage limits to be consumed faster than normal. This is hotfixed in 2.1.62.
Make sure you upgrade to the latest and hope you enjoy using Claude Code this weekend!
i must say, knowing how to do all the things really makes vibe coding a stupid project fun because i can do something that i would normally say no to (due to time)
but on the other side, like all projects, even vibe coding something becomes a bigger and bigger time sync to where it just becomes another over scoped and under delivered project
its almost like the speed change did not impact the amount of actually finished projects ;)