
Telan
30 posts


风闻消息,部分地区受影响,受影响的可以底下留言,也别说谣言不谣言的,没意义
大量用户在社交媒体中表示,目前中国三大运营商对于海外方向连接情况出现明显异常。
中国电信联通往香港、日本方向的回程路由受到明显影响,包括 CN2、9929 在内的高级路由以及 163、4837 标准路由均受到此影响,用户报告出现大范围丢包与连接中断现象。亦有少量用户报告,往美国方向路由也被干扰,但是样本量低且集中在部分服务商。
同时,中国移动手机流量往海外方向出现严重丢包、链接被中断现象,大量用户表示此问题严重影响使用,尤其集中在北京移动用户报告。
目前尚不可知是突发国际路由故障还是运营商主动调整策略,期待大家在评论区反馈您所在地区运营商是否遇到此类问题(请注意隐私保护)。
中文











🎃万圣夜的23:59分,千万不要打开 #币安... 原因就在视频中!
Trick or Treat今天帕鲁绝对不cos小气鬼👻
来评论选一个数字,选中幸运数字就领糖🍬
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
中文


是这样的,来我司是我第一次接触 Next.js,被开发时的按需渲染导致的卡顿给惊到了,果断在司内的新开项目用了 vanilla React + react-router,瞬间世界清爽了
空谷 Arvin Xu@arvin17x
大家一直吐槽 LobeChat 切换慢,卡顿,之前我一直觉得是我们 next 的用法不对,所以一直在尝试各种写法,从 RSC、平行路由、拦截路由,一直到动静态渲染、路由段重写等等方案。 2 年时间硬生生从 next 小白变成了 next 专家,但还是没有效解决页面切换卡顿的问题。而最近把两个路由段(discover 和 settings)换成了 react-router ,做了 SPA 改造,瞬间不卡了😅 所以 2.0 准备全量改造成 SPA 了 现在回过头来看就是陪 Next 踩了两年 RSC 的坑 😌 paperclover.net/blog/webdev/on…
中文
Telan retweeté

