Tweet épinglé

Hey, fam! I just published a blog on Medium.
@yubrajkarki528_64344/unwrapping-javascripts-gifts-a-playful-guide-to-object-destructuring-24615b92d07f" target="_blank" rel="nofollow noopener">medium.com/@yubrajkarki52…
English
Yubraj Karki
3.3K posts
@the__dev__lover
Developer | Indie Hacking & Ethical Hacking enthusiast | Sharing a thing or two and occasionally memes







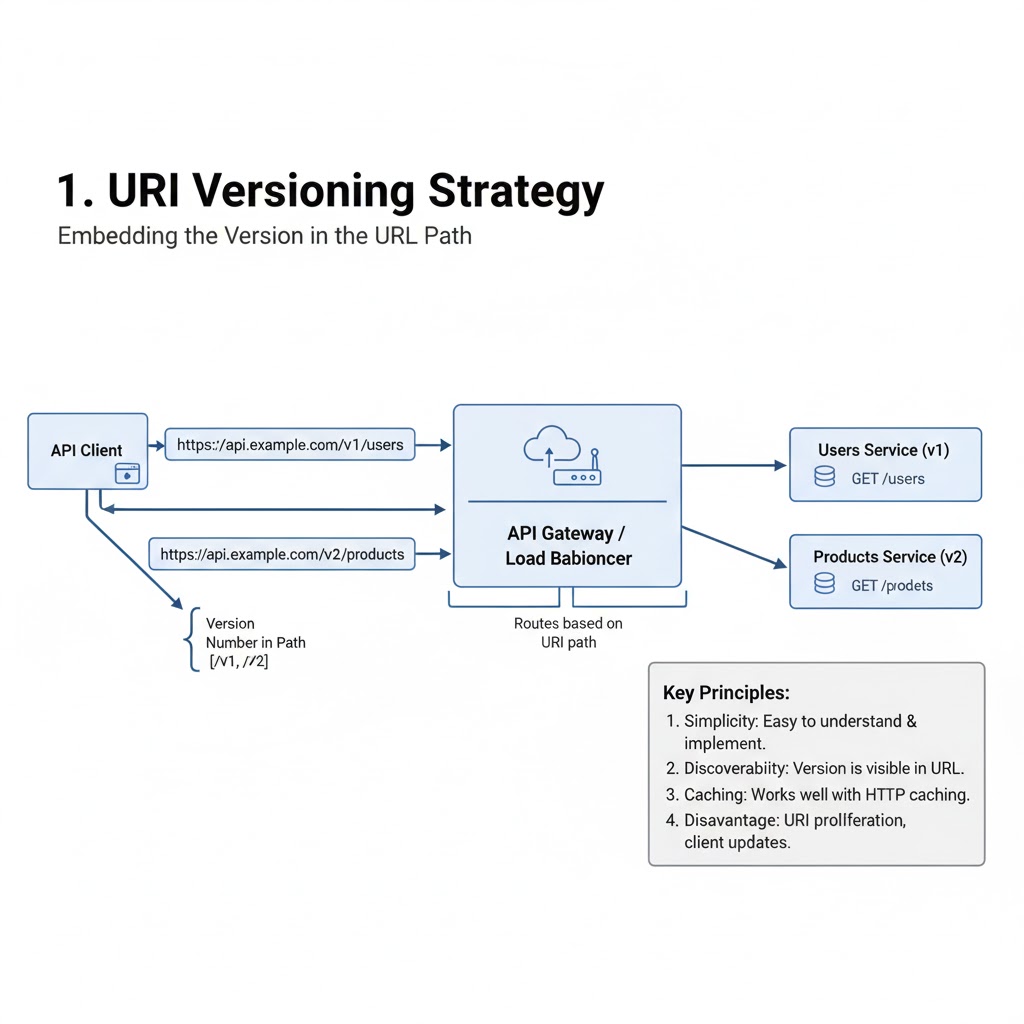
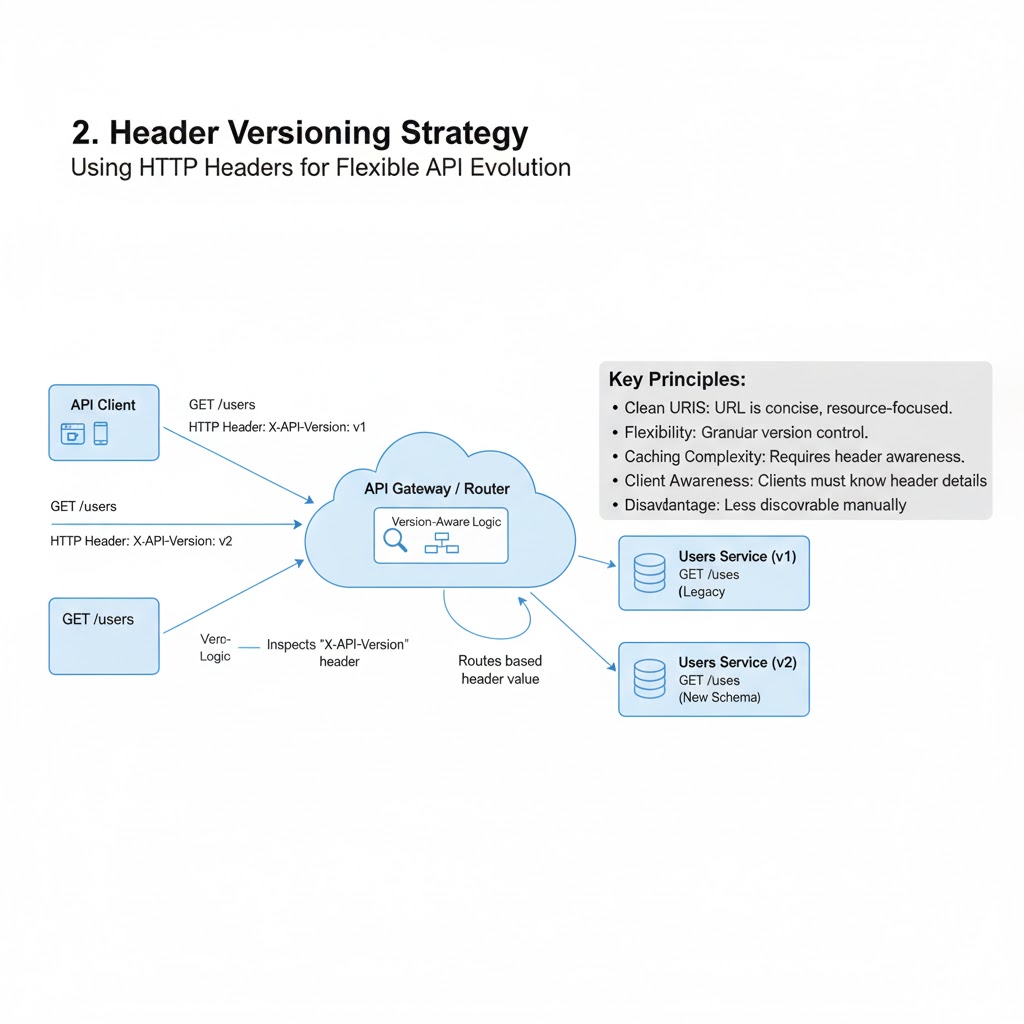
📝 Blogged: "On Idempotency Keys" Discussing several options for ensuring exactly-once processing in distributed systems using idempotency keys, from UUIDs to monotonically increasing sequences. 👉 morling.dev/blog/on-idempo…

@0xlelouch_ @grok explain what is idempotency in distributes systems and why is it important


Most people are building side projects. But what if your side project was already a real business? We spend months hacking “prototype apps”… but nothing we build ever reaches the App Store. No monetization. No users. No momentum. I thought that’s just how it works—until I found something different.






Most painful realization about yourself?

Sadly, I am a slow learner. It takes me weeks to understand something that my friends grasp in days. OTOH, once I put the effort, I "really" get it! So slow that I even realized it pretty late in life :) This realisation, and planning for it, helped me a lot!