前段时间密集讨论了淘宝(阿里)和B站,后来又在行业群里引发了一个新的话题:平台是否有必要让供给方具有全栈能力?
比如淘宝的发展就是这样的,商家不但需要做好本职的卖货工作,还得懂流量、懂运营、懂投放、懂转化,否则你在淘宝的游戏规则里就会吃大亏。
所以中后期的阿里生态里涌现出大量的TP(代运营公司),就是为了解决商家全栈能力不足的问题,不是每个卖拖鞋卖水壶的商家都有这么旺盛的学习能力,所以只能委托分工体系,让TP大行其道。
但是TP也是有成本的,成本被层层转嫁的结果,最后就是消费者来买单,从结构上来说也很奇怪,你只是想买一双拖鞋,但实际上你的消费里还包括了给TP发的工资。
拼多多的竞价逻辑是倒过来的,商家出底价,然后拼多多选出价格最低的那个,告诉说你啥都不用管,专心发货就行,流量什么的都由我来解决。
拼多多这么做肯定也会有它的问题,比如商家感到被压榨,或是商品品质出现劣币驱良币的现象,但它在回归商业效率这件事情上,是符合消费者利益的,否则也不会短短几年时间长到如此体量。
(不会真的有人以为拼多多是靠补贴增长到如今让阿里寝食难安的吧?不会吧?)
B站和YouTube也有类似的逻辑对比,B站一直在试图劝说UP主,激励计划救急不救穷,真正能让你们过上好日子的,一定是自己去开拓市场接商单。
但这也意味着UP主需要具备的全栈能力,你不光要会做视频,还得横向兼任乙方的职能,知道怎么八面玲珑的把自己卖出去,大的UP主还能养一支商务团队,腰部以及以下的就完全没辙了,所以B站的商单分发非常极端,位于吃肉阶层的UP主强势得不行,喝汤阶层的UP主实际上连汤都没得喝。
YouTube的贴片模式就和拼多多搞逆向竞价是一个道理,你们随便做视频,不需要考虑别的,流量就有广告,账单都是透明的,创作者只需要考虑怎么吸引更多的人点击。
所以你要说YouTube的平均内容质量特别高,也未必见得,尤其是中文内容更是泥沙俱下,为什么盛行听床政治,还不是因为吸引眼球,点进来的人多就来钱快啊,很多在YouTube做严肃内容的也觉得不爽。
但一个是面包多和面包少的矛盾,一个是有面包还是没有面包的矛盾,主次分明,冷暖自知。
杰克马在推新零售的时候做过一个预判,大致意思是电商已经走到了终局,以后的增长只会越来越发力,所以阿里那时四面出击收购卖场,因为线下流量已经比线上流量便宜了。
马总英明一世,却想不到线上流量之所以这么贵,大半原因还不都要归功于他,淘宝和天猫的交易成本那么高,所以适者生存的只有利润足够高的商品,才付得起中间的利差,互联网公司打了一辈子效率革命的仗,到了真的成为既得利益者的时候,也就活成了效率的敌人,屠龙者成为巨龙的诱惑是如此之大,以致于凡夫俗子无一可以幸免。
我之前也打过一个比方,说2022年以来的小红书,就和2019年的B站是一样的,什么意思呢,就是假如2019年有外星人侵略地球,很不凑巧的把包括叔叔在内的所有B站员工都劫持到了飞船上作为人质,从此杳无音信,同时只要B站的服务器还在正常运行,那么到了年底,它的所有流量数据都还会是高速增长的。
所有踩在时代脉搏上的公司还是要慎言终局,宝剑入水猿声远,轻舟已过万重山,任何成功经验都是暂时的。
这几天翻看「芒格之道」,收录的都是几十年前的文本,跨越代际的阅读体验非常有意思,可以非常明晰的看到在时间的冲刷下什么算得上是聪明,什么又有资格被称作是智慧。
芒格说他和巴菲特光是了解眼前的情况就已经费尽心力了,跟本没有余力去做长期规划,很多人以为伯克希尔·哈撒韦是遵循了什么宏伟蓝图才能实现如此长时间的复利的,其实根本没有这玩意儿,不是不想,是做不到,但是只要正确的做好眼前的每一件事,从长远来看,你就不至于错得太过离谱。
「我们唯一做的长期准备,是尽可能的保守,防范大灾难的冲击。我们为可能出现的最恶劣的环境做好准备。长期以来,我们的资产负债表始终非常保守。」
这恰好是一直在赢的人会非常不屑的事情。
中文
Telan retweeté

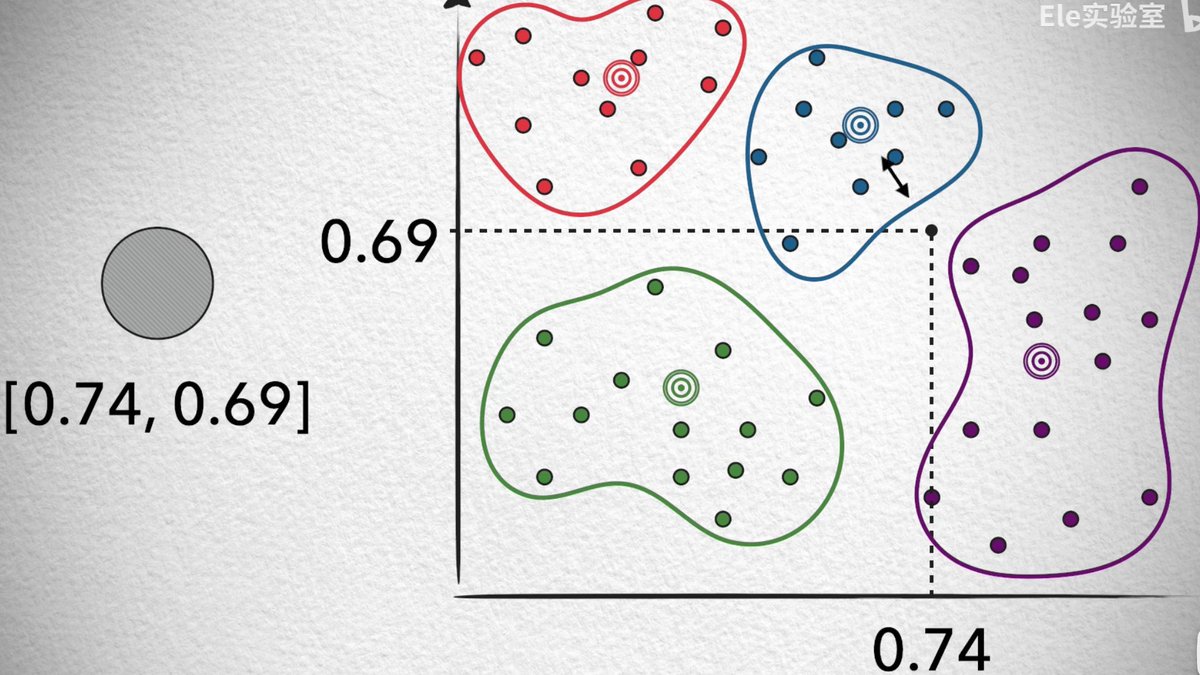
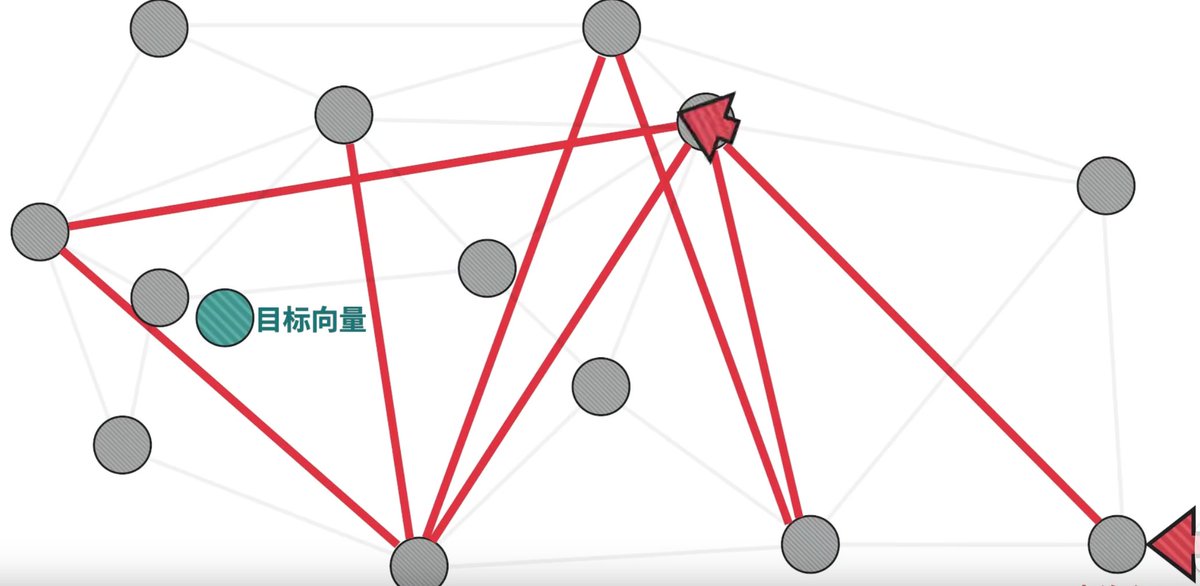
昨天晚上刷 B 站的时候,看到一个讲解向量数据库讲的非常好的 Up 主叫 Ele实验室。
从特征到向量,再到分类和搜索算法娓娓道来。
向量数据库这个技术确实需要视频才能更好理解,超级无敌推荐👍
上集:bilibili.com/video/BV11a4y1…
下集:bilibili.com/video/BV1BM4y1…


中文
Telan retweeté

熟悉Prompt的同学们应该都知道,通常在写Prompt的时候要先设定角色:“你是XX方面的专家”,这并非玄学,而是有科学根据的。
GPT在训练的时候,有各种训练数据,有的质量高有的质量低,而默认情况下,生成高质量数据和低质量数据的概率差不多,但是当你给它设定XX专家的角色时,它会尽可能把概率分布在高质量的解决方案上。
详细内容建议看下面这段Andrej Karpathy在State of GPT中的一段演讲。
以下是这段视频的文字文字内容:
----------
下面我要讲的这点对LLM的理解非常有趣,我觉得这算是LLM的一种心理特性:LLM并不追求成功,而是追求模仿。你希望它成功,那就需要向它明确要求。这里的意思是,在训练Transformer的过程中,它们有各种训练集,而这些训练数据中可能涵盖了各种不同质量的表现。比如,可能有一个关于物理问题的提示,然后可能有学生的解答完全错误,但也可能有专家的答案完全正确。尽管Transformer可以识别出低质量的解决方案和高质量的解决方案,但默认情况下,它们只会模仿所有的数据,因为它们仅仅是基于语言模型进行训练的。
在实际测试中,你其实需要明确要求它表现得好。在这篇论文的实验中,他们尝试了各种提示。例如,“让我们逐步思考”这种提示就很有效,因为它把推理过程分散到了许多记号上。但效果更好的是这样的提示:“让我们以一步一步的方式解决问题,以确保我们得到正确的答案。” 这就好像是在引导Transformer去得出正确的答案,这会使Transformer的表现更好,因为此时Transformer不再需要把它的概率质量分散到低质量的解决方案上,尽管这听起来很荒谬。
基本上,你可以自由地要求一个高质量的解决方案。比如,你可以告诉它,“你是这个话题的领先专家。假装你的智商是120。” 但不要尝试要求太高的智商,因为如果你要求智商400,可能就超出了数据分布的范围,更糟糕的是,你可能落入了类似科幻内容的数据分布,它可能会开始展现一些科幻的,或者说角色扮演类的东西。所以,你需要找到适合的智商要求。我想这可能是一个U型曲线的关系。
中文
Telan retweeté
是时候公布这道题的答案了。正好分享一下我最近学习Prompt的一点心得:给GPTs时间思考。
这是OpenAI官方公布《GPT最佳实践》的一个章节“Give GPTs time to "think"”:platform.openai.com/docs/guides/gp… 。道理很简单,就是CoT(Chain of Though)那一套,不直接给答案,而是“思考”中间过程。
但是实践中,我就发现哪怕Prompt里面哪怕我给出了详细的Steps,但是给出最终结果的时候仍然效果不是太理想。后来学习Isa和吴恩达的课程《使用ChatGPT API构建系统》的“输入处理: 思考链推理”这一课时 youtu.be/ExcjE_5un28?t=… ,看到Isa给出的示例里面,实际上将每一步的结果都让GPT输出了,于是我对比了不输出每一步结果和输出每一步结果,效果明显不一样,具体可以参考我这条推文:x.com/dotey/status/1…
这说明,要想让GPT有时间思考,得加钱!也就是消耗更多Tokens,借助输出每一步的中间结果,让GPT慢下来,并且可以将每一步的输出作为下一步的输入。
但这样输出的很多结果是没有用的,所以我们可以要求GPT输出特定的格式,这样我们可以对输出的内容进行解析,从而去掉不需要的中间结果。就像Isa的课上,就用的四个#来分隔每一步结果以及最终结果。
在OpenAI的《GPT最佳实践》中也给出了建议:“使用内部独白或一连串的查询来隐藏模型的推理过程” platform.openai.com/docs/guides/gp…
现在让我们回到原始的问题:
> 假设我现在有两个字符串数组,一个英文的数组一个是翻译后的中文数组,但是英文数组长度是11个,中文数组只有6个(翻译时合并了),现在问题是,怎么样让LLM帮助纠正这种错误,基于英文数组内容的顺序和长度把中文数组也重新拆分组合变成11个?
这个问题来源于我用GPT翻译字幕时,通常传入的是10条,但是有时候返回的结果会少于10条,举例来说:
["JOHN EWALD: Hello, and welcome to Introduction", "to Large Language Models."] 会自作主张在翻译后合并成一条:["约翰·尤瓦尔德:你好,欢迎来到大型语言模型介绍。"],而我希望重新拆分成 ["约翰·尤瓦尔德:你好,欢迎来到", "大型语言模型介绍。"]
这个问题肯定也要借助CoT拆分成几个步骤,包含两个重要的子任务:
第一步:在中文数组里根据中文字符串去找对应的英文字符串数组。
因为中文翻译时合并了,找出原始字符串数组很重要,这一步GPT3.5能做的大差不差,但经常连数组都统计不对。
比如中文字符串是:"约翰·尤瓦尔德:你好,欢迎来到大型语言模型介绍。",现在要找到对应的英文字符串数组:["JOHN EWALD: Hello, and welcome to Introduction", "to Large Language Models."],并且计算出是2条。
第二步:根据第一步得到的结果去按照英文字符串长度拆分每一条中文字符串。
比如上面的结果,"约翰·尤瓦尔德:你好,欢迎来到大型语言模型介绍。",就应该被拆分为:["约翰·尤瓦尔德:你好,欢迎来到", "大型语言模型介绍。"]
这一步对GPT-4来说没问题,但GPT-3.5几乎做不到😄
基本上两步就足够了。顺便说一下,因为这个任务都是纯自然语言处理无法借助外部任务,所以用不上最新的Call Function接口,距离来说第一步拿到了中文字符串的原始数组,像3.5无法正确技术,可以传入一个函数来计数。
接下来的问题是:因为包含了很多中间步骤,并非直接输出一个重新整理好的数组,如何解析输出的结果?
这里有很多种做法,我是直接让GPT输出JSON格式,对于GPT-4来说,JSON输出是很基本的能力,几乎没出过错。
但是这个例子有点复杂,所以Prompt写的时候要用Few-Shot给出JSON格式的样例。这样GPT就可以按照指定的JSON格式输出结果,最后我们用程序解析这个JSON结果就可以拿到最终拆分的结果。
我们把上面的一起合并成以下Prompt(注意System Message和User Message的区分):
------------
{{#system~}}
You are a helpful assistant, I have two arrays of strings: one in Source and one in Translated.
The Translated array is a translation of the Source array, but the number of strings in each array is not the same. I need to correct this so that each string in the Source array corresponds to a string in the Translated array.
Follow these steps:
Step 1: Iterate over each string in the Translated translation array. For each Translated string, find all corresponding subset strings in the Source array. Count how many Source strings correspond to each Translated string.
Step 2: Split each Translated string according to the number of corresponding English strings. Do not add or duplicate new content.
Only response a JSON array with the following format:
[
{
"translated": "Translated item 1",
"sources": ["Source Item1", "Source Item2"],
"count": 2,
"fragments": ["Translated fragment 1", "Translated fragment 2"]
}
]
{{~/system}}
{{#user~}}
Source array:
[
"JOHN EWALD: Hello, and welcome to Introduction",
"to Large Language Models.",
"My name is John Ewald, and I'm a training developer here",
"at Google Cloud.",
"In this course, you learn to define large language",
"models, or LLMs, describe LLM use cases,",
"explain prompt tuning, and describe Google's Gen AI",
"development tools.",
"Large language models, or LLMs, are a subset of deep learning.",
"To find out more about deep learning,",
"see our Introduction to Generative AI course video."
]
Translated array:
[
"约翰·尤瓦尔德:你好,欢迎来到大型语言模型介绍。",
"我叫约翰·尤瓦尔德,在谷歌云这里是一名培训开发者。",
"在这门课程中,您将学习定义大型语言模型(LLM),描述LLM的用例,",
"解释提示调优,以及描述谷歌的Gen AI开发工具。",
"大型语言模型(LLM)是深度学习的一个子集。",
"要了解更多关于深度学习的信息,请观看我们的生成性AI课程视频。"
]
Here is the JSON string:
{{~/user}}
------------
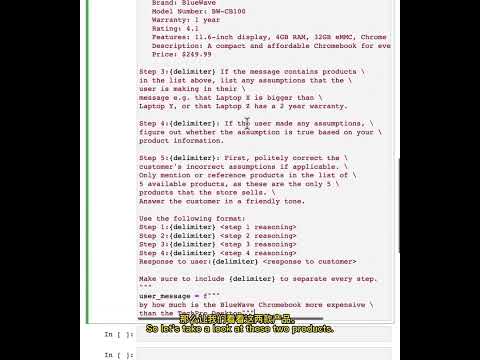
以下是我调用GPT-4得到的最终结果:
------------
{{#assistant~}}
[
{
"translated": "约翰·尤瓦尔德:你好,欢迎来到大型语言模型介绍。",
"sources": ["JOHN EWALD: Hello, and welcome to Introduction", "to Large Language Models."],
"count": 2,
"fragments": ["约翰·尤瓦尔德:你好,欢迎来到", "大型语言模型介绍。"]
},
{
"translated": "我叫约翰·尤瓦尔德,在谷歌云这里是一名培训开发者。",
"sources": ["My name is John Ewald, and I'm a training developer here", "at Google Cloud."],
"count": 2,
"fragments": ["我叫约翰·尤瓦尔德,在谷歌云这里是一名", "培训开发者。"]
},
{
"translated": "在这门课程中,您将学习定义大型语言模型(LLM),描述LLM的用例,",
"sources": ["In this course, you learn to define large language", "models, or LLMs, describe LLM use cases,"],
"count": 2,
"fragments": ["在这门课程中,您将学习定义大型语言模型(LLM),", "描述LLM的用例,"]
},
{
"translated": "解释提示调优,以及描述谷歌的Gen AI开发工具。",
"sources": ["explain prompt tuning, and describe Google's Gen AI", "development tools."],
"count": 2,
"fragments": ["解释提示调优,以及描述谷歌的", "Gen AI开发工具。"]
},
{
"translated": "大型语言模型(LLM)是深度学习的一个子集。",
"sources": ["Large language models, or LLMs, are a subset of deep learning."],
"count": 1,
"fragments": ["大型语言模型(LLM)是深度学习的一个子集。"]
},
{
"translated": "要了解更多关于深度学习的信息,请观看我们的生成性AI课程视频。",
"sources": ["To find out more about deep learning,", "see our Introduction to Generative AI course video."],
"count": 2,
"fragments": ["要了解更多关于深度学习的信息,", "请观看我们的生成性AI课程视频。"]
}
]
{{~/assistant}}
------------
完整的运行结果参考配图。
特别感谢大家的参与,特别是:@scruelt 、@PhiliMao 、 @jiangyan 、 @AstrNexus 几位同学都贡献了精彩的答案。
YouTube


宝玉@dotey
给有兴趣学Prompt的同学一个思考题:假设我现在有两个字符串数组,一个英文的数组一个是翻译后的中文数组,但是英文数组长度是11个,中文数组只有6个(翻译时合并了),现在问题是,怎么样让LLM帮助纠正这种错误,基于英文数组的内容把中文数组也变成11个? 这个问题我能用GPT-4解决,但是GPT-3.5还搞不定。过几天在这条推文下面公布我的答案,成功率相当高,但是成本也不低,像下面的输入输出一次都接近0.1美元了。 Tip:给GPT时间思考 以下为参考的示例数据: --------------- Source array: [ "JOHN EWALD: Hello, and welcome to Introduction", "to Large Language Models.", "My name is John Ewald, and I'm a training developer here", "at Google Cloud.", "In this course, you learn to define large language", "models, or LLMs, describe LLM use cases,", "explain prompt tuning, and describe Google's Gen AI", "development tools.", "Large language models, or LLMs, are a subset of deep learning.", "To find out more about deep learning,", "see our Introduction to Generative AI course video." ] Translated array: [ "约翰·尤瓦尔德:你好,欢迎来到大型语言模型介绍。", "我叫约翰·尤瓦尔德,在谷歌云这里是一名培训开发者。", "在这门课程中,您将学习定义大型语言模型(LLM),描述LLM的用例,", "解释提示调优,以及描述谷歌的Gen AI开发工具。", "大型语言模型(LLM)是深度学习的一个子集。", "要了解更多关于深度学习的信息,请观看我们的生成性AI课程视频。" ]
中文
Telan retweeté

要编写优质的prompt,从日常实践来看,用下述结构,并且提出非常具体的要求,则基本可以让LLM输出你想要的结果
✅ 角色、技能、个性
✅ 目标
✅ 具体的上下文、关键词、负面词
✅ 输入规则
✅ 输出规则
✅ 输入输出的例子
附图是两个优秀的Prompt:AutoGPT核心指令+小红书写手。都覆盖了框架的大部分


中文
Telan retweeté

Telan retweeté
Telan retweeté

#工程师工具 这个漂亮的插图网站「manypixels」功能比上次那个日本的我认为更加全面,款式更多了,一些深色背景的也比较合适使用,每一张图都做得很细腻精致。
🤖 manypixels.co/gallery


中